前言
starrocks提供了链接iceberg和hudi的能力,如下图所示,经过metastore元数据就可以对外部数据湖的数据进行访问,
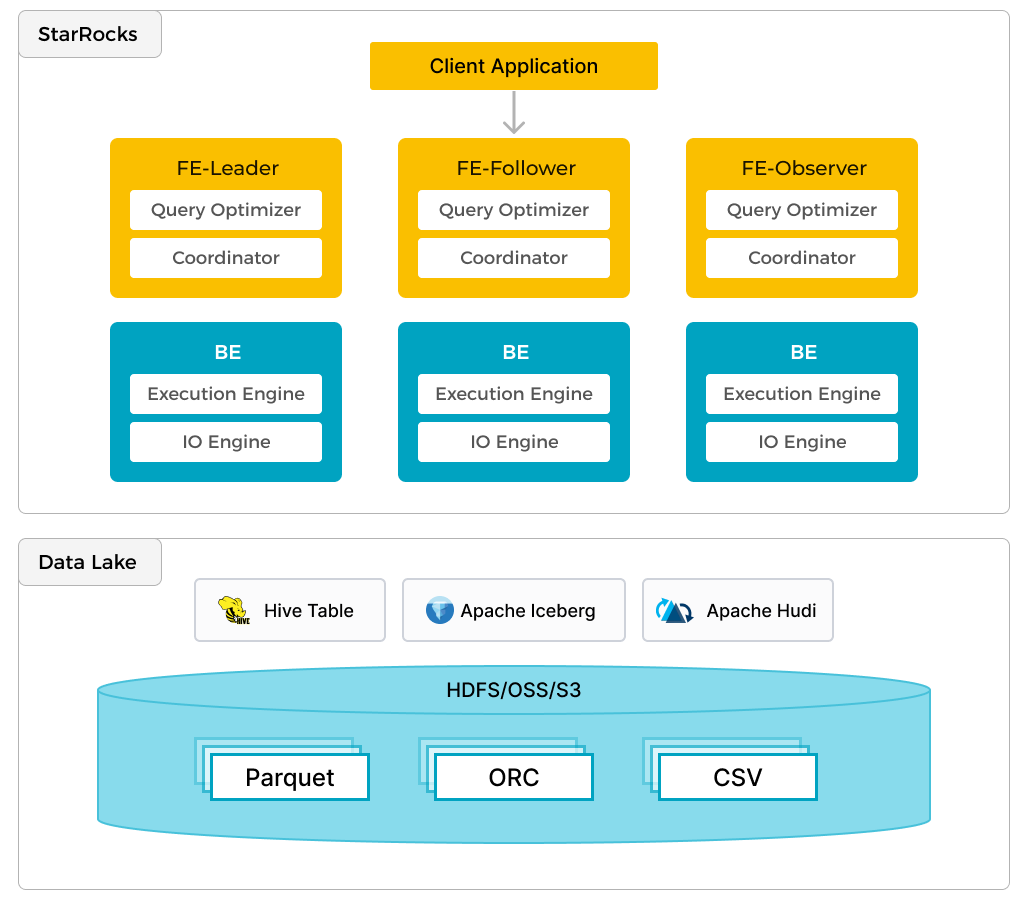
该文档详细描述了如何配置和启动一个集成 StarRocks、Hudi、MinIO 和 Spark 的演示环境。以下是主要内容:
-
前提条件:
- 克隆 StarRocks 的演示仓库,确保所有操作从
demo/documentation-samples/hudi/目录开始。 - 配置 Docker 并分配足够的内存(至少 5 GB)和 CPU(至少 4 个)。
- 克隆 StarRocks 的演示仓库,确保所有操作从
-
SQL 客户端:
- 可以选择 Docker 环境中的 SQL 客户端或其他 MySQL 兼容客户端。
-
Docker 服务:
- starrocks-fe: 元数据管理、查询规划和调度。
- starrocks-be: 查询计划的执行。
- metastore_db: 用于存储 Hive 元数据的 Postgres 数据库。
