介绍
在现代数据平台中,实时处理、灵活的数据建模以及通过开放格式实现长期可持续性变得前所未有的重要。在本文中,我将为您介绍一个我使用一组开源工具构建的开放数据湖架构,以无缝处理流式和批处理工作负载。该架构汇集了 Apache Flink、Apache Iceberg、Nessie、MinIO、dbt、Trino 和 Airflow,以创建一个端到端、可扩展且版本控制的数据基础设施。所有组件都部署在容器化环境中的 OpenShift 上。该管道首先使用 Flink 消费 RabbitMQ/Kafka 的实时事件,并将其写入由 MinIO 支持并由 Nessie 管理的 Iceberg 表中。然后,使用 dbt 对同一张表进行建模,并通过 Airflow 进行批处理。在接下来的章节中,我将详细介绍每个组件以及设计决策背后的原因。
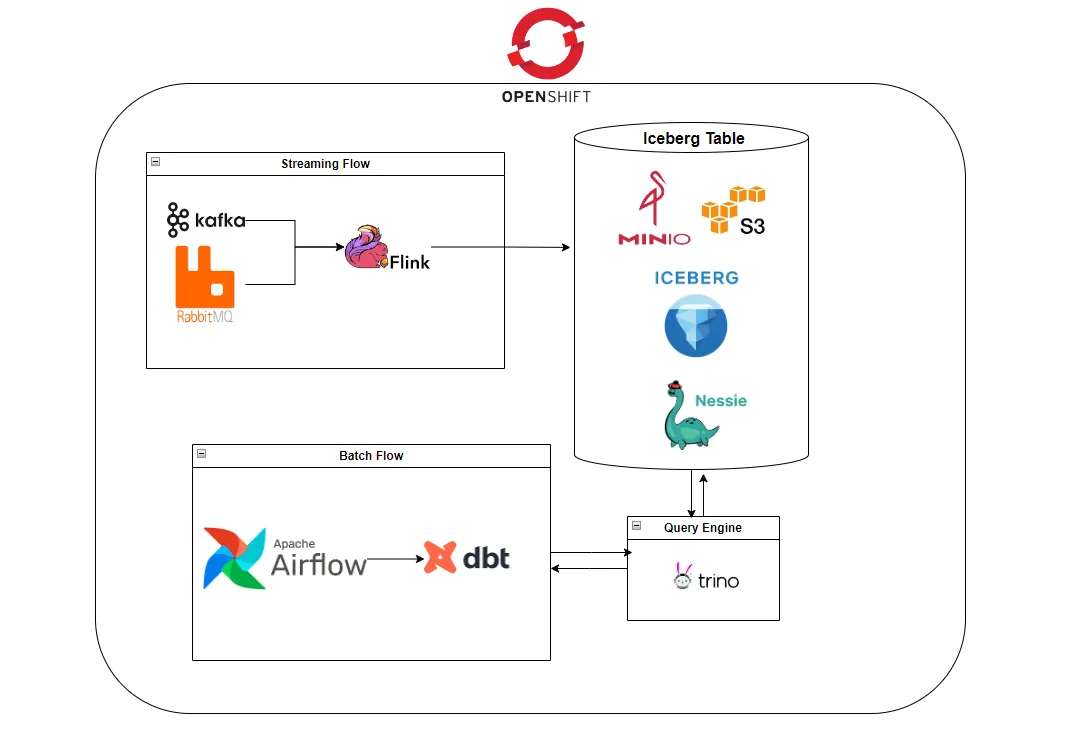
架构概述
该架构旨在以模块化和云原生的方式支持实时数据摄取和批处理。以下是组件及其交互方式的高层分解:
Apache Flink (Java): 用于实时流处理。它消费来自 RabbitMQ 或 Kafka 的消息,并使用 Flink Iceberg 连接器将它们写入 Apache Iceberg 表中。
RabbitMQ 或 Kafka: 作为消息传递主干。它向 Flink 传递实时事件数据,使系统能够对新数据做出即时反应。
Apache Iceberg: 一种现代表格式,支持模式演进、时间旅行、分区和高效查询。它被用作数据湖中的核心数据存储格式。
Project Nessie: 为 Iceberg 表提供类似 Git 的版本控制,支持在数据目录中进行分支、提交和回滚。
MinIO: 用作 Iceberg 的 S3 兼容对象存储后端。它存储实际的数据文件,并支持可扩展的云原生存储操作。
dbt: 在原始 Iceberg 表之上处理转换和建模。它将版本控制、测试和文档等软件工程实践引入数据建模。
Trino: 作为 Iceberg 的 SQL 查询引擎。它支持交互式查询并驱动 dbt 转换。Trino 还支持基于 Nessie 的目录,允许直接通过 SQL 进行分支和时间旅行。
Apache Airflow: 编排计划的批处理工作流并运行 dbt 模型。它确保下游转换的可靠执行。
OpenShift: 在容器化环境中托管和管理所有组件,实现无缝部署、扩展和监控。
这些工具共同构成了一个统一的数据平台,支持实时摄取原始事件和批处理转换建模数据——所有这些都在一个开放、灵活和可维护的生态系统中进行。
管道演练
让我们演练一下数据在系统中是如何端到端流动的——从实时摄取到计划性转换。
1.从 RabbitMQ 或 Kafka 摄取事件
该管道可以从一个持续接收实时事件消息的 RabbitMQ 队列或 Kafka 主题开始。这些消息可能源自各种来源,例如应用程序、微服务或物联网设备。每条消息都是一个代表事件或事务的小型 JSON 有效载荷。
2.使用 Apache Flink 进行流处理
一个基于 Java 的 Flink 作业部署在 OpenShift 上,配置为消费来自 RabbitMQ 队列或 Kafka 主题的消息。利用 Flink Iceberg 连接器,该作业解析传入的事件并将其直接写入 Iceberg 表。这个过程以近实时的方式发生,确保数据到达和存储之间的延迟最小化。
3.使用 Iceberg + MinIO + Nessie 进行数据湖存储
Iceberg 表由 MinIO 支持,MinIO 提供 S3 兼容的对象存储。Flink 不会直接写入 S3,而是通过 Nessie Catalog 写入 Iceberg。这为数据湖添加了类似 Git 的版本控制,支持安全的提交、分支和回滚——使您的数据生命周期像您的代码一样易于管理。
4.使用 dbt 和 Trino 进行建模
dbt 连接到 Trino,Trino 充当 Iceberg 表的查询引擎。模型以标准 SQL 编写,并使用 Trino 的原生支持具化为 Iceberg 表。
一旦原始数据在 Iceberg 中可用,dbt 接管建模和转换。dbt 项目也部署在 Minio 上,并通过 Airflow 触发。dbt 从原始 Iceberg 表中读取数据,并创建经过清理和转换的模型,这些模型更易于分析或下游应用程序消费。
5.使用 Apache Airflow 进行批处理编排
Airflow 负责调度和编排 dbt 作业。DAG(有向无环图)被定义为定期(例如,每小时、每天)运行转换。这确保了最新摄取的数据能够与业务需求同步处理和建模。
Airflow 按计划运行 dbt 命令。这些命令连接到 Trino,执行转换,并刷新模型或快照作为 Iceberg 表。
6.在 OpenShift 上的端到端
所有组件——Flink 作业、MinIO、Nessie、dbt、Trino 和 Airflow——都在 OpenShift 上部署和管理。这提供了强大的容器编排、简化的扩展以及用于监控和管理整个管道的一致平台。
这种管道设计允许实时摄取和分析,同时支持结构化、可维护和版本化的批处理——所有这些都完全建立在开源和云原生技术之上。
为什么我如此构建此架构
在设计一个现代数据平台时,我的主要目标是可扩展性、灵活性和开放性。我想避免供应商锁定,同时支持实时和批处理工作负载,并让版本控制和模式演进成为系统的首要功能。
这就是我选择每个组件的原因:
-
Apache Flink 天然适合实时流处理。它提供了精确一次(exactly-once)的语义、强大的窗口功能以及一个成熟的生态系统,可用于生产级别的流应用程序。
-
Apache Iceberg 带来了传统基于文件的湖泊所缺乏的表级控制和长期可维护性。它支持模式演进、时间旅行和 ACID 保证,这对于构建可靠的数据系统至关重要。
-
Nessie 为 Iceberg 增添了类似 Git 的版本控制功能。这使我能够为开发或测试创建隔离分支、安全地提交更改,并在出现问题时进行回滚——就像处理源代码一样。
-
MinIO 被选为 S3 兼容的对象存储,因为它轻量、易于部署,并且在 OpenShift 等容器化环境中完美运行。
-
