StarRocks 的 例行加载(Routine Load) 是一种强大的功能,用来将数据从 Apache Kafka 或类似的流式数据源(例如 Redpanda)持续加载到 StarRocks 的表中。🎯
它的特点包括:
-
实时流数据处理:自动将 Kafka 主题中的数据消费并插入到 StarRocks 表中,无需手动干预。
-
高效性:支持 JSON、CSV 等多种格式,并可以自定义加载字段,确保数据的高效处理。
-
灵活性:通过参数设置可以选择从特定偏移量开始加载,甚至可以只加载新数据。
这种加载方式特别适合需要实时更新的场景,比如网站点击流数据分析或交易数据监控。
共享数据(Shared-Data)
该文档介绍了如何使用 共享数据(Shared-Data)架构 结合远程存储系统(如 MinIO、Amazon S3 等),在 StarRocks 部署中实现存储与计算分离。它详细描述了通过本地缓存的方式,在热点数据被命中时,查询性能能媲美存储计算耦合架构。
内容包括使用 Docker Compose 启动 StarRocks、Redpanda 和 MinIO,将 MinIO 配置为 StarRocks 的存储层,以及在共享数据模式下配置 StarRocks。文档还展示了如何创建例行加载(Routine Load)任务,从 Redpanda 消费流式数据,并将其插入到表中以进行分析。
前置条件
Docker
- Docker
- 4 GB RAM assigned to Docker
- 10 GB free disk space assigned to Docker
SQL client