- hive_metastore: 提供 Apache Hive 的元数据服务。
- minio 和 mc: MinIO 对象存储及其命令行客户端。
- spark-hudi: 集成的 MinIO 配置服务。
-
配置文件:
- core-site.xml: 对象存储相关设置。
- spark-defaults.conf: Hive、MinIO 和 Spark SQL 的设置。
- hudi-defaults.conf: 用于在 Spark-shell 中静默警告。
- hadoop-metrics2-hbase.properties 和 hadoop-metrics2-s3a-file-system.properties: 同样用于消除警告。
-
启动演示集群:
- 在包含
docker-compose.yml文件的目录中运行以下命令启动集群:1docker compose up --detach --wait --wait-timeout 60
- 在包含
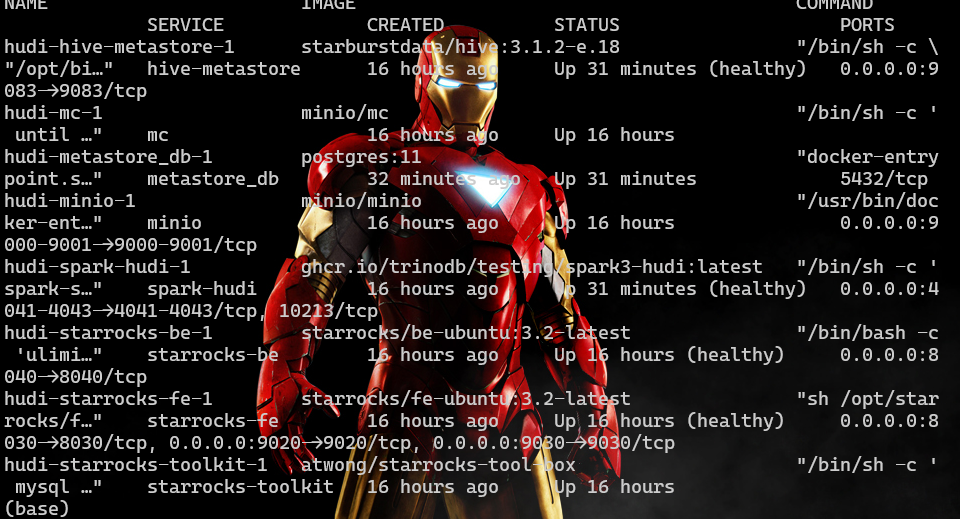
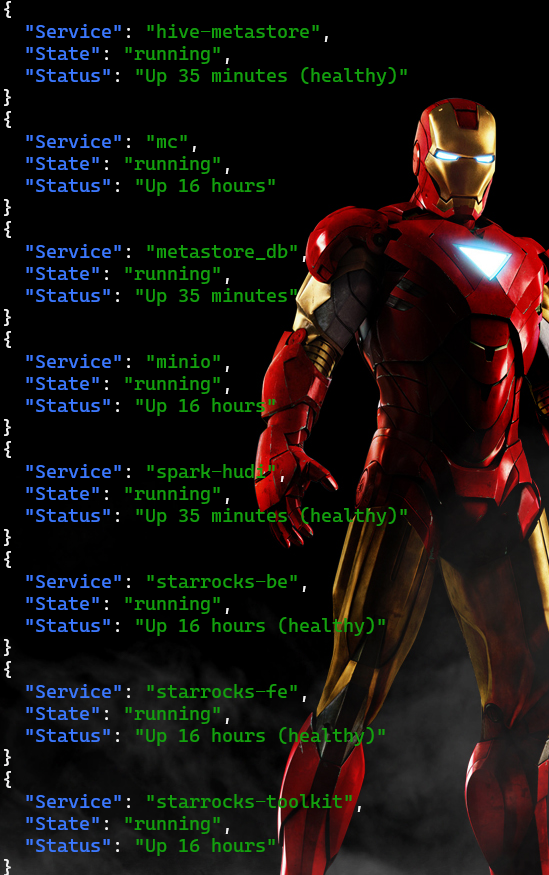