dbt 使转换模块化、可测试和版本化。它让我在数据建模中应用了软件工程的最佳实践,从而使分析层中的协作和持续集成/持续部署(CI/CD)成为可能。
-
Trino 作为 Iceberg 之上的 SQL 查询层。它使我能够使用 ANSI SQL 查询和具化 Iceberg 表,与 dbt 无缝集成,甚至通过 Trino 目录利用 Nessie 的分支和时间旅行功能。这让分析师和数据科学家可以使用熟悉的 SQL 语法以交互方式访问湖仓一体。
-
Airflow 是编排的核心。它协调批处理作业、管理依赖关系,并提供监控和重试功能——这些都是稳定生产管道所必需的。
这种组合为我带来了两全其美的优势:具有强一致性的实时摄取和具有清晰版本控制与治理的结构化批处理——所有这些都完全建立在开源生态系统之上。
架构的关键组件
🌀 Apache Flink — 实时流处理引擎
Apache Flink 是实时摄取层的核心。我实现了一个基于 Java 的 Flink 作业,该作业监听来自 RabbitMQ 或 Kafka 的消息,并将它们转换为结构化记录,然后写入 Iceberg 表。
关键配置:
-
源(Source): RabbitMQ/Kafka 连接器,用于从持久队列/主题中消费数据。
-
接收器(Sink): 使用 Nessie Catalog 的 Flink Iceberg 接收器。
-
检查点(Checkpointing): 已启用,以保证精确一次(exactly-once)的语义。
-
并行度(Parallelism): 已调优,以实现最佳吞吐量和延迟。
这种设置确保了事件在数据湖中以近乎实时的方式可用,并具有强大的一致性和容错性。
Flink 集群的 Docker 文件
您可以通过此 Dockerfile 部署您的 Flink 集群。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
# Dockerfile for Flink Cluster
## Start from the official Flink image
FROM flink:1.19.1-scala_2.12
###############################################
## Download Neccessary Jars to Flink Class Path
###############################################
## Iceberg Flink Library
RUN curl -L https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-flink-runtime-1.19/1.6.1/iceberg-flink-runtime-1.19-1.6.1.jar -o /opt/flink/lib/iceberg-flink-runtime-1.19-1.6.1.jar
## Hive Flink Library
RUN curl -L https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-hive-2.3.9_2.12/1.19.1/flink-sql-connector-hive-2.3.9_2.12-1.19.1.jar -o /opt/flink/lib/flink-sql-connector-hive-2.3.9_2.12-1.19.1.jar
## Hadoop Common Classes
RUN curl -L https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-common/2.8.3/hadoop-common-2.8.3.jar -o /opt/flink/lib/hadoop-common-2.8.3.jar
## Hadoop AWS Classes
RUN curl -L https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar -o /opt/flink/lib/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
## AWS Bundled Classes
RUN curl -L https://repo1.maven.org/maven2/software/amazon/awssdk/bundle/2.20.18/bundle-2.20.18.jar -o /opt/flink/lib/bundle-2.20.18.jar
RUN curl -L https://repo1.maven.org/maven2/software/amazon/awssdk/s3/2.20.18/s3-2.20.18.jar -o /opt/flink/lib/s3-2.20.18.jar
## Apache Kafka
RUN curl -L https://repo1.maven.org/maven2/org/apache/kafka/kafka_2.13/2.5.0/kafka_2.13-2.5.0.jar -o /opt/flink/lib/kafka_2.13-2.5.0.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.5.0/kafka-clients-2.5.0.jar -o /opt/flink/lib/kafka-clients-2.5.0.jar