You can use the SQL client provided in the Docker environment, or use one on your system. Many MySQL-compatible clients will work, and this guide covers the configuration of DBeaver and MySQL Workbench.
curl
curl is used to download the Compose file and the script to generate the data. Check to see if you have it installed by running curl or curl.exe at your OS prompt. If curl is not installed, get curl here.
Python
Python 3 and the Python client for Apache Kafka, kafka-python, are required.
术语
-
FE(Frontend 节点):负责元数据管理、客户端连接、查询计划和调度。每个 FE 节点在内存中存储完整的元数据副本,确保服务一致性。
-
CN(Compute 节点):在共享数据部署中,这些节点专注于执行查询计划,负责计算任务。
-
BE(Backend 节点):在非共享数据部署中,BE 同时负责数据存储和查询计划的执行。
note This guide does not use BEs, this information is included here so that you understand the difference between BEs and CNs.
Launch StarRocks
下载docker-compose.yml文件
|
|
下载gen.py
|
|
启动 StarRocks, MinIO, and Redpanda
|
|
运行 docker compose ps 直到服务都健康:
|
|
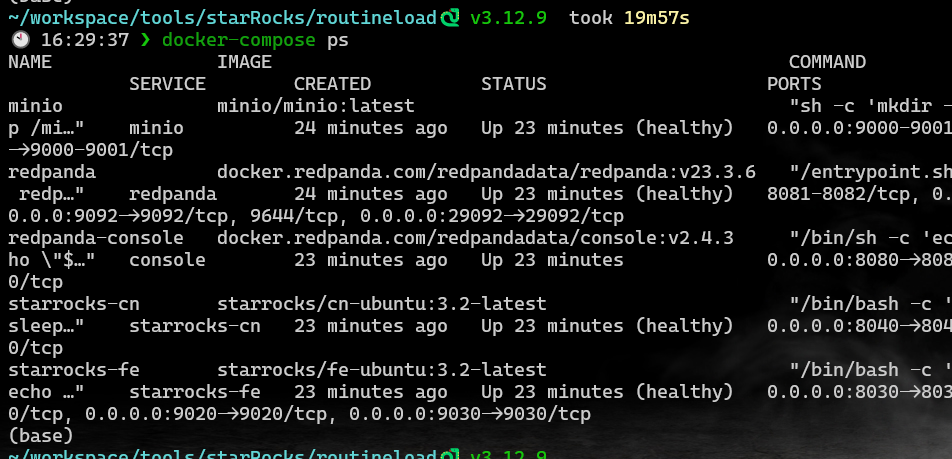 为了使用 MinIO 对象存储与 StarRocks 集成,需要在 MinIO 启动过程中生成一个访问密钥。这段内容说明了验证密钥是否存在的步骤:
为了使用 MinIO 对象存储与 StarRocks 集成,需要在 MinIO 启动过程中生成一个访问密钥。这段内容说明了验证密钥是否存在的步骤:
-
打开 MinIO Web 界面:
- 访问 http://localhost:9001/access-keys。
- 用户名和密码可在 Docker Compose 文件中找到,分别为
miniouser和miniopassword。
-
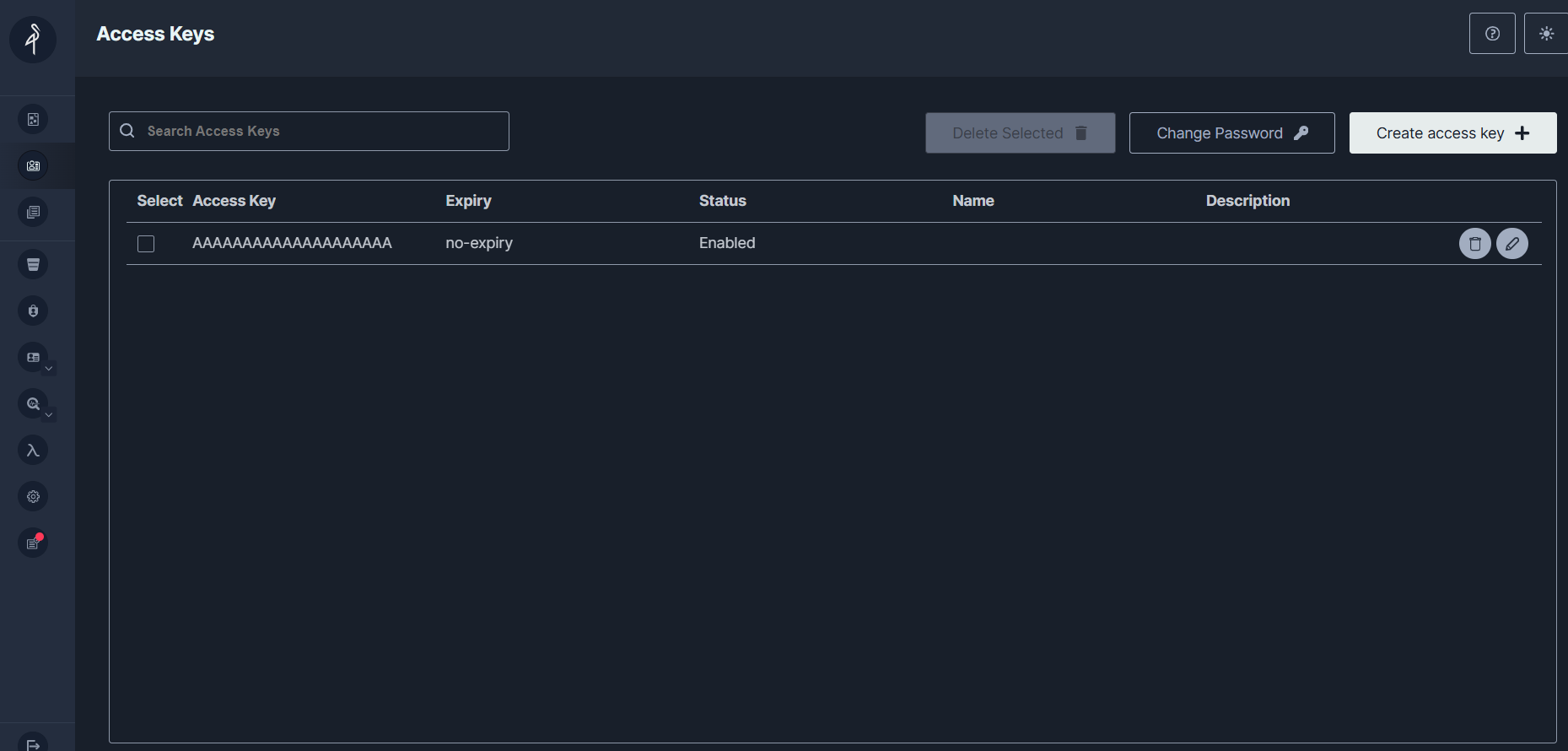
检查访问密钥:
- 页面上会显示一个访问密钥
AAAAAAAAAAAAAAAAAAAA。 - 密钥的秘密部分无法在 MinIO 控制台中看到,但可在 Docker Compose 文件中找到,其值为
BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB。
- 页面上会显示一个访问密钥
 关于 SQL 客户端,本教程验证了以下三种工具的兼容性,你只需要选择其中一个:
关于 SQL 客户端,本教程验证了以下三种工具的兼容性,你只需要选择其中一个:
- mysql CLI:可以直接在 Docker 环境或你的机器上运行。
- DBeaver:提供社区版和专业版,功能强大且易用。
- MySQL Workbench:流行的图形化客户端,方便直观。
DBeaver
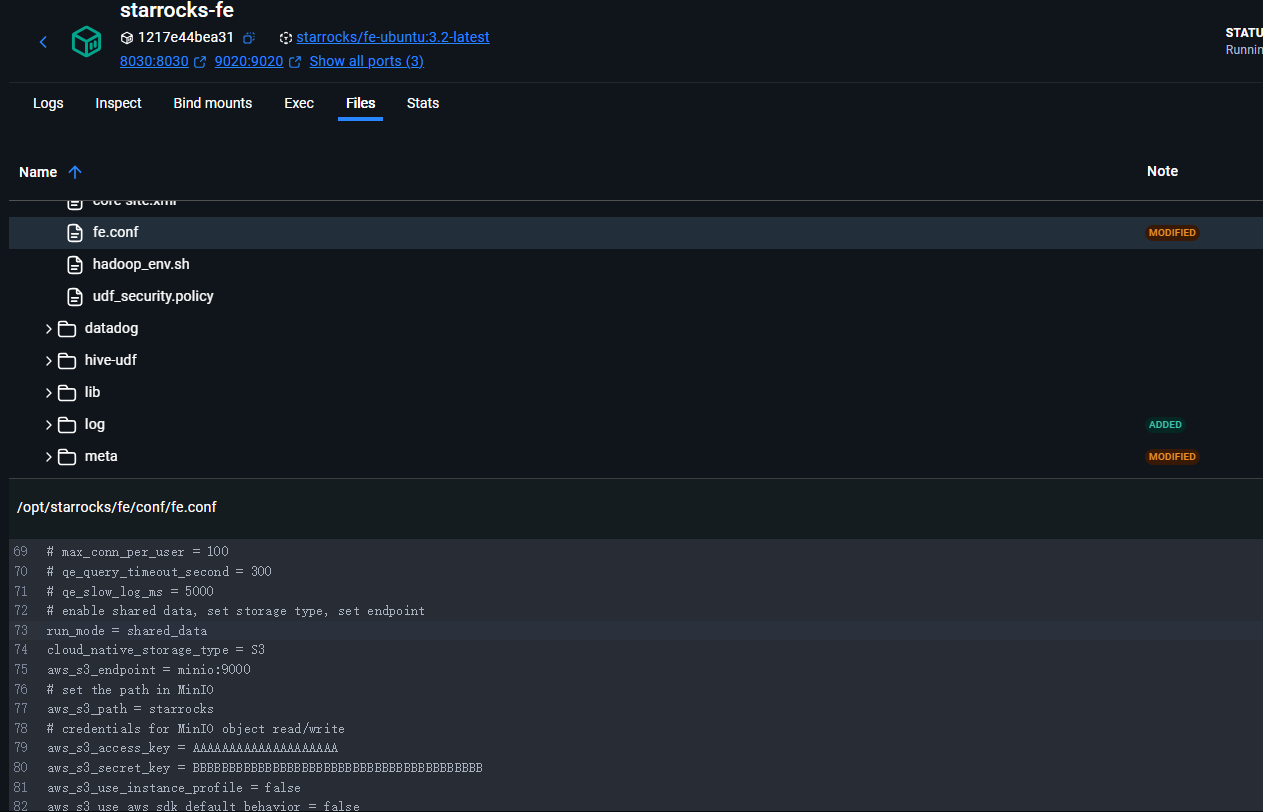
 在共享数据配置中,你已经启动了 StarRocks、Redpanda 和 MinIO,并成功建立了连接。以下是关键设置:
在共享数据配置中,你已经启动了 StarRocks、Redpanda 和 MinIO,并成功建立了连接。以下是关键设置:
- 访问密钥:MinIO 的访问密钥用于连接 StarRocks 和 MinIO。
- 启动过程:StarRocks 在启动时与 MinIO 连接,并在 MinIO 中创建了默认存储卷。
- 运行模式:配置
run_mode为shared_data,表示启用了存储与计算分离。 - 存储类型:通过设置
cloud_native_storage_type为S3,表明使用的是兼容 S3 的存储,比如 MinIO。 - 端点与访问:MinIO 的端点为
minio:9000,访问路径为starrocks。
Connect to StarRocks with a SQL client
|
|
检查存储
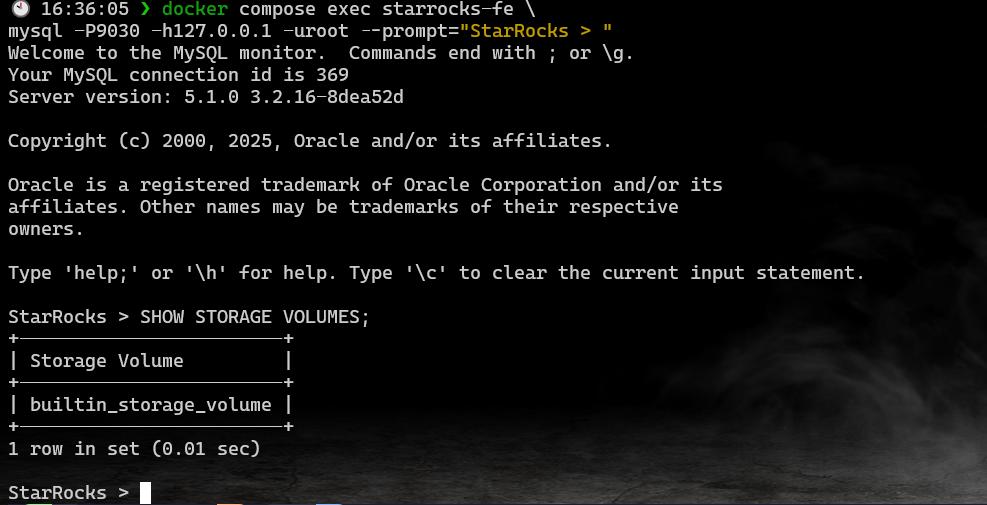

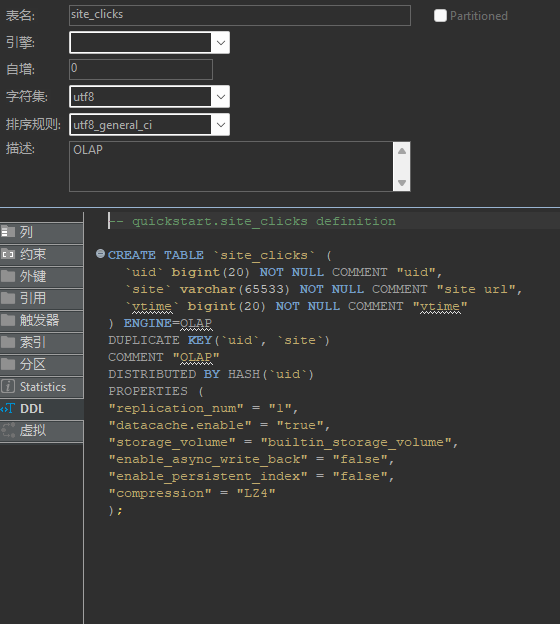
创建表
|
|
Open the Redpanda Console
There will be no topics yet, a topic will be created in the next step.
