1. OpenTelemetry介绍
OpenTelemetry 是一个可观测性框架和工具包, 旨在创建和管理遥测数据,如链路、 指标和日志。 重要的是,OpenTelemetry 是供应商和工具无关的,这意味着它可以与各种可观测性后端一起使用, 包括 Jaeger 和 Prometheus 这类开源工具以及商业化产品。
OpenTelemetry 不是像 Jaeger、Prometheus 或其他商业供应商那样的可观测性后端。 OpenTelemetry 专注于遥测数据的生成、采集、管理和导出。 OpenTelemetry 的一个主要目标是, 无论应用程序或系统采用何种编程语言、基础设施或运行时环境,你都可以轻松地将其仪表化。 重要的是,遥测数据的存储和可视化是有意留给其他工具处理的。
什么是可观测性?
可观测性是通过检查系统输出来理解系统内部状态的能力。 在软件的背景下,这意味着能够通过检查遥测数据(包括链路、指标和日志)来理解系统的内部状态。
要使系统可观测,必须对其进行仪表化。也就是说,代码必须发出链路、指标或日志。 然后,仪表化的数据必须发送到可观测性后端。
为什么选择 OpenTelemetry?
随着云计算、微服务架构的兴起和日益复杂的业务需求,软件和基础设施的可观测性需求比以往任何时候都要强烈。
OpenTelemetry 满足可观测性的需求,并遵循两个关键原则:
- 你所生成的数据归属于你自己,不会被供应商锁定。
- 你只需要学习一套 API 和约定。
这两个原则的结合赋予团队和组织在当今现代计算世界中所需的灵活性。
如果你想了解更多信息,请查阅 OpenTelemetry 的使命、愿景和价值观。
主要的 OpenTelemetry 组件
OpenTelemetry 包括以下主要组件:
- 适用于所有组件的规范
- 定义遥测数据形状的标准协议
- 为常见遥测数据类型定义标准命名方案的语义约定
- 定义如何生成遥测数据的 API
- 实现规范、API 和遥测数据导出的语言 SDK
- 实现常见库和框架的仪表化的库生态系统
- 可自动生成遥测数据的自动仪表化组件,无需更改代码
- OpenTelemetry Collector:接收、处理和导出遥测数据的代理
