以下是您提供内容的精确中文翻译,保留所有技术细节与专业术语:
Elasticsearch 是一款可扩展、支持多租户的全文分布式搜索与分析引擎。它构建在Apache Lucene(高性能文本搜索引擎库)之上,采用开源模式。作为基于文档的数据库,Elasticsearch被广泛应用于分析、搜索和监控等场景。
Apache Flink® 是开源的分布式流批处理一体化平台,能够对无界和有界数据流进行无状态或有状态计算。它是构建实时数据管道和应用的强大工具,例如可作为事件驱动型应用中的触发机制——当新数据到达时触发搜索索引更新。Flink还可用于从持续流动的实时数据流中提取信息与洞察。
本教程将演示如何通过Flink、Elasticsearch与Redpanda(更简单、对开发者友好的Apache Kafka®替代方案)构建闪电般快速的搜索索引。
搜索索引背后的技术解析
在构建高速搜索索引时,性能与延迟是关键指标。面对海量动态数据源(如全文搜索应用、分析仪表盘、自动补全功能和告警引擎),快速检索能力至关重要。
- Flink负责数据转换、丰富与清洗
- Elasticsearch建立索引实现可搜索性
这种技术组合使用户能快速高效检索庞大数据集。
要创建面向Elasticsearch的实时流式管道,需优化数据流处理流程以确保高效准确处理。Redpanda为实现高性能数据传输提供理想解决方案:
- 采用C++构建的轻量级流数据引擎,特别适合计算资源受限的边缘硬件
- 完全兼容Apache Kafka® API,简化架构复杂度
- 相较Kafka实现10倍性能提升,延迟波动更小
通过Redpanda与Elasticsearch的集成,可大幅提升Elasticsearch的数据存储与分析速度。
基于Redpanda+Flink+Elasticsearch的搜索索引实现
假设存在一个多服务系统,持续生成包含基础信息的用户活动事件。这些事件需要传输至专为搜索优化的数据存储中,且在入库前需通过元数据丰富事件内容以提升搜索效率。三者的协同工作将构建满足该场景的极速搜索索引。
下图展示了搜索索引系统的数据流水线(注:原文档此处应有架构图,可参考原始链接中的图表):
|
|
流程说明:
- 事件源将原始数据写入Redpanda流式平台
- Flink实时消费数据流,执行去重、字段补充、格式标准化等操作
- 处理后的结构化数据批量写入Elasticsearch建立倒排索引
- 应用层通过Elasticsearch API实现亚秒级检索响应
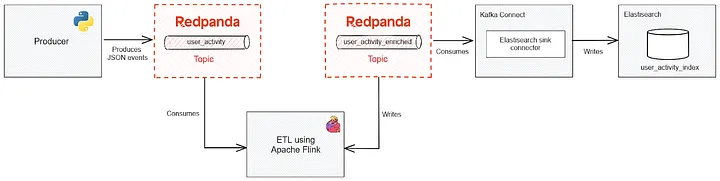
- Python 产生事件发送到 Redpanda的 topic。
- Flink 处理数据写入到Redpanda的另一个topic。
- Elasticsearch 索引第二个Redpanda的 topic并提供查询功能。
All of the code resources for this tutorial can be found in this repository.