http://localhost:8080/overview
接下来发送数据到redpanda
|
|

在redpanda上看看对应的topic
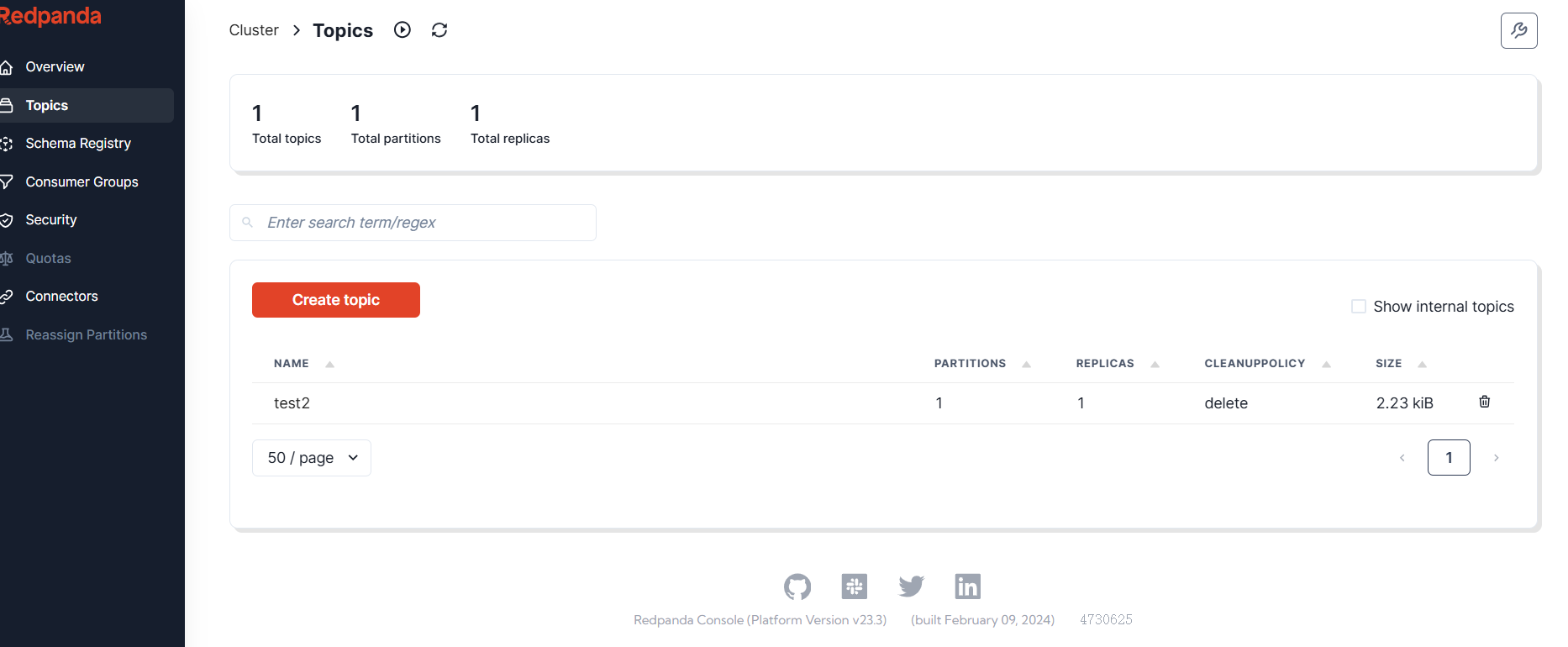
接下来消费数据展示
在 StarRocks 中,你可以创建一个 例行加载任务(Routine Load Job),用于从 Redpanda 的 test2 主题中消费消息,并将这些消息加载到 StarRocks 的 site_clicks 表中,同时将数据存储到 MinIO 中。下面是具体说明:
-
任务目的:
- 消费来自 Kafka(或 Redpanda)的流式数据。
- 将这些消息加载到指定的表(例如
site_clicks)中。
-
存储配置:
- StarRocks 配置为使用 MinIO 作为存储层,所以插入到