- 各种其他工具, 如用于 Kubernetes 的 OpenTelemetry Operator、 OpenTelemetry Helm Charts 和 FaaS 的社区资产
OpenTelemetry 广泛应用于许多已集成 OpenTelemetry 提供默认可观测性的库、服务和应用。
OpenTelemetry 得到众多供应商的支持,其中许多为 OpenTelemetry 提供商业支持并直接为此项目做贡献。
可扩展性
OpenTelemetry 被设计为可扩展的。一些扩展 OpenTelemetry 的例子包括:
- 向 OpenTelemetry Collector 添加接收器以支持来自自定义源的遥测数据
- 将自定义仪表化库加载到 SDK 中
- 创建适用于特定用例的 SDK 或 Collector 的分发
- 为尚不支持 OpenTelemetry 协议(OTLP)的自定义后端创建新的导出器
- 为非标准上下文传播格式创建自定义传播器
尽管大多数用户可能不需要扩展 OpenTelemetry,但此项目几乎每个层面都可以实现扩展。
历史
OpenTelemetry 是云原生计算基金会 (CNCF)的一个项目,是由 OpenTracing 和 OpenCensus 项目合并而成的。原来这两个项目都是为解决同样的问题而创建的: 缺乏一种标准的方法来为代码进行仪表化并将遥测数据发送到可观测性后端。 由于这两个项目都无法独立解决这个问题,所以将其合并成立了 OpenTelemetry, 吸收了双方的优势,提供了统一的解决方案。
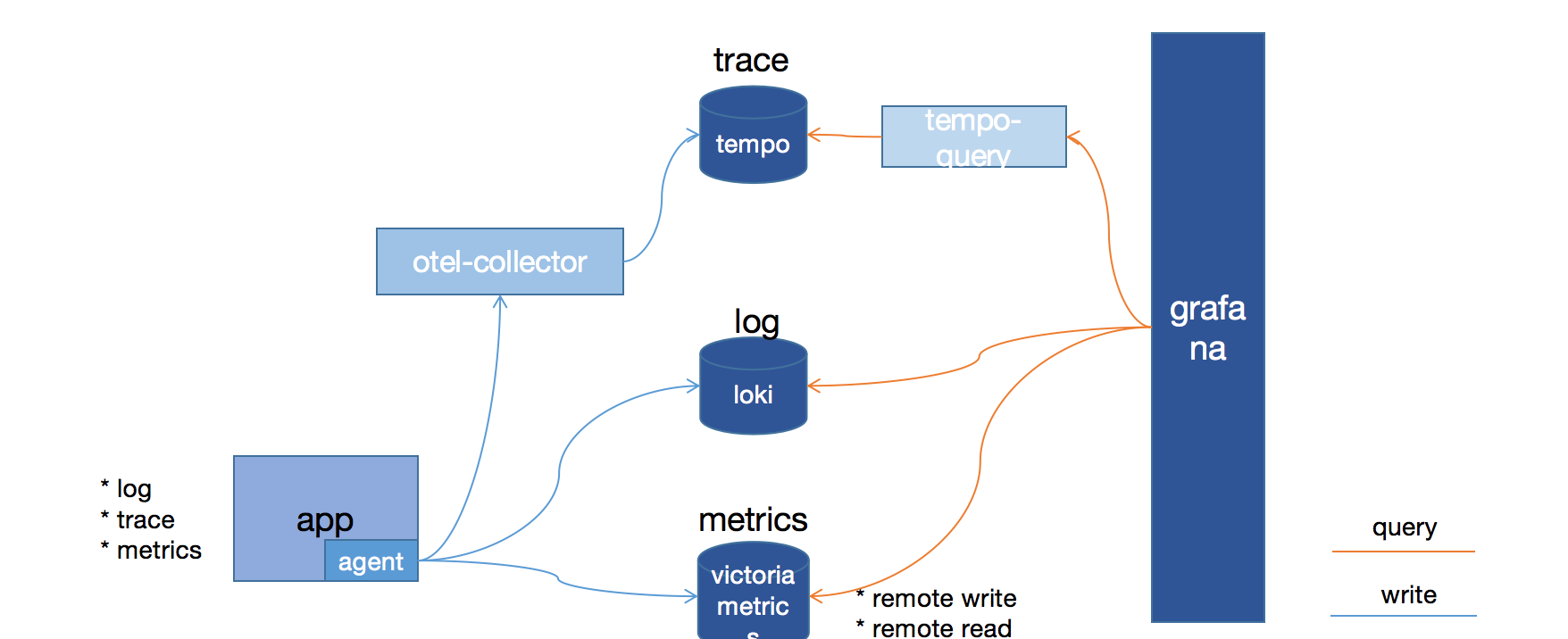
通过instrument-agent注入traceid
- 在log的pattern中加上
%X,如: - 打印出来的日志sample:
2022-08-01 17:39:11.735 trace_id=de6441b0701b34536d51b6333e95b0af, trace_flags=01, span_id=180fff77be7955ad [http-nio-8080-exec-1] INFO com.controller.VersionController [] - i am log.
