概述:
- 使用docker-compose来部署一下spark、iceberg catalog
- 向iceberg数据湖导入数据
- 配置starrocks访问iceberg catalog
- 使用starrocks查询数据湖中的数据
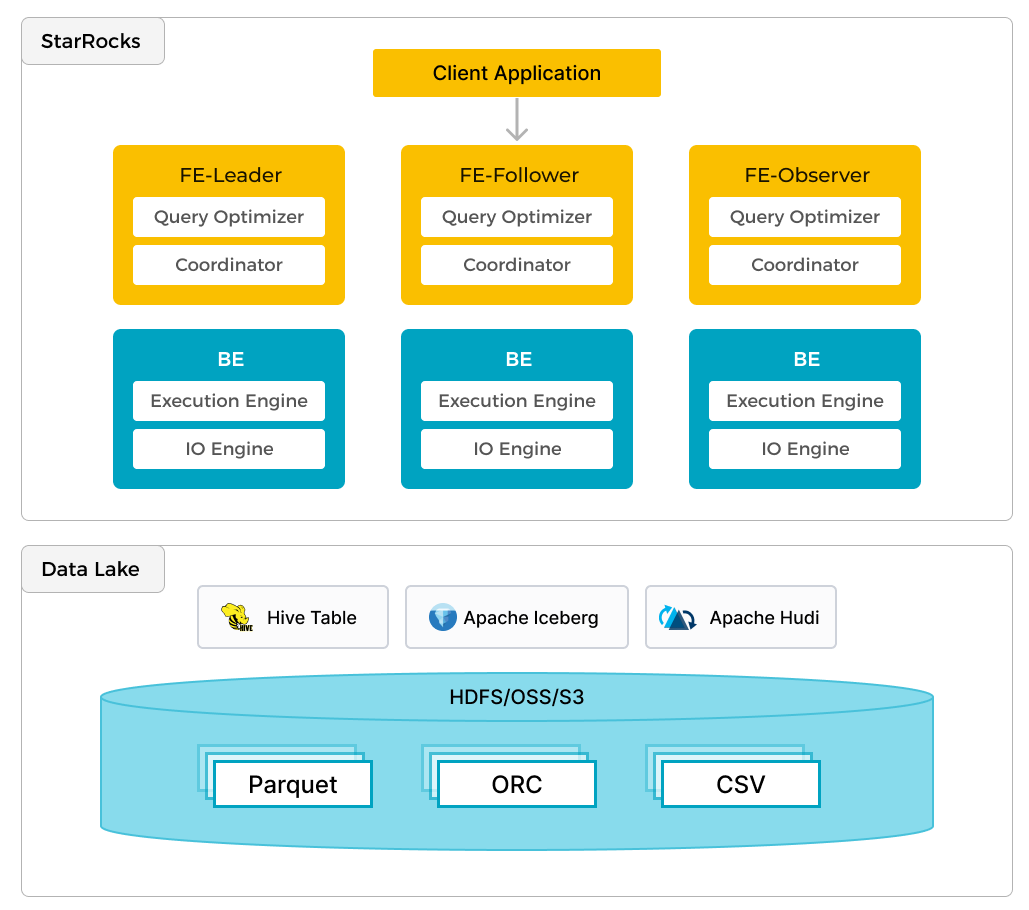
StarRocks 不仅擅长本地数据分析,还可以直接作为计算引擎高效分析数据湖中的数据。通过其 External Catalog 功能,无需迁移即可快速查询存储在 Apache Hive、Iceberg、Hudi、Delta Lake 等数据湖中的数据,并支持多种存储系统(HDFS、S3、OSS)与文件格式(Parquet、ORC、CSV)。
在数据湖分析中,数据湖负责存储和维护,而 StarRocks 负责计算与分析,充分利用向量化引擎和 CBO 的技术优势,大幅提升性能。结合开放的存储格式和灵活的 schema,这种架构确保了 BI、AI 等业务统一的数据源,满足各类场景需求。
CBO,即 Cost-Based Optimizer,是一种查询优化器,主要通过评估不同查询执行计划的成本来选择最佳执行路径。在数据库系统(如 StarRocks)中,CBO 的核心作用是提升查询性能,特别是在复杂的多表关联或大数据量查询场景中。
CBO 的工作原理:
-
成本计算:
- CBO 通过分析每种查询执行计划的资源需求(如 CPU、内存、I/O 开销),计算出每种计划的成本。
-
统计信息支持:
- 借助表的统计信息(如数据行数、列分布情况),CBO 能更准确地预测查询执行的资源开销。
-
选择最优计划:
- CBO 会在多个查询执行方案中,选择预计成本最低的计划来执行,从而显著提高效率。
CBO 的优点:
- 性能提升:能够对查询进行智能优化,减少资源消耗。
- 灵活性高:适合复杂查询场景,如 JOIN、GROUP BY 和子查询。
- 自动化选择:无需手动干预即可生成高效执行计划。