## 前置条件:
1. docker
2. 运行在docker中的redpanda
3. anacoda运行python3.10以上版本
4. 安装jq命令cli。
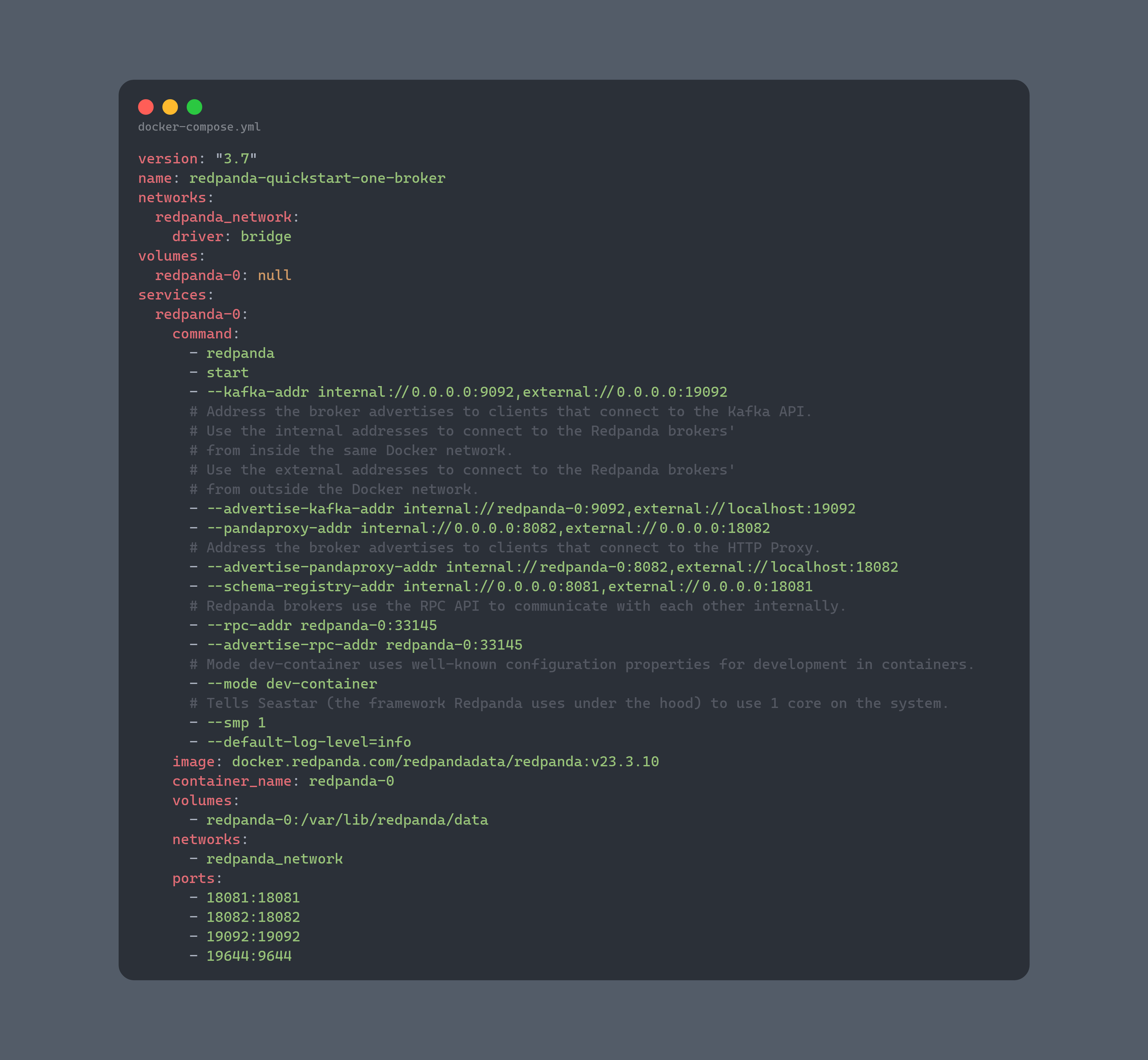
### docker运行redpanda程序
通过docker-compose来运行redpanda
 接下来准备flink+elastic+sqlclient的文件docker-compose文件
接下来准备flink+elastic+sqlclient的文件docker-compose文件
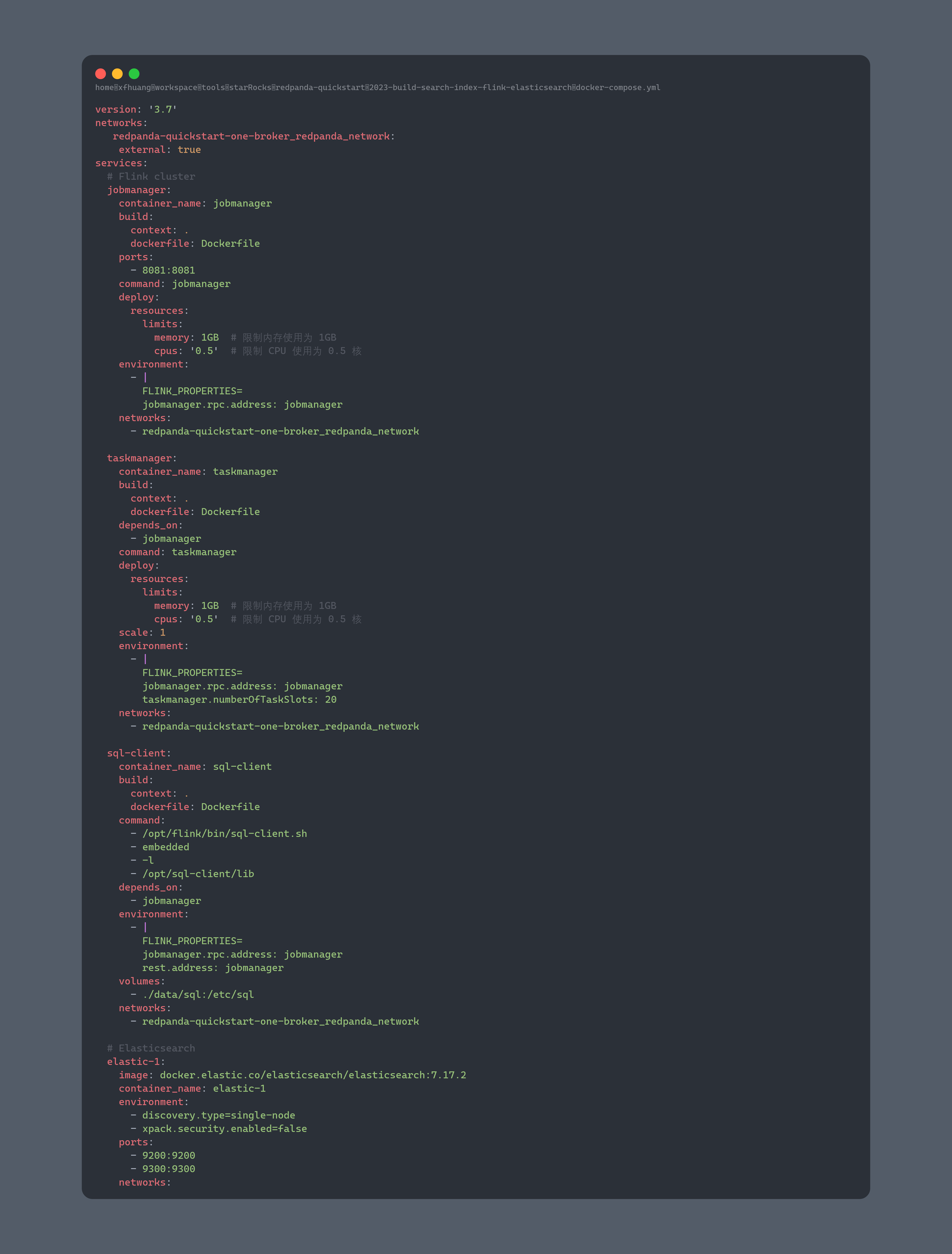
这里需要注意到两个docker-compose文件,是共享一个网络的,都是redpanda-quickstart-one-broker_redpanda_network-,这样才可以保证网络的hostname互通。