接下来是操作步骤了:
2 通过helm安装opentelemetry-operator
2.1 添加helm chart:
|
|
更新chart:
|
|
2.2 开始安装
创建namespace:opentelemetry-operator-system 安装命令如下:
|
|
可以看到安装了:
- pod为opentelemetry-operator-controller-manager
- 两个service:
- opentelemetry-operator-controller-manager-metrics-service
- opentelemetry-operator-webhook-service
kubectl get all -n opentelemetry-operator-system|grep opentelemetry

2.3 安装CRD Instrumentation
传统的Instrumentation,需要我们在jar启动的时候加上-javaagent。如果我们使用Custom Resource = Instrumentation的定义文件,可以自动的kubernetes运行时,给我们的应用程序pod加上-javaagent,从而使得我们的应用程序可以自动生成traceId,并发送给collector。
需要做两个配置:
-
- 配置CRD,Kind=Instrumentation。
-
- 在我们的pod yaml定义中加上annotation:
instrumentation.opentelemetry.io/inject-java: "true"。
- 在我们的pod yaml定义中加上annotation:
首先,新建一个文件,叫instrumentation.yaml,spec中可以定义:
exporter: 这里定义的exporter,即我们在下一章(#5)生成的collector的service name,如果是不同的namespace下,需要写http://.:4317。propagator:无侵入式Trace上下文传播类型,可选tracecontext, baggage, b3等等。(具体可参考:github.com/open-teleme…)。resource:- 可配:addk8sUIDattributes, 值可以为true,表示在span中启用k8s Uids相关的标签。