在 StarRocks 中,CBO 是其高性能数据分析能力的关键组件,与向量化引擎结合使用,能够极大地提升分析速度。
前置条件:
containerd
SQL客户端 curl命令
术语
FE
FE 节点负责元数据管理、客户端连接管理、查询计划和查询调度。每个 FE 节点在内存中存储和维护完整的元数据副本,确保每个 FE 都能提供无差别的服务。
CN
CN 节点负责在存算分离或存算一体集群中执行查询。
BE
BE 节点在存算一体集群中负责数据存储和执行查询。使用 External Catalog(例如本教程中使用的 Iceberg Catalog)时,BE 可以用于缓存外部数据,从而达到加速查询的效果。
环境
本教程使用了六个 Docker 容器(服务),均使用 Docker Compose 部署。这些服务及其功能如下:这里我只保留了rest、spark-iceberg,其他服务都是之前本地搭建过的。直接采用本地的。
| 服务 | 功能 |
|---|---|
starrocks-fe |
负责元数据管理、客户端连接、查询规划和调度。 |
starrocks-be |
负责执行查询计划。 |
rest |
提供 Iceberg Catalog(元数据服务)。 |
spark-iceberg |
用于运行 PySpark 的 Apache Spark 环境。 |
mc |
MinIO Client 客户端。 |
minio |
MinIO 对象存储。 |
下载 Docker Compose 文件和数据集
StarRocks 提供了包含以上必要容器的环境的 Docker Compose 文件和教程中需要使用数据集。
本教程中使用的数据集为纽约市绿色出租车行程记录,为 Parquet 格式。
下载 Docker Compose 文件。
|
|
下载数据集。
|
|
再containerd中启动环境
|
|
这里启动报错了,无法使用。 去掉build:spark
PySpark
本教程使用 PySpark 与 Iceberg 交互。如果您不熟悉 PySpark,您可以参考更多信息部分。
拷贝数据集