我们可以注意到这里使用的镜像是自己构建的,需要添加对应的依赖:
|
|
这里使用的flink版本为1.18.1 启动这个docker-compose文件的命令包含两步,第一步是构建,第二步是运行
|
|
如果这一切正常可以达到如下的效果:

创建topic
使用redpanda的命令来创建topic
|
|
连接kafka到elasticsearch
Elasticsearch 可以使用 Kafka Connect 和兼容的连接器(例如 Camel Elasticsearch Kafka Sink 连接器)轻松连接到 Redpanda。Kafka Connect 与 Apache Kafka 软件包捆绑在一起。要获取 Kafka Connect,请前往 Apache Kafka 下载页面,然后点击 Scala 2.13 的 Kafka 2.8.0 二进制包下载链接。下载二进制文件后,将其解压到项目根目录。接下来,在项目根目录下创建一个名为 configuration 的文件夹,并在其中创建 connect.properties 文件,内容如下:
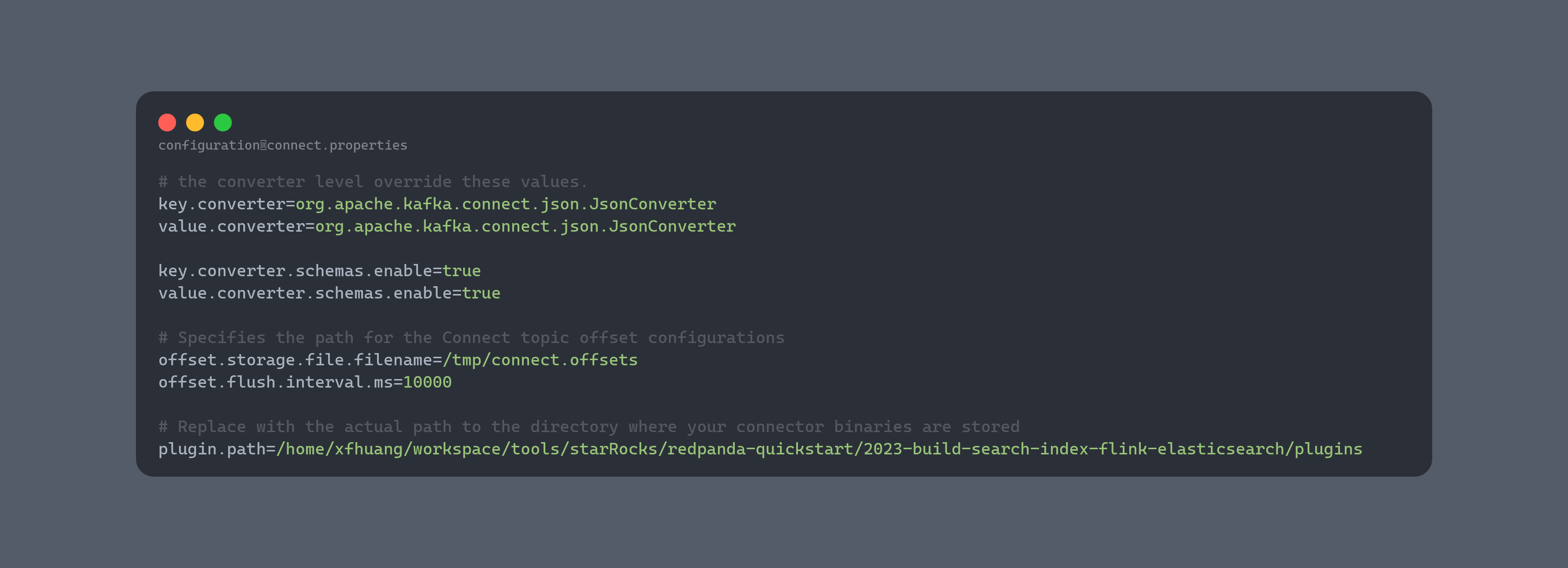 请注意,bootstrap.servers 地址设置为 localhost:9092,这与 Redpanda 集群地址相对应。现在需要设置 Camel Elasticsearch Index Sink Kafka 连接器。访问此网页,然后点击 camel-elasticsearch-index-sink-kafka-connector 旁边的下载链接。下载完成后,解压文件,然后将 camel-elasticsearch-index-sink-kafka-connector 文件夹复制到 plugins 目录。