- 可配:resourceAttributes, 值可以是一些属性如:“Servicename: test"或"Environment: dev”。配上的属性可以在span中包含进来。
sampler:涉及到是否将所有的trace数据都发送给存储的后端(如Tempo)。类型有很多,如:always_on, always_off, traceidratio, parentbased_always_on…- 官网文档参考:github.com/open-teleme…。
- 另外还有一篇文章写的不错:www.aspecto.io/blog/opente…。
|
|

在Kubernetes中安装:
kubectl apply -f instrumentation.yaml -n opentelemetry-operator-system
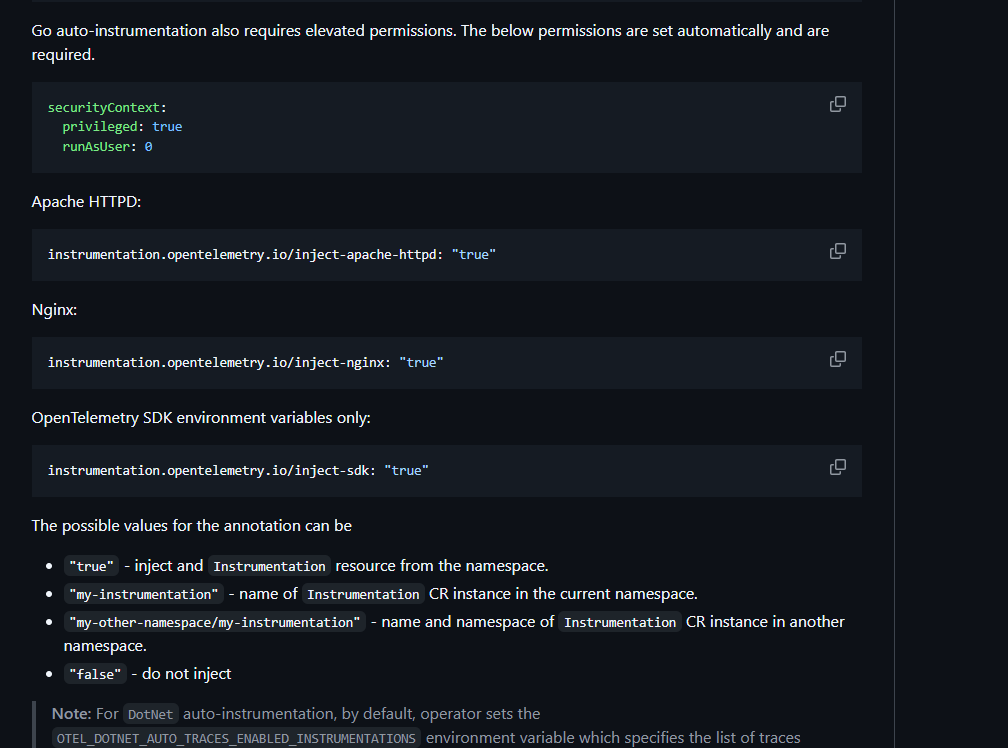
其实,如同上述介绍过,我们需要给我们的Pod yaml定义加上annotation(还支持NodeJS, Python等,这里只列举java的):
instrumentation.opentelemetry.io/inject-java: “true”
值可以为:
true:表示该Pod允许被CRD Instrumentation注入agent,实现trace相关数据的自动生成。Instrumentation需要被安装在同一个namespace下。my-instrumentation:Instrumentation的名字(也需要在同一个namespace下)。主要是为了区别如果同一个namespace下有多个Instrumentation的case。my-other-namespace/my-instrumentation:如果需要引用的Instrumentation不在同一个namespace下,需要显示的指定namespace以及Instrumentation的名字。false:不需要被注入。
这个注解,是为了让部署的应用能正常提交日志到opentelemetry中。
2.4 安装CRD OpenTelemetryCollector
OpenTelemetryCollector将之前的Opentelemetry Collector pipeline的定义(如receivers, processors, exporters)统一整合到当前的CRD中。
其中,.Spec.Mode有三种:
Sidecar:需要在自己的app的pod定义中添加一个annotation,如:sidecar.opentelemetry.io/inject: "Boolean/String",可以配true,意思是在pod中自动配置collector,或是false,意思是不配置。或是当前namespace下有多个OpenTelemetryCollector的时候,这里可以写上想选择的name。DaemonSet,这个模式下不需要添加annotation,但是,这种模式下,同一个namespace下所有的pod都会发送trace信息给这个collector。Deployment(默认),同样的,也需要添加annotation:sidecar.opentelemetry.io/inject。
从设计上来说,我们可以为每个pod各自配置自己的sidecar模式的collector,用来收集各个pod中的trace数据,然后再setup一个daemonset模式的collector,用来收集各个sidecar中的数据。
新建一个文件,叫openTelemetryCollector.yaml:
|
|
注意· endpoint: “http://tempo.monitoring:4317”·是为了能让traceid正常发送到tempo服务中。 可以看到会生成:
- pod:otel-daemonset-collector
-->和exporter的集成,日志在这里看。 - service:
- otel-daemonset-collector
- otel-daemonset-collector-headless
- otel-daemonset-collector-monitoring
- daemonset:otel-daemonset-collector
注意这里的一个坑是image是·otel/opentelemetry-collector-contrib:0.124.1·,这个镜像不存在。所以我采用latest的镜像,然后转化成0.124.1

2.5 安装springboot项目来测试一下
2.5.1 创建一个springboot项目,叫demo
使用springboot的初始项目创建一个demo项目
|
|
[!NOTE] 注意生成的jar包名称
在logback中添加自定义的pattern中,需要设置‘%X’,X可以获取当前的MDC
Spring Boot