在将数据导入至 Iceberg 之前,需要将其拷贝到 spark-iceberg 容器中。
运行以下命令将数据集文件复制到 spark-iceberg 容器中的 /opt/spark/ 路径。
|
|
启动 PySpark
运行以下命令连接 spark-iceberg 服务并启动 PySpark。
|
|
导入数据集至 DataFrame 中导入数据集至 DataFrame 中的直接链接
DataFrame 是 Spark SQL 的一部分,提供类似于数据库表的数据结构。
您需要从 /opt/spark 路径导入数据集文件至 DataFrame 中,并通过查询其中部分数据检查数据导入是否成功。
在 PySpark Session 运行以下命令:
|
|
输出结果:
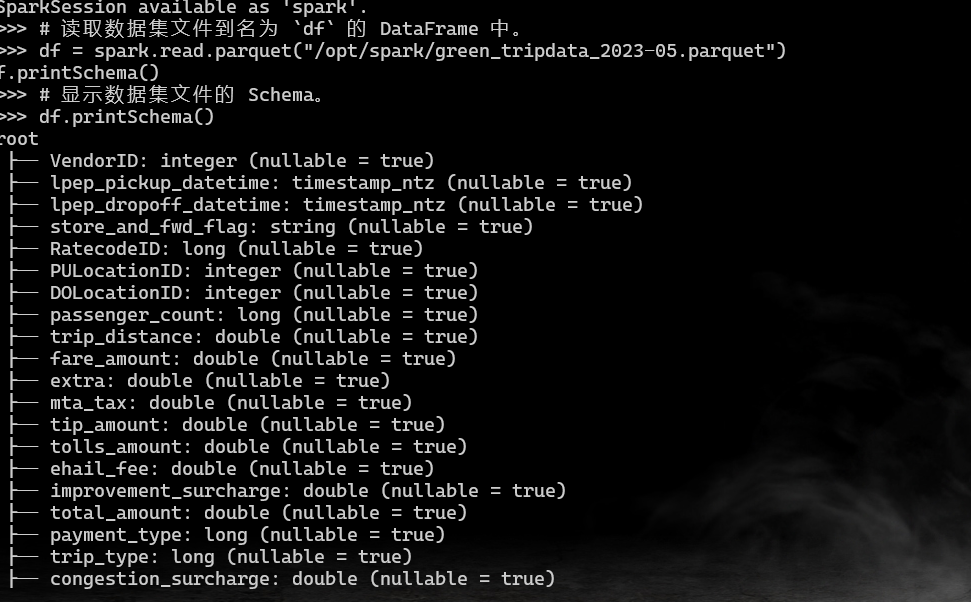
通过查询 DataFrame 中的部分数据验证导入是否成功。
|
|
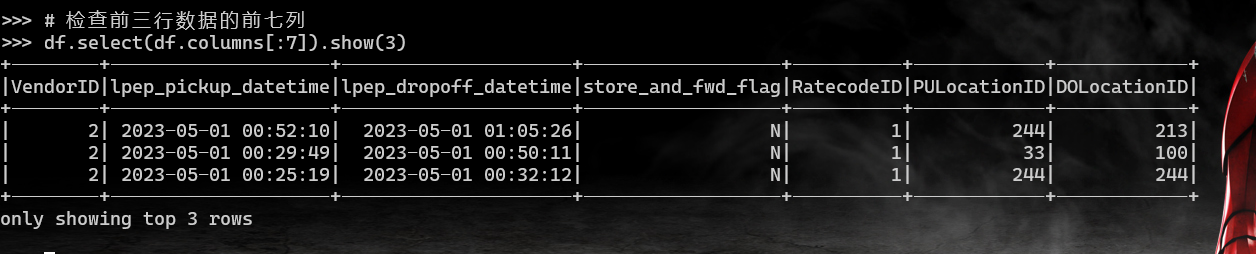
创建 Iceberg 表并导入数据
根据以下信息创建 Iceberg 表并将上一步中的数据导入表中:
- Catalog 名:
demo - 数据库名:
nyc - 表名:
greentaxis
|
|
在此步骤中创建的 Iceberg 表将在下一步中用于 StarRocks External Catalog。
配置 StarRocks 访问 Iceberg Catalog
现在您可以退出 PySpark,并通过您的 SQL 客户端运行 SQL 命令。
使用 SQL 客户端连接到 StarRocks
SQL 客户端
当前教程可以使用以下三个客户端进行测试,您只需选择其中一个:
- MySQL CLI:您可以从 Docker 环境或您的本机运行此客户端。
- DBeaver(社区版或专业版)
- MySQL Workbench
配置客户端
您可以从 StarRocks FE 节点容器 starrocks-fe 中直接运行 MySQL Client:
|
|