要设置 Elasticsearch 的接收器连接器,请在配置目录中创建一个名为 elasticsearch-sink-connector.properties 的文件,并在其中填充以下内容:
请注意,bootstrap.servers 地址设置为 localhost:9092,这与 Redpanda 集群地址相对应。现在需要设置 Camel Elasticsearch Index Sink Kafka 连接器。访问此网页,然后点击 camel-elasticsearch-index-sink-kafka-connector 旁边的下载链接。下载完成后,解压文件,然后将 camel-elasticsearch-index-sink-kafka-connector 文件夹复制到 plugins 目录。要设置 Elasticsearch 的接收器连接器,请在配置目录中创建一个名为 elasticsearch-sink-connector.properties 的文件,并在其中填充以下内容:
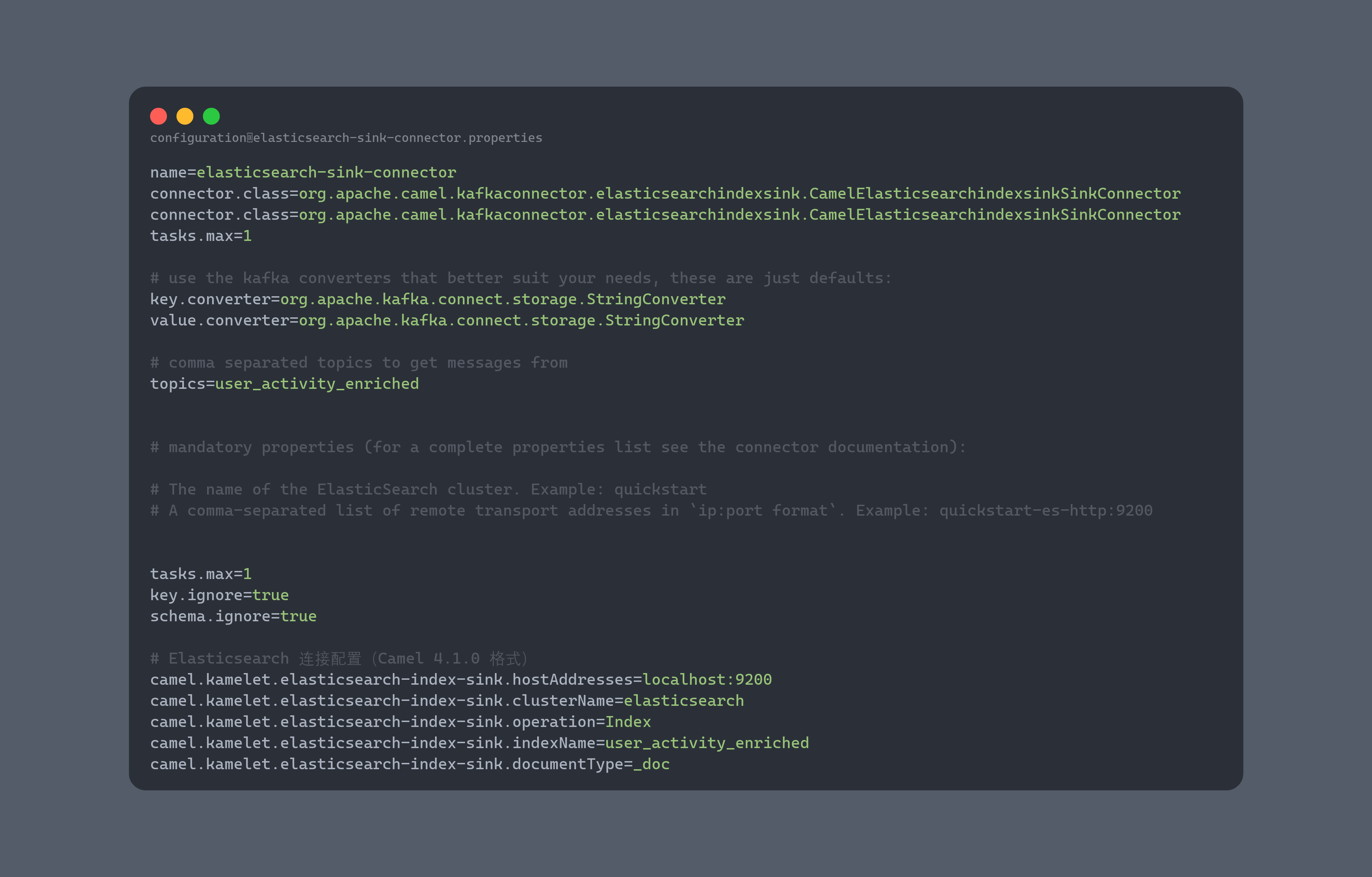 进入到congfiguration的目录下执行命令:
进入到congfiguration的目录下执行命令:
|
|
输出如下所示:
|
|
运行producer.py脚本生产数据
安装一下依赖:
|
|
查看一下producer.py
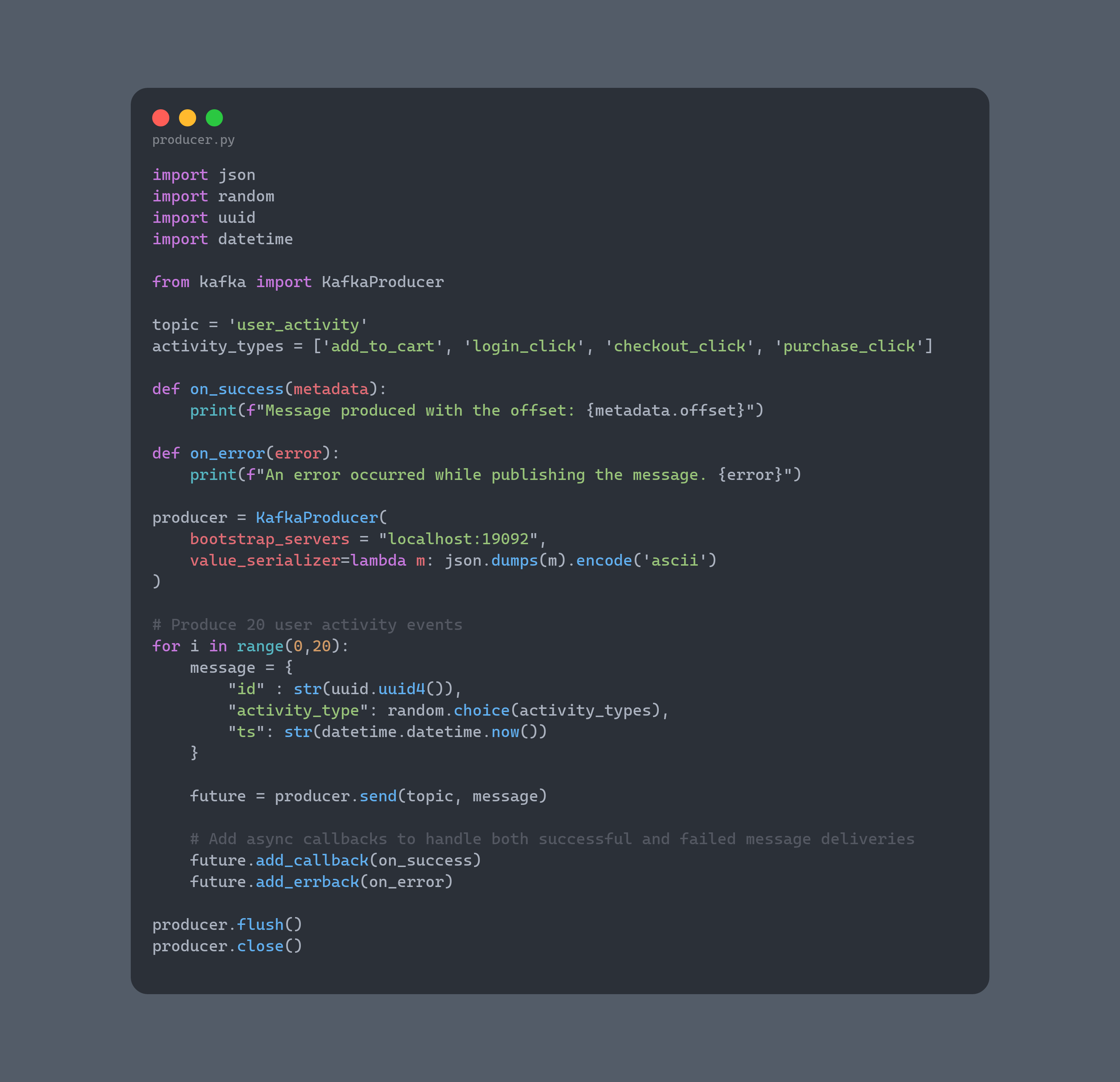 运行生产命令:
运行生产命令:
运行flink pipeline
|
|
看到如图所示

sql脚本运行
|
|
注意每一条sql都要单独执行,否则会报错
如果成功启动就可以看到flink的任务启动在flink-web界面:
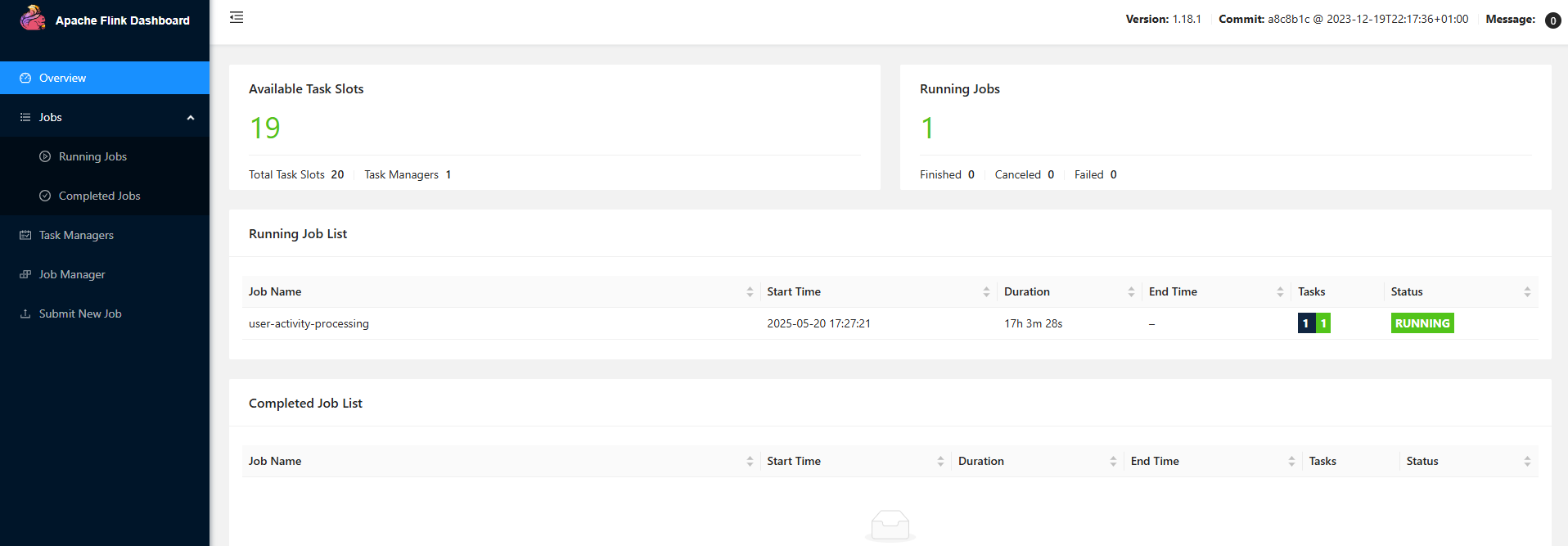 查看数据是否正常生产到user_activity_enriched这个topic中
查看数据是否正常生产到user_activity_enriched这个topic中
|
|
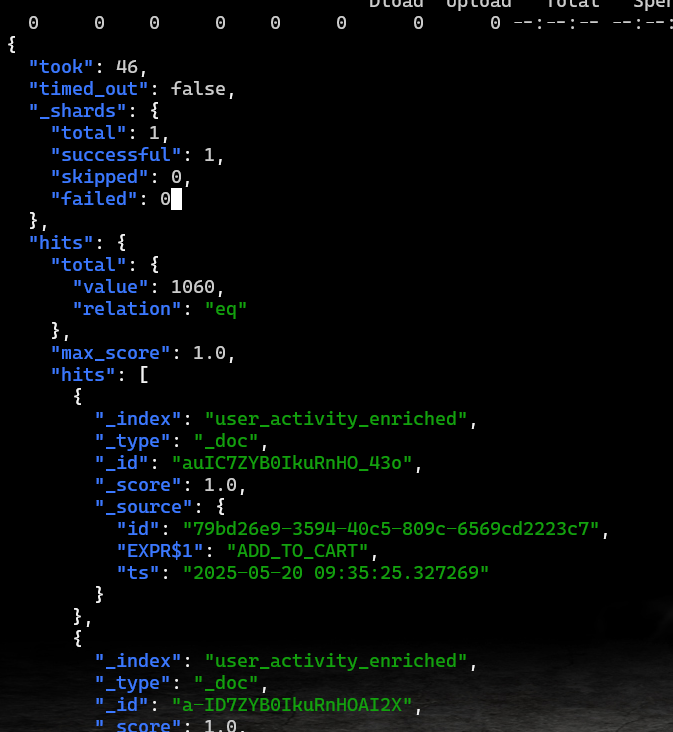
再来检验这个topic的数据是否正常被es缩影到
|
|
如果可以看到如下输出即代表正常
结论
本文演示了如何结合使用 Redpanda、Flink 和 Elasticsearch 来创建强大的数据管道和搜索应用程序。通过结合使用这些平台,您可以通过 Redpanda 流式传输数据,使用 Flink 执行 ETL 操作,并实时在 Elasticsearch 中索引数据。 参考文档: https://www.redpanda.com/blog/kafka-connect-elasticsearch-data-streaming