## Flink Parquet
RUN curl -L https://repo1.maven.org/maven2/org/apache/flink/flink-parquet/1.19.1/flink-parquet-1.19.1.jar -o /opt/flink/lib/flink-parquet-1.19.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/avro/avro/1.11.1/avro-1.11.1.jar -o /opt/flink/lib/avro-1.11.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/parquet/parquet-hadoop/1.11.1/parquet-hadoop-1.11.1.jar -o /opt/flink/lib/parquet-hadoop-1.11.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/parquet/parquet-avro/1.11.1/parquet-avro-1.11.1.jar -o /opt/flink/lib/parquet-avro-1.11.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/parquet/parquet-column/1.11.1/parquet-column-1.11.1.jar -o /opt/flink/lib/parquet-column-1.11.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/parquet/parquet-common/1.11.1/parquet-common-1.11.1.jar -o /opt/flink/lib/parquet-common-1.11.1.jar
## Install Nano to edit files
##RUN apt update && apt install -y nano
CMD ["./bin/start-cluster.sh"]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import org.apache.flink.api.common.time.Time;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.flink.CatalogLoader;
import org.apache.iceberg.flink.TableLoader;
import org.apache.iceberg.flink.sink.FlinkSink;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.Properties;
public class DummyStreamJob {
public static void run() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000 * 60 * 15);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
Properties nessieCatalog = ConfigLoader.loadConfig("nessie-catalog.properties");
String s3accessKey = Optional.ofNullable(System.getenv("AWS_ACCESS_KEY_ID")).orElse("null");
String s3secretKey = Optional.ofNullable(System.getenv("AWS_SECRET_ACCESS_KEY")).orElse("null");
Map<String, String> catalogOptions = new HashMap<>();
catalogOptions.put("type", nessieCatalog.getProperty("type"));
catalogOptions.put("catalog-type", nessieCatalog.getProperty("catalog-type"));
catalogOptions.put("uri", nessieCatalog.getProperty("uri"));
catalogOptions.put("ref", nessieCatalog.getProperty("ref"));
catalogOptions.put("nessie.auth.type", nessieCatalog.getProperty("nessie.auth.type"));
catalogOptions.put("warehouse", nessieCatalog.getProperty("warehouse"));
catalogOptions.put("s3.endpoint", nessieCatalog.getProperty("s3.endpoint"));
catalogOptions.put("s3.aws-access-key", s3accessKey);
catalogOptions.put("s3.aws-secret-key", s3secretKey);
catalogOptions.put("client.assume-role.region", nessieCatalog.getProperty("client.assume-role.region"));
catalogOptions.put("s3.path-style-access", nessieCatalog.getProperty("s3.path-style-access"));
catalogOptions.put("fs.native-s3.enabled", nessieCatalog.getProperty("fs.native-s3.enabled"));
catalogOptions.put("io-impl", nessieCatalog.getProperty("io-impl"));
catalogOptions.put("catalog-impl", nessieCatalog.getProperty("catalog-impl"));
Configuration hadopConf = new Configuration();
hadopConf.set("fs.s3a.access.key", s3accessKey);
hadopConf.set("fs.s3a.secret.key", s3secretKey);