For Spring Boot configuration which uses logback, you can add MDC to log lines by overriding only the logging.pattern.level:
|
|
logback.xml:
|
|
The OTel Java agent injects several pieces of information about the current span into each logging event’s MDC copy:
trace_id- the current trace id (same asSpan.current().getSpanContext().getTraceId());span_id- the current span id (same asSpan.current().getSpanContext().getSpanId());trace_flags- the current trace flags, formatted according to W3C traceflags format (same asSpan.current().getSpanContext().getTraceFlags().asHex()). 下面展示一下生成的log样例
|
|
直接使用build.sh脚本来支持一建部署:
这里需要注意的是opentelemetry-operator-system/my-instrumentation是指安装在opentelemertry-operator-system下的instrumentation。
2.5.2 创建user-app项目:
步骤跟上面一样:
 也是通过build.sh 一键创建测试即可。
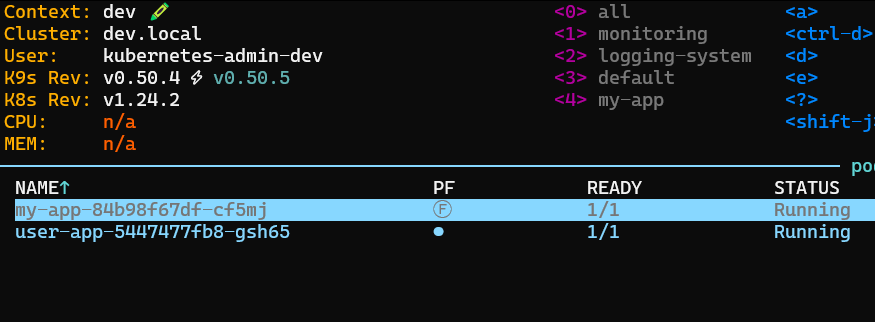
通过k9s可以直接看到部署成功的服务
也是通过build.sh 一键创建测试即可。
通过k9s可以直接看到部署成功的服务
3 安装tempo和grafana服务
|
|
4 接下来在grafana中查看一下
获取grafna的密码如下操作
|
|
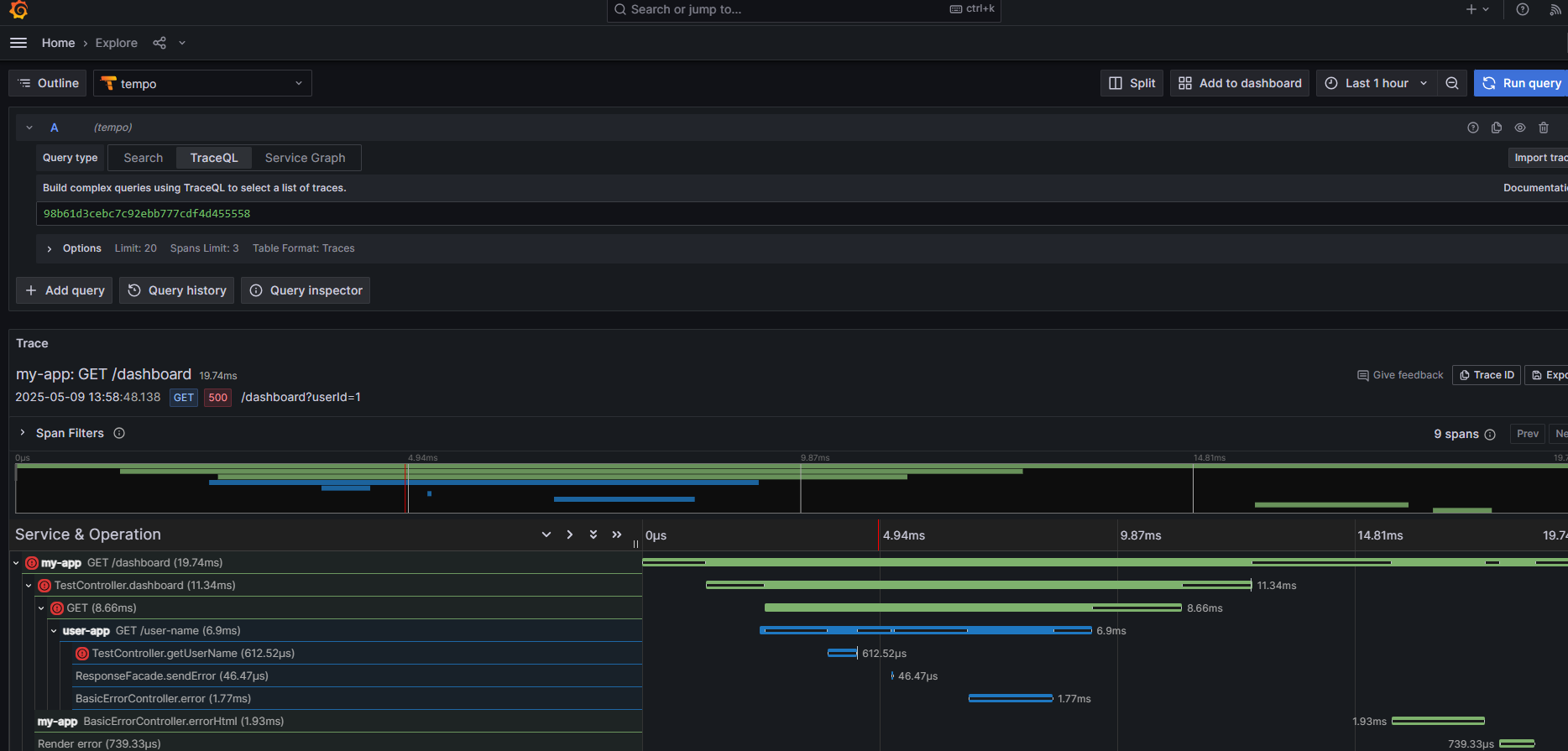
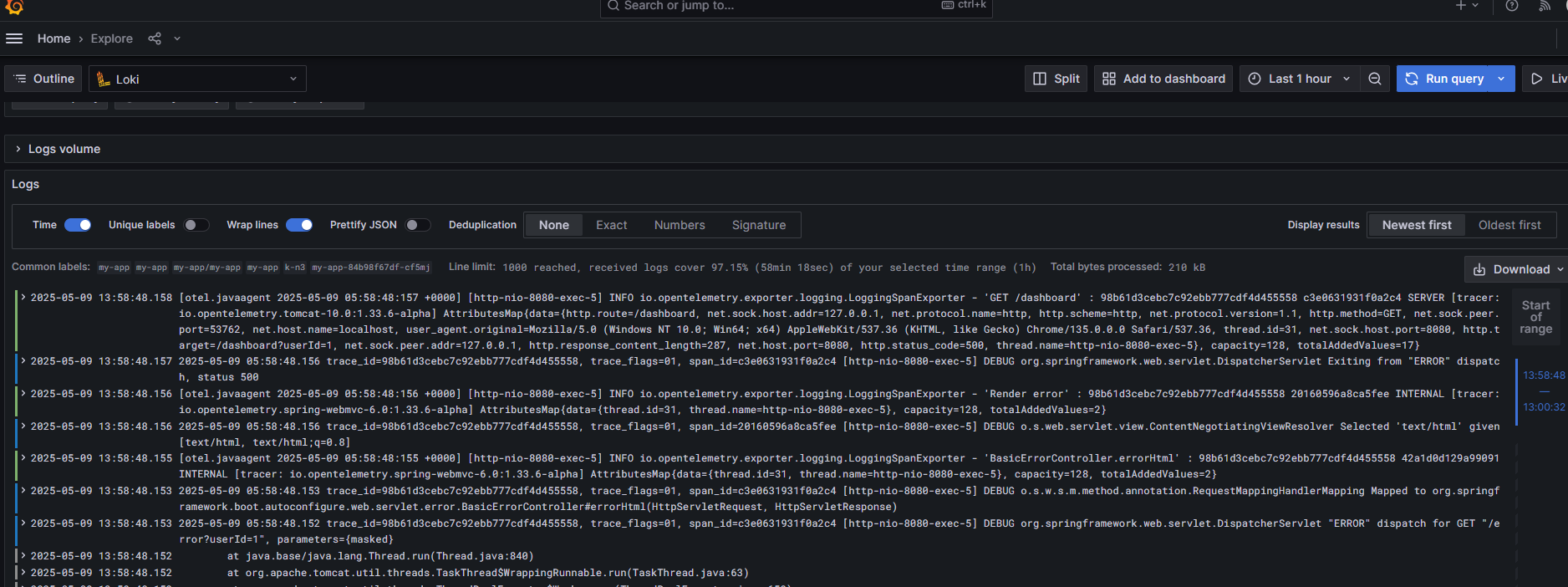 根据traceid在tempo中就可以查询到要的数据流程了
根据traceid在tempo中就可以查询到要的数据流程了