这里我们使用Dbeaver来操作连接服务器进行操作:
创建 External Catalog
您可以通过创建 External Catalog 将 StarRocks 连接至您的数据湖。以下示例基于以上 Iceberg 数据源创建 External Catalog。具体配置内容将在示例后详细解释。
|
|
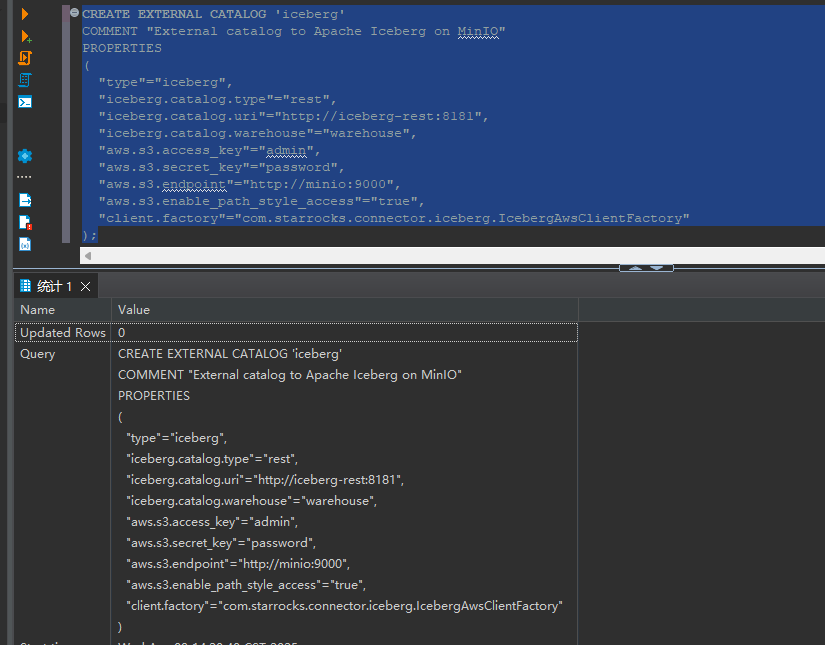
PROPERTIES
| 属性 | 描述 |
|---|---|
type |
数据源的类型,此示例中为 iceberg。 |
iceberg.catalog.type |
Iceberg 集群所使用的元数据服务的类型,此示例中为 rest。 |
iceberg.catalog.uri |
REST 服务器的 URI。 |
iceberg.catalog.warehouse |
Catalog 的仓库位置或标志符。在此示例中,Compose 文件中指定的仓库名称为 warehouse。 |
aws.s3.access_key |
MinIO Access Key。在此示例中,Compose 文件中设置 Access Key 为 admin。 |
aws.s3.secret_key |
MinIO Secret Key。在此示例中,Compose 文件中设置 Secret Key 为 password。 |
aws.s3.endpoint |
MinIO 端点。 |
aws.s3.enable_path_style_access |
是否开启路径类型访问 (Path-Style Access)。使用 MinIO 作为对象存储时,该项为必填。 |
client.factory |
此示例中使用 iceberg.IcebergAwsClientFactory。aws.s3.access_key 和 aws.s3.secret_key 参数进行身份验证。 |
创建成功后,运行以下命令查看创建的 Catalog。
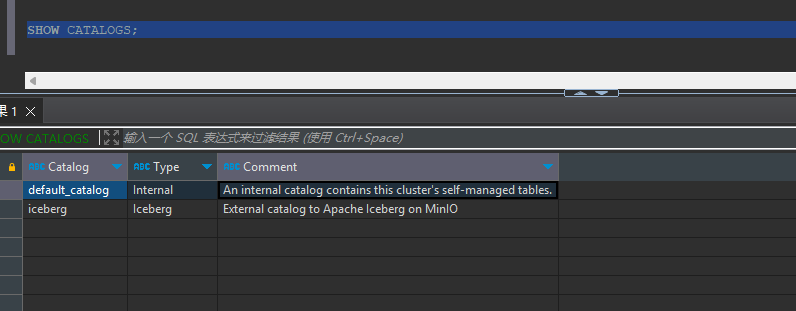