hadopConf.set("fs.s3a.endpoint", nessieCatalog.getProperty("s3.endpoint"));
hadopConf.set("fs.s3a.path.style.access", nessieCatalog.getProperty("s3.path-style-access"));
hadopConf.set("fs.native-s3.enabled", nessieCatalog.getProperty("fs.native-s3.enabled"));
// Iceberg Catalog Definition
CatalogLoader catalogLoader = CatalogLoader.custom("nessie_catalog", catalogOptions, hadopConf, nessieCatalog.getProperty("catalog-impl"));
// Iceberg Table Setting
TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader, TableIdentifier.of("my_dummy_schema", "my_dummy_iceberg_table"));
// RabbitMQ Config Properties
Properties sourceRabbitMQProps = ConfigLoader.loadConfig("dummy-rabbitmq-source.properties");
// Creating Flink DataStream object from RabbitMQ Event Data
DataStream<String> dummyEventString = DummyEventProcessor.DummyEventStream(env, sourceRabbitMQProps);
// Creating DataStream<RowData> object for Flink Iceberg Sink Process
DataStream<RowData> rowDataDataStream = dummyEventString.map(new RawStringToRowDataMapper());
// Appending event data to s3 backend (Minio) as a Iceberg table data
FlinkSink.forRowData(rowDataDataStream).tableLoader(tableLoader).append();
// Flink Job Execution
env.execute("RabbitMQ to Iceberg");
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-iceberg-streaming</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.19.1</flink.version>
<flink.connector.version>3.2.0-1.19</flink.connector.version>
<java.version>11</java.version>
<kafka.version>2.5.0</kafka.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<!-- These dependencies are provided, we're expecting these libraries will be exist in server/classpath. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime-1.19</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<!-- These dependencies are not provided, these libraries should be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.connector.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-rabbitmq</artifactId>
<version>1.16.1</version> <!-- There is no newest library for RabbitMQ Flink Connector -->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.6.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# Implementation Class
catalog-impl=org.apache.iceberg.nessie.NessieCatalog
io-impl=org.apache.iceberg.aws.s3.S3FileIO
# Nessie
type=iceberg
catalog-type=nessie
uri=http://your_nessie_host:19120/api/v1
nessie.auth.type=NONE
ref=main
warehouse=s3a://your_bucket_name
# Minio/s3
s3.endpoint=http://your_minio_host:9000
s3.path-style-access=true
fs.native-s3.enabled=true
client.assume-role.region=us-east-1
|
- 在部署好Flink之后,就可以通过Flink的webui部署Jar包到Flink上运行了。
Iceberg 提供了一种现代数据布局,克服了 Hive 或普通 Parquet 等旧式文件系统的局限性。
为什么选择 Iceberg?
