根据这篇文章,我们可以为数据学院构建一份关于 数据血缘 的全面文档,主题围绕统一元数据管理和数据血缘的实践展开:
数据血缘与统一元数据
1. 背景介绍
数据血缘(Data Lineage)是数据治理的重要组成部分,通过追踪数据的来源、流向和关系链,解决数据的哲学三问:
- 我是谁? 数据的当前状态和位置。
- 我从哪里来? 数据的生成和来源过程。
- 我到哪里去? 数据的消费和应用场景。
血缘信息在 数据质量管理、合规性 和 安全性 中起着关键作用。
2. 数据血缘分类
-
SQL 血缘:
- 通过解析 SQL 抽象语法树(AST)识别表与字段的关系。
- 应用于复杂查询、视图创建等场景。
-
任务血缘:
- 基于调度 DAG 或埋点记录,反映数据流向和任务依赖。
3. 技术实现
SQL 血缘解析
-
核心步骤:
- SQL 解析:将 SQL 转为抽象语法树 (AST)。
- 血缘识别:通过 Visitor 遍历 AST 树,提取字段与表的上下游关系。
- 血缘存储:构建图数据库,存储节点(表/字段)和边(上下游关系)。
-
关键工具:
- Druid SQL:支持多方言 SQL 解析,高效生成 AST。
- Calcite:适用于单一 SQL 方言,支持扩展开发。
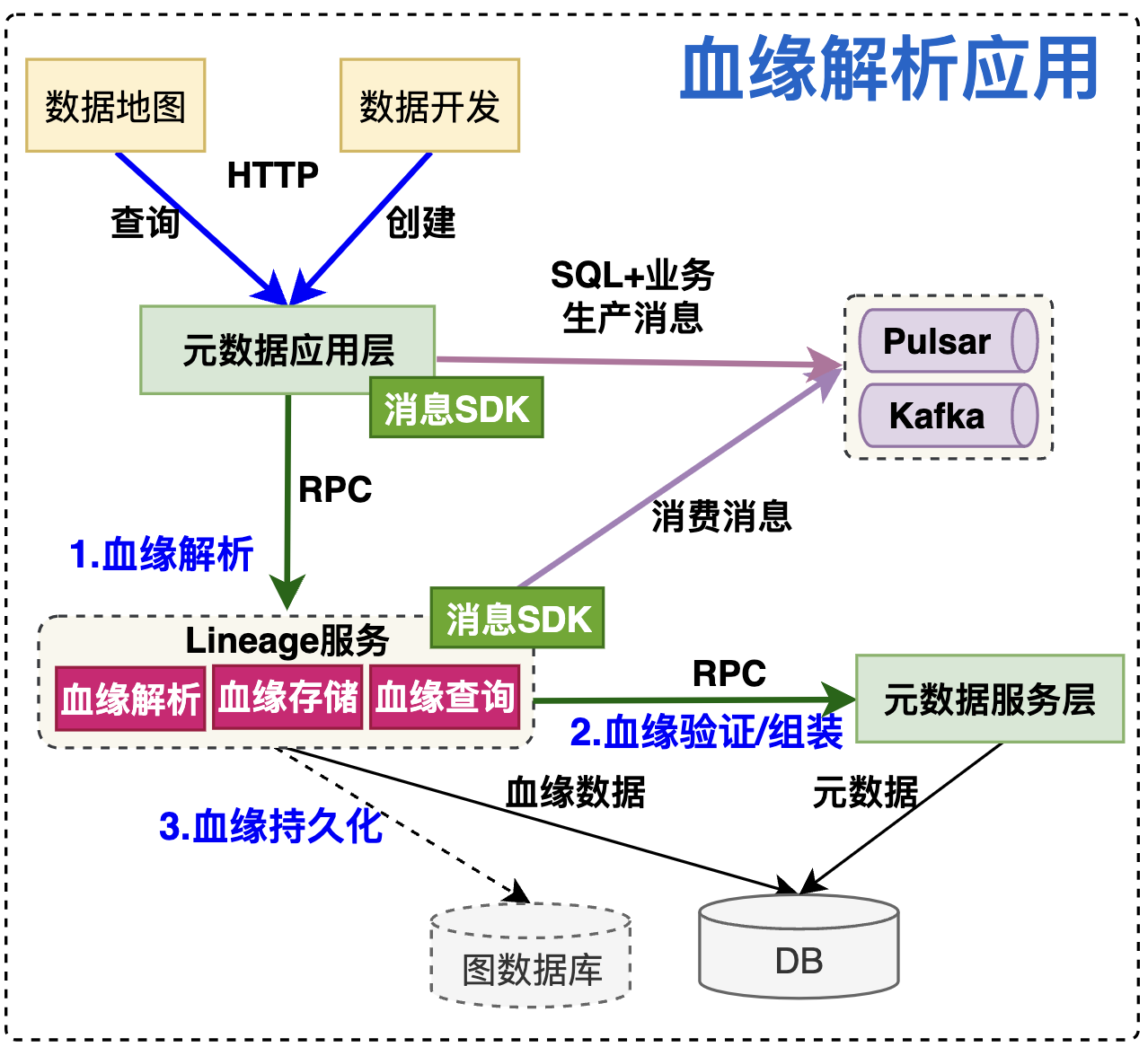
4. 应用架构
- 数据生产:
- 在数据开发或任务运行时,自动上报 SQL 和任务信息。
- 数据解析:
- 利用消息队列解耦血缘解析,将解析后的血缘数据存储在元数据服务中。
- 血缘查询:
- 提供 REST API 或图数据库接口,支持可视化查询和分析。
5. 实践与应用
业界方案对比
- Apache Atlas:基于 Hive 的血缘管理,支持简单 SQL 类型。
- DataHub:侧重任务调度血缘,但字段级支持较弱。
- Amundsen:仅支持任务级血缘。