设置当前使用的 Catalog 为 iceberg。
|
|
查看 iceberg 中的数据库。
|
|
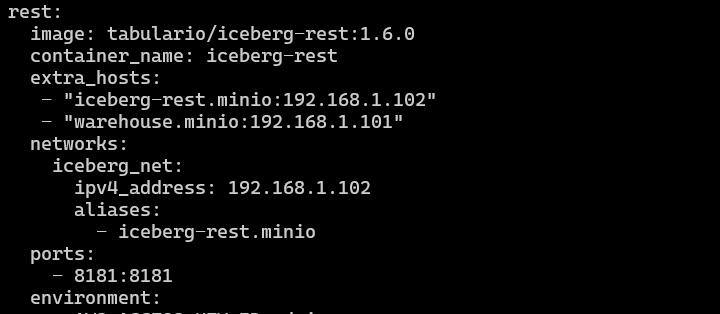
发生了错误,nerdctl compose 启动docker-compose.yaml文件后就失效了,无法再使用了,会卡主。
这里因为containerd的网络是靠cni组起来的,通过docker-compose alias的网络是不一样无法正常映射过去,这里,我采用了配置静态ip+extra——hosts的方式来进行处理,即可。
成功把表写入到catalog之中了。
具体修改如下所示:
继续接下来继续查看数据库了:
 切换至
切换至 nyc 数据库。
|
|
返回:
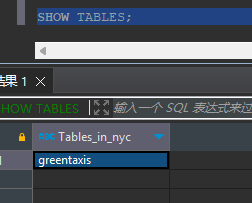 如上图所示,我们可以看到greentaxis的表
如上图所示,我们可以看到greentaxis的表
查看一下表结构
|
|
DESCRIBE greentaxis;
|
|
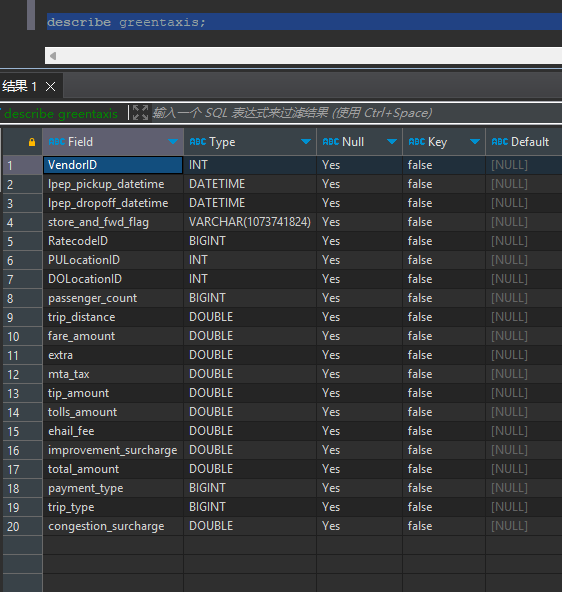 通过比较 StarRocks 返回的 Schema 与之前 PySpark 会话中的
通过比较 StarRocks 返回的 Schema 与之前 PySpark 会话中的 df.printSchema() 的 Schema,可以发现 Spark 中的 timestamp_ntz 数据类型在 StarRocks 中表示为 DATETIME。除此之外还有其他 Schema 转换。
使用 StarRocks 查询 Iceberg
查询接单时间
以下语句查询出租车接单时间,仅返回前十行数据。
|
|
 查看耗时,最后花了24s。docker化的性能真差。
查看耗时,最后花了24s。docker化的性能真差。
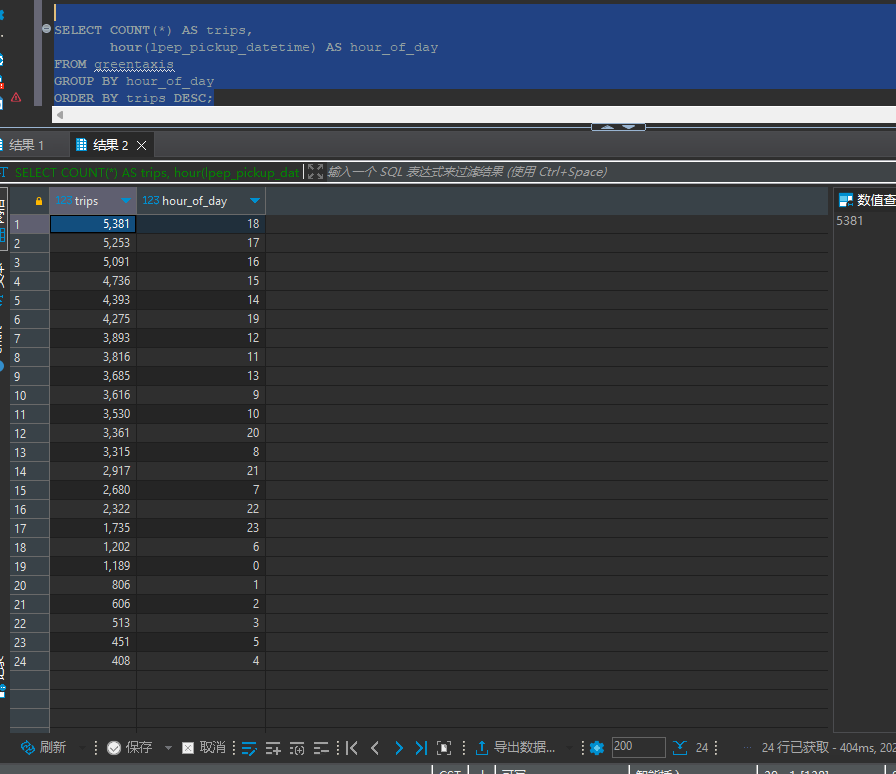
查询接单高峰时期
以下查询按每小时聚合行程数据,计算每小时接单的数量。
|
|