所有原始和转换后的数据集都以 Iceberg 表的形式存储,确保了数据的可靠性、一致性和长期可维护性。
模式和表创建示例:
1
2
3
4
5
6
7
8
9
|
create schema my_dummy_schema;
create table my_dummy_schema.my_dummy_iceberg_table
(
data_date date,
my_string_column varchar,
my_integer_column integer
) with
( partitioning = array['data_date']);
|
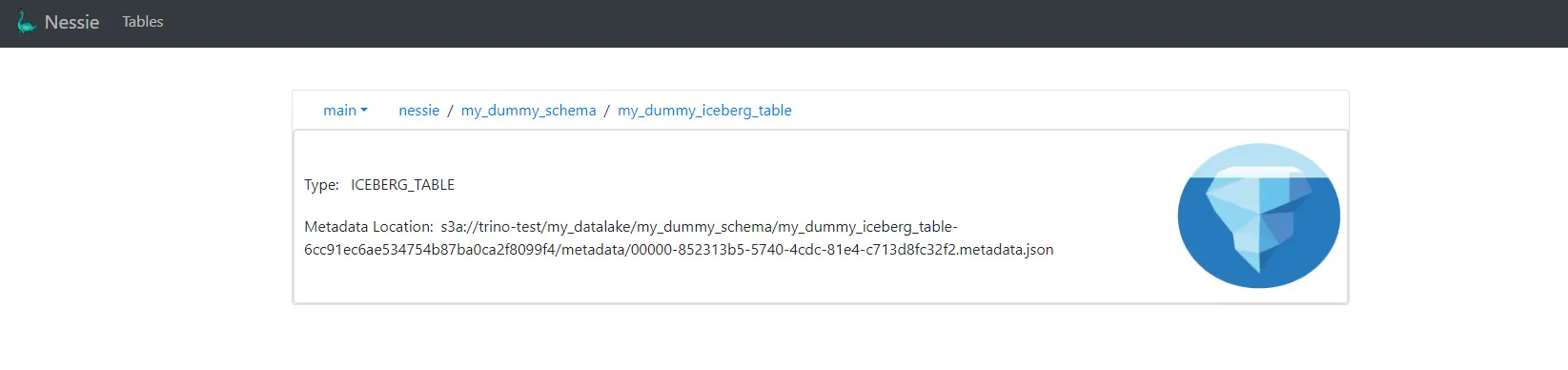
🌿 Project Nessie — Git for Data
Project Nessie 作为 Apache Iceberg 表的版本控制目录层。它将类似 Git 的语义引入数据领域,包括分支、提交和标签,从而为数据操作带来了可复现性、协作性和安全性。
🧠 为什么 Nessie 很重要:
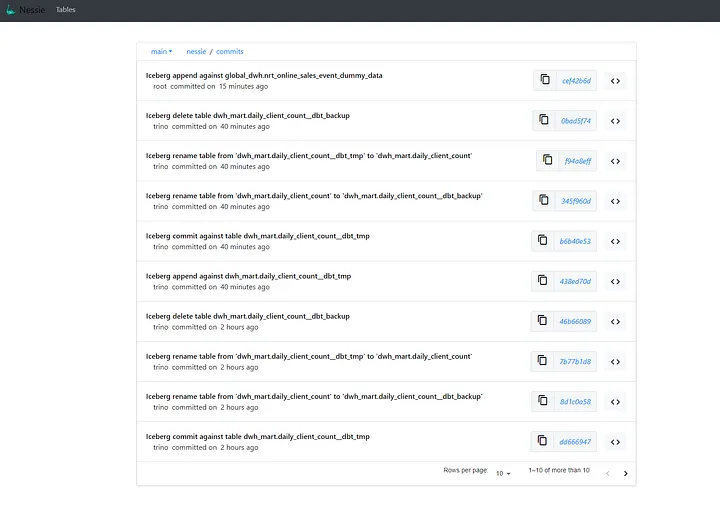
在传统的目录(如 Hive Metastore 或 Glue)中,所有更改都直接应用到主分支,并且没有内置的方法来隔离地测试转换或轻松回滚。而 Nessie 改变了这一现状。
✅ 主要优势及实例:
1
|
nessie branch dev-feature-x main
|
然后,您运行 dbt 并将其指向 dev-feature-x 分支。这不会对生产数据造成任何风险。
1
|
nessie merge dev-feature-x into main
|
好的,这是您提供的文本的中文翻译:
1
|
nessie reset main to commit_hash
|
- 在CI/CD中自动化测试 → 对于每一次的pull reques,nessie都会对应启动一个自动化测试用例,当自动化测试用例通过之后,代码就合并到main分支中。
📦 MinIO — 对象存储后端
MinIO 为存储实际的 Iceberg 数据文件提供了 S3 兼容的后端。它具有云原生、轻量化的特点,并能与 Iceberg 和 Nessie 无缝集成。
为什么选择 MinIO?