- SQLFlow:商业化产品,支持多方言 SQL 血缘解析。
典型场景
- 数据质量控制:追踪数据源,定位数据错误。
- 合规性审计:检查数据访问和加工链条。
- 优化数据依赖:清晰了解表和任务的依赖关系,提升处理效率。
总结
数据血缘通过建立清晰的链路图,帮助数据开发、治理和分析团队高效理解和管理复杂的数据环境。其实现需要综合利用 SQL 解析、图数据库和调度框架,是数据学院重要的课程内容。 在 Flink 中处理数据血缘关系时,可以结合数据流和 SQL 血缘解析来追踪数据的来源与流向。核心方法如下:
-
数据流追踪:
- Flink 的数据流通过操作链记录数据的处理路径。每个算子(如
map或reduce)都记录数据来源和目标流,形成数据血缘链条。 - 可以使用 Flink 的
ExecutionGraph或任务日志分析上下游依赖。
- Flink 的数据流通过操作链记录数据的处理路径。每个算子(如
-
SQL 血缘解析:
- Flink SQL 基于 Apache Calcite 进行解析,生成 AST(抽象语法树),然后通过遍历 AST 获取表与字段之间的血缘关系。
- 可在表与字段级别追踪 SQL 数据血缘。例如,
CREATE TABLE B AS SELECT id FROM A可解析表 A 的字段id流向表 B。
-
血缘存储:
- 对于复杂的血缘关系,建议使用图数据库(如 Neo4j 或 JanusGraph)存储血缘信息。
- 这样可以通过图查询快速获取数据的上下游关系。
-
实时更新:
- 在 Flink 的流处理任务中,可以通过元数据捕获和解析动态更新血缘关系,并将其存储到元数据管理系统。
-
可视化与查询:
- 使用工具(如 Apache Atlas 或 DataHub)与 Flink 集成,实现血缘信息的可视化展示。
- 提供 REST API 或自定义查询语言以支持用户交互。