注意: 当有很多容器时,可以通过jq来进行处理
|
|
输出效果如下:
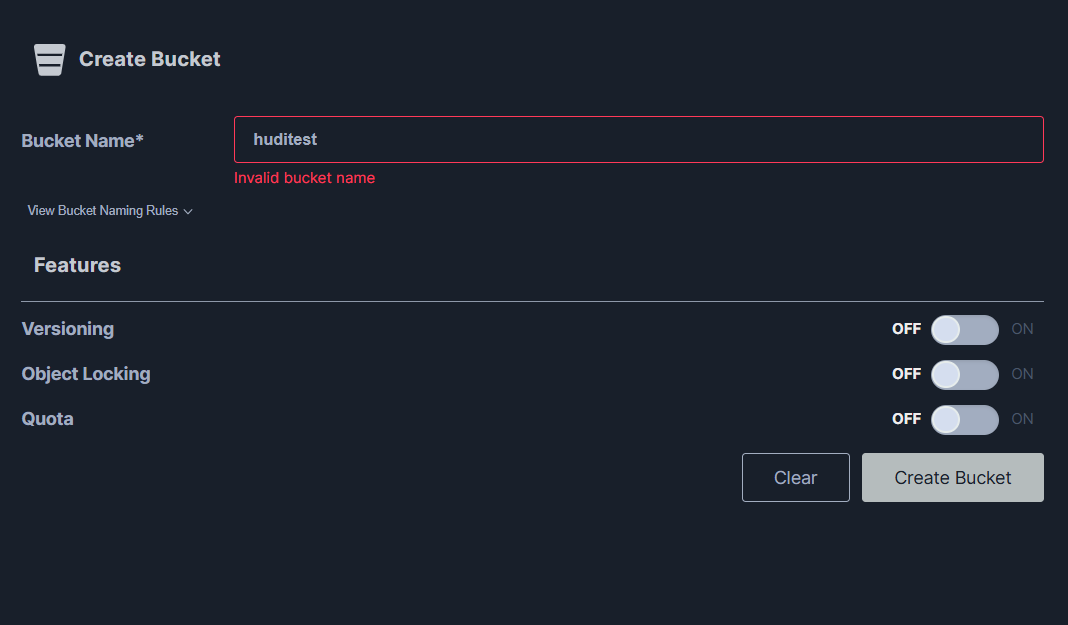
创建bucket:
因为spark要使用huditest这个bucket,接下来就在minio上创建对应的bucket
创建bucket:
创建 表格, 接下来写数据到Hive中:
打开spark-shell,命令如下:
|
|
注意输出的这些警告是正常的,不影响使用
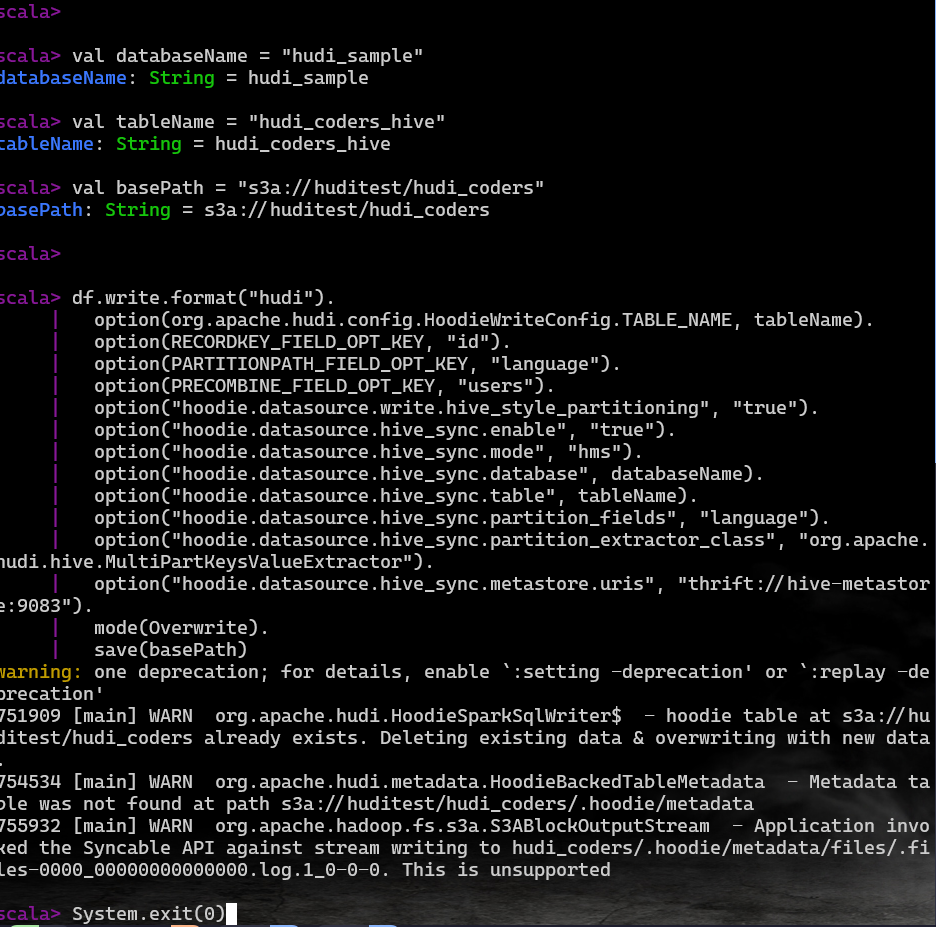
接下来就可以把下面的代码输入到’scala>‘之后就可以了
|
|
这段代码实现了如下功能:
- 配置spark session,加载处理,写入数据
- 创建一个dataframe 同时写入到hudi的表中
- 同步数据到hivemetastore
当出现如下图展示即可退出了
接下来starRocks中操作了
连接StarRocks
|
|
连接starrocks和hudi
接下来使用外部的catalog来处理hudi的数据
|
|
使用catalog
|
|
使用hudi的数据库l
|
|


接下来查询这个表