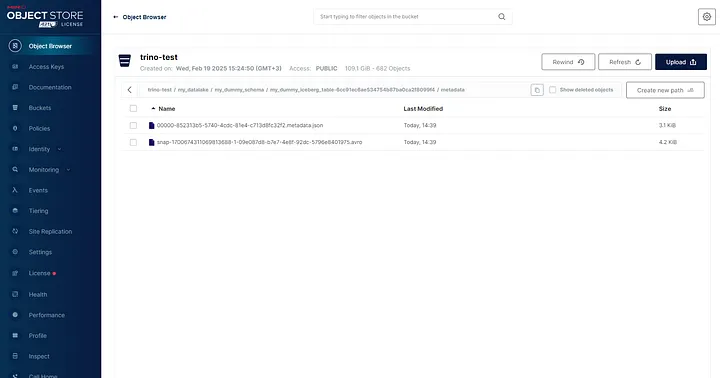
通过 Minio Web UI 查看 Iceberg 表的 S3 路径:
🛠️ dbt — 转换与建模
dbt 负责转换层的工作,它从原始的 Iceberg 表中读取数据,并生成用于报告或下游分析的精选模型。
关键实践:
-
物化(Materializations): 根据需求选择增量(incremental)、快照(snapshot)或视图(view)物化方式。
-
测试(Tests): 将模式和数据测试集成到每个模型中。
-
版本控制(Versioning): 通过 Nessie 实现模型在 Git 中的控制和分支感知。
用于 Trino/Iceberg 的 dbt profiles.yml:
1
2
3
4
5
6
7
8
9
10
11
12
|
dbt_iceberg:
target: dev
outputs:
dev:
type: trino
method: none
user: admin
database: datalake
host: your-trino-host
port: 8080
schema: your-schema
threads: 1
|
🔗 Trino (Iceberg 的 SQL 查询引擎)
Trino 充当了连接 dbt 和 Apache Iceberg 的 SQL 引擎,它提供了:
✅ 我配置 Trino 使用指向 MinIO 的 Iceberg 目录,并可选地接入 Nessie 来管理分支。
用于 Trino 的 Iceberg Nessie 连接器配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
datalake: |
connector.name=iceberg
iceberg.catalog.type=nessie
iceberg.nessie-catalog.uri=http://nessie-host:19120/api/v1
iceberg.nessie-catalog.default-warehouse-dir=s3a://iceberg-bucket/
iceberg.nessie-catalog.ref=main
iceberg.register-table-procedure.enabled=true
iceberg.file-format=parquet
fs.native-s3.enabled=true
s3.exclusive-create=false
s3.path-style-access=true
s3.endpoint=http://minio-host:9000
s3.region=us-east-1
s3.aws-access-key=XXXX
s3.aws-secret-key=YYYY
|
⏱ Apache Airflow — 编排层
Airflow 负责编排按计划运行 dbt 模型的批处理工作流。
详情:
这确保了数据的定期、可靠处理,并能完整地监控作业的健康状况和状态。
Airflow Docker 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
FROM apache/airflow:2.8.1-python3.10
RUN pip install --no-cache-dir \
dbt-core==1.8.3 \
dbt-postgres==1.8.2 \
dbt-trino==1.8.3 \
boto3==1.34.84 \
awscli==1.32.84
USER root
RUN apt-get update && apt-get install -y \
git && apt-get clean && rm -rf /var/lib/apt/lists/*
USER airflow
|
Airflow DAG for DAG Sync from Minio:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import os
import boto3
MINIO_ENDPOINT = os.getenv("S3_ENDPOINT_URL", "http://minio:9000")
MINIO_ACCESS_KEY = os.getenv("AWS_ACCESS_KEY_ID", "minioadmin")
MINIO_SECRET_KEY = os.getenv("AWS_SECRET_ACCESS_KEY", "minioadmin")
DAGS_BUCKET_NAME = "airflow-dags"
DAGS_FOLDER = os.getenv("AIRFLOW__CORE__DAGS_FOLDER", "/opt/airflow/dags")
def download_dags_from_minio():
s3 = boto3.client(
's3',
endpoint_url=MINIO_ENDPOINT,
aws_access_key_id=MINIO_ACCESS_KEY,
aws_secret_access_key=MINIO_SECRET_KEY,
)
objects = s3.list_objects_v2(Bucket=DAGS_BUCKET_NAME)
if "Contents" not in objects:
print("No DAGs found in bucket.")