site_clicks表中的数据将存储在 MinIO 中。
- StarRocks 配置为使用 MinIO 作为存储层,所以插入到
-
SQL 命令:
- 创建例行加载任务的命令如下:
该命令指定了数据格式(JSON)、字段路径,以及 Kafka 消息的来源配置(主题
1 2 3 4 5 6 7 8 9 10 11CREATE ROUTINE LOAD quickstart.clicks ON site_clicks PROPERTIES ( "format" = "JSON", "jsonpaths" = "[\"$.uid\",\"$.site\",\"$.vtime\"]" ) FROM KAFKA ( "kafka_broker_list" = "redpanda:29092", "kafka_topic" = "test2", "kafka_partitions" = "0", "kafka_offsets" = "OFFSET_BEGINNING" );test2和起始偏移量OFFSET_BEGINNING)。
- 创建例行加载任务的命令如下:
Verify the Routine Load job
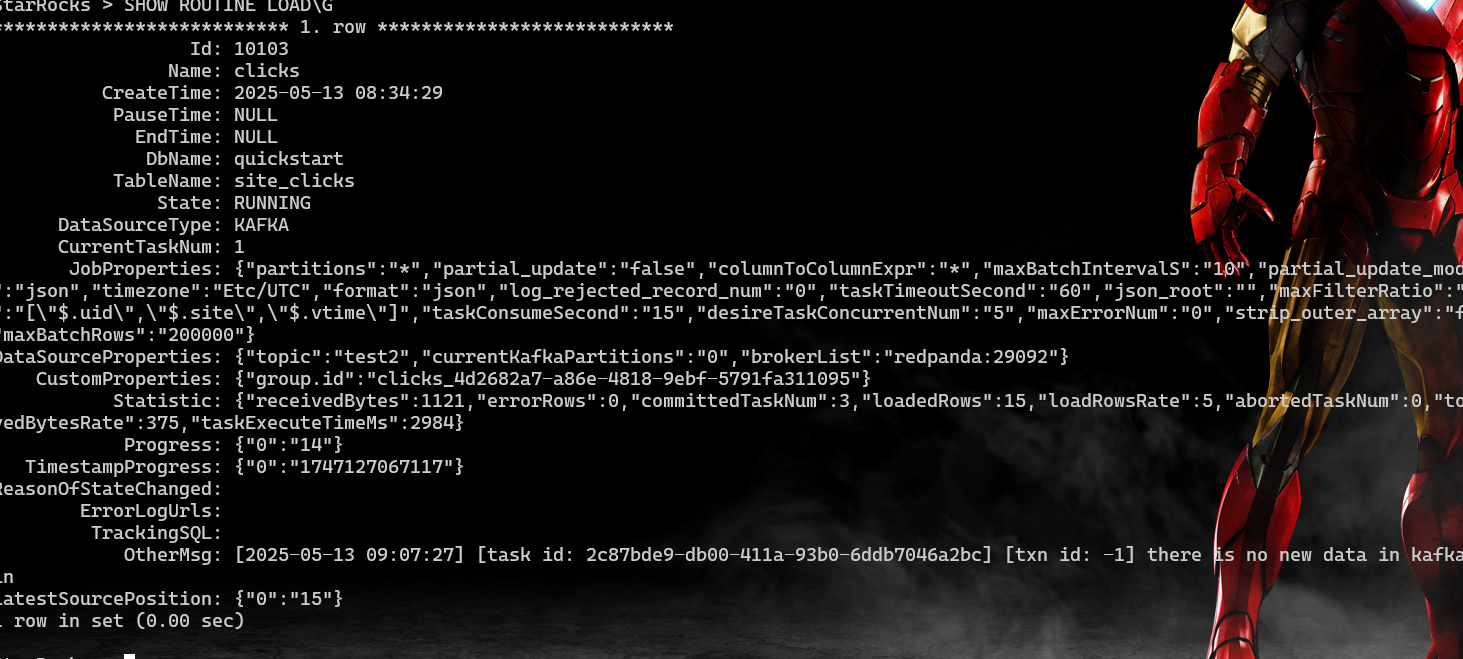
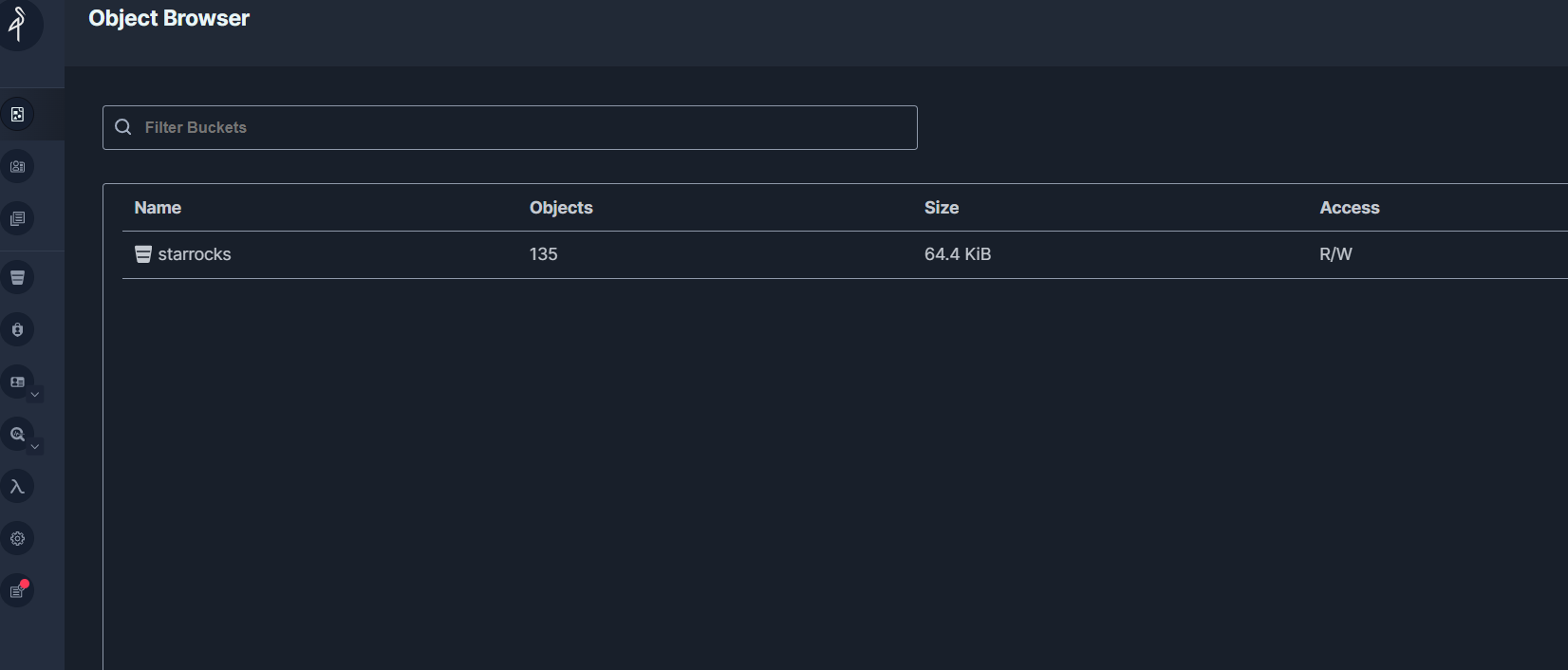
Verify that data is stored in MinIO
Open MinIO http://localhost:9001/browser/ and verify that there are objects stored under starrocks.