return
for obj in objects["Contents"]:
key = obj["Key"]
if not key.endswith(".py"):
continue
local_path = os.path.join(DAGS_FOLDER, os.path.basename(key))
s3.download_file(DAGS_BUCKET_NAME, key, local_path)
print(f"Downloaded {key} to {local_path}")
with DAG(
dag_id="sync_dags_from_minio",
start_date=datetime(2025, 1, 1),
schedule_interval="@hourly",
catchup=False,
tags=["maintenance"],
) as dag:
sync_task = PythonOperator(
task_id="sync_dags_from_minio",
python_callable=download_dags_from_minio
)
|
Airflow DAG for dbt Project Sync from Minio:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import os
import boto3
MINIO_ENDPOINT = os.getenv("S3_ENDPOINT_URL", "http://minio:9000")
MINIO_ACCESS_KEY = os.getenv("AWS_ACCESS_KEY_ID", "minioadmin")
MINIO_SECRET_KEY = os.getenv("AWS_SECRET_ACCESS_KEY", "minioadmin")
DBT_BUCKET_NAME = "dbt-project"
DBT_FOLDER = "/opt/airflow/dbt"
def download_dags_from_minio():
s3 = boto3.client(
's3',
endpoint_url=MINIO_ENDPOINT,
aws_access_key_id=MINIO_ACCESS_KEY,
aws_secret_access_key=MINIO_SECRET_KEY,
)
objects = s3.list_objects_v2(Bucket=DBT_BUCKET_NAME)
if "Contents" not in objects:
print("No dbt files found in bucket.")
return
for obj in objects["Contents"]:
key = obj["Key"]
dest_path = os.path.join(DBT_FOLDER, key)
dest_dir = os.path.dirname(dest_path)
os.makedirs(dest_dir, exist_ok=True)
s3.download_file(DBT_BUCKET_NAME, key, dest_path)
print(f"Downloaded {key} to {dest_path}")
with DAG(
dag_id="sync_dbt_from_minio",
start_date=datetime(2025, 1, 1),
schedule_interval="@hourly",
catchup=False,
tags=["dbt"],
) as dag:
sync_task = PythonOperator(
task_id="sync_dbt_from_minio",
python_callable=download_dags_from_minio
)
|
Airflow DAG for running dbt Models
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
DBT_FOLDER = "/opt/airflow/dbt"
with DAG(
dag_id="run_dbt_project",
start_date=datetime(2025, 1, 1),
schedule_interval="@hourly",
catchup=False,
tags=["dbt"],
) as dag:
dbt_run = BashOperator(
task_id="dbt_run",
bash_command=f"cd {DBT_FOLDER} && dbt run"
)
dbt_run
|
Airflow DAG for dbt documentation to Minio:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from datetime import datetime
import boto3
import os
def upload_docs_to_minio(**kwargs):
s3 = boto3.client(
's3',
endpoint_url=os.getenv("S3_ENDPOINT_URL"),
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY")
)
bucket_name = "dbt-project"
local_docs_path = "/opt/airflow/dbt/target"
for root, _, files in os.walk(local_docs_path):
for file in files:
full_path = os.path.join(root, file)
relative_path = os.path.relpath(full_path, local_docs_path)
s3_key = f"docs/{relative_path}"
s3.upload_file(full_path, bucket_name, s3_key)
print(f"Uploaded {file} to s3://{bucket_name}/{s3_key}")
default_args = {
'start_date': datetime(2024, 1, 1),
}
with DAG(
dag_id='dbt_docs_to_minio',
schedule_interval=None,
catchup=False,
default_args=default_args,
description='Generate dbt docs and upload to MinIO S3',
) as dag:
generate_docs = BashOperator(
task_id='generate_dbt_docs',
bash_command='cd /opt/airflow/dbt && dbt docs generate'
)
upload_to_s3 = PythonOperator(
task_id='upload_docs_to_minio',
python_callable=upload_docs_to_minio
)
generate_docs >> upload_to_s3
|
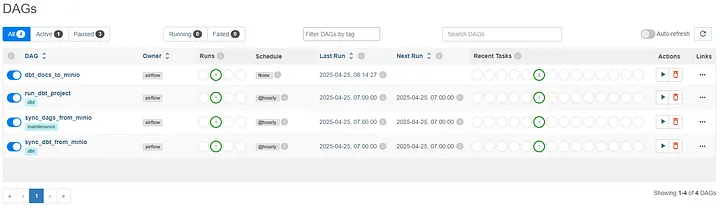
Airflow Web UI:
🚀 性能与可扩展性
从一开始,设计就将性能和可扩展性作为关键目标。堆栈中的每个组件都因其独立扩展和在分布式环境中高效运行的能力而被选中:
-
Apache Flink 可以水平扩展,并以精确一次(exactly-once)的保证每秒处理数百万个事件。我们对并行度、检查点和缓冲区超时进行了调优,以确保在生产负载下实现低延迟摄取。
-
Apache Iceberg 通过隐藏分区和元数据裁剪实现高效的读写。即使数据量增长,由于 Iceberg 的快照隔离和基于清单的规划,查询性能依然保持稳定。
-
MinIO 作为在 OpenShift 上自托管的对象存储表现出色,支持来自 Flink 的高吞吐量并行写入以及 Trino 的快速读取。
-
Trino 的分布式查询引擎支持对 Iceberg 表进行快速、联合查询,即使在高并发和多租户工作负载下也表现良好。
-
Airflow 和 dbt 的设计支持水平扩展。dbt 模型可以分组并行运行,而 Airflow DAG 以 Kubernetes 原生方式无缝处理依赖关系和重试。
通过保持架构的模块化,每个组件都可以根据不断变化的数据负载进行独立调优或扩展,从而确保了成本效益和可靠性。
🧠 挑战与经验教训
在构建此架构时,我遇到了几个技术挑战。以下是一些关键经验教训:
-
Nessie 中的快照和分支管理: 适应在管理表时采用版本化的思维模式需要时间。开发人员需要像对待 Git 仓库一样对待数据湖,这在最初是不熟悉的,但一旦掌握,其功能异常强大。
-
Flink 与 S3 (MinIO) 的检查点: 将 Flink 与对象存储集成以进行检查点和状态后端是棘手的。我们必须微调文件系统一致性设置并增加检查点超时,以使其在突发负载下保持稳定。
-
跨工具的模式演进: 尽管 Iceberg 支持模式演进,但要让 dbt 和 Trino 动态反映模式变化,需要在建模和目录管理中遵守纪律。
-
分布式设置中的调试: 由于多个服务部署在 OpenShift 上,拥有集中式可观察性至关重要。我们依赖 OpenShift 内置的监控和 OpenShift 日志来追踪 Flink、Trino 和批处理工作流中的问题。这在不引入 ELK 等外部工具的情况下提供了足够的洞察力。
总结与结语
构建这个开放数据湖仓架构让我对现代数据生态系统的力量和灵活性有了更深的认识。通过结合 Flink、Iceberg、Nessie、dbt、Trino 和 Airflow 等工具,并在 OpenShift 上进行编排,我得以设计一个既支持实时处理又支持批处理、具有强大版本控制和模块化转换层的系统。
如果您正在从事现代数据堆栈工作,或者正在考虑构建自己的湖仓,我希望本文能为您提供一些启发和实践指导。欢迎随时与我联系或分享您的想法——我很乐意听听其他人是如何解决类似挑战的!