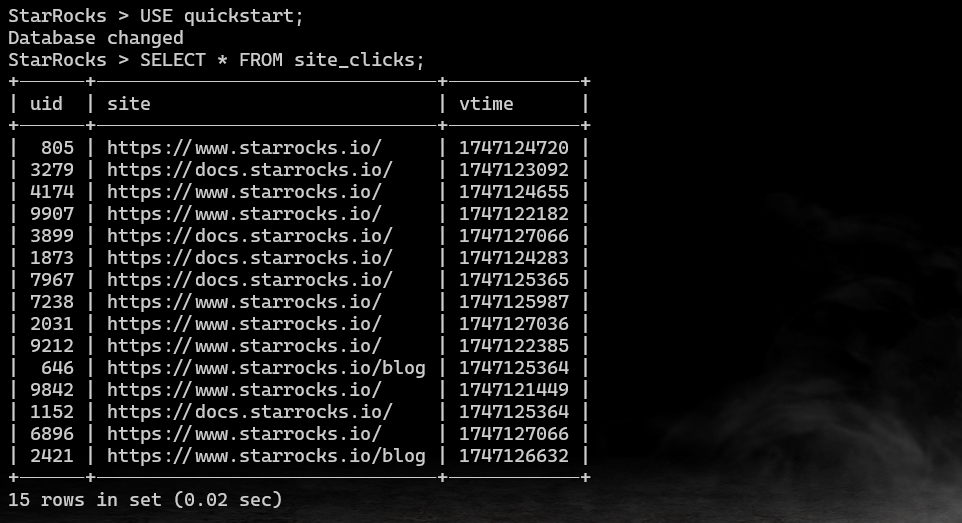
 在sql中查询一下:
在sql中查询一下:
 这里还需要注意一些参数的设定
这里还需要注意一些参数的设定
Configuration details
Now that you have experienced using StarRocks with shared-data it is important to understand the configuration.
CN configuration
The CN configuration used here is the default, as the CN is designed for shared-data use. The default configuration is shown below. You do not need to make any changes.
|
|
FE configuration
The FE configuration is slightly different from the default as the FE must be configured to expect that data is stored in Object Storage rather than on local disks on BE nodes.
The docker-compose.yml file generates the FE configuration in the command section of the starrocks-fe service.
|
|
note
This config file does not contain the default entries for an FE, only the shared-data configuration is shown.
The non-default FE configuration settings:
note
Many configuration parameters are prefixed with s3_. This prefix is used for all Amazon S3 compatible storage types (for example: S3, GCS, and MinIO). When using Azure Blob Storage the prefix is azure_.
run_mode=shared_data
This enables shared-data use.
cloud_native_storage_type=S3
This specifies whether S3 compatible storage or Azure Blob Storage is used. For MinIO this is always S3.
aws_s3_endpoint=minio:9000
The MinIO endpoint, including port number.
aws_s3_path=starrocks
The bucket name.
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
The MinIO access key.
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
The MinIO access key secret.
aws_s3_use_instance_profile=false
When using MinIO an access key is used, and so instance profiles are not used with MinIO.
aws_s3_use_aws_sdk_default_behavior=false
When using MinIO this parameter is always set to false.
enable_load_volume_from_conf=true
When this is true, a StarRocks storage volume named builtin_storage_volume is created using MinIO object storage, and it is set to be the default storage volume for the tables that you create.
Notes on the Routine Load command
StarRocks Routine Load takes many arguments. Only the ones used in this tutorial are described here, the rest will be linked to in the more information section.
|
|
Parameters
|
|
The parameters for CREATE ROUTINE LOAD ON are:
- database_name.job_name
- table_name
database_name is optional. In this lab, it is quickstart and is specified.
job_name is required, and is clicks
table_name is required, and is site_clicks
Job properties
Property format
|
|
In this case, the data is in JSON format, so the property is set to JSON. The other valid formats are: CSV, JSON, and Avro. CSV is the default.
Property jsonpaths
|
|
The names of the fields that you want to load from JSON-formatted data. The value of this parameter is a valid JsonPath expression. More information is available at the end of this page.
Data source properties
kafka_broker_list
|
|
Kafka’s broker connection information. The format is <kafka_broker_name_or_ip>:<broker_ port>. Multiple brokers are separated by commas.
kafka_topic
|
|
The Kafka topic to consume from.
kafka_partitions and kafka_offsets
|
|
These properties are presented together as there is one kafka_offset required for each kafka_partitions entry.
kafka_partitions is a list of one or more partitions to consume. If this property is not set, then all partitions are consumed.
kafka_offsets is a list of offsets, one for each partition listed in kafka_partitions. In this case the value is OFFSET_BEGINNING which causes all of the data to be consumed. The default is to only consume new data.