基于rook-ceph的分支为v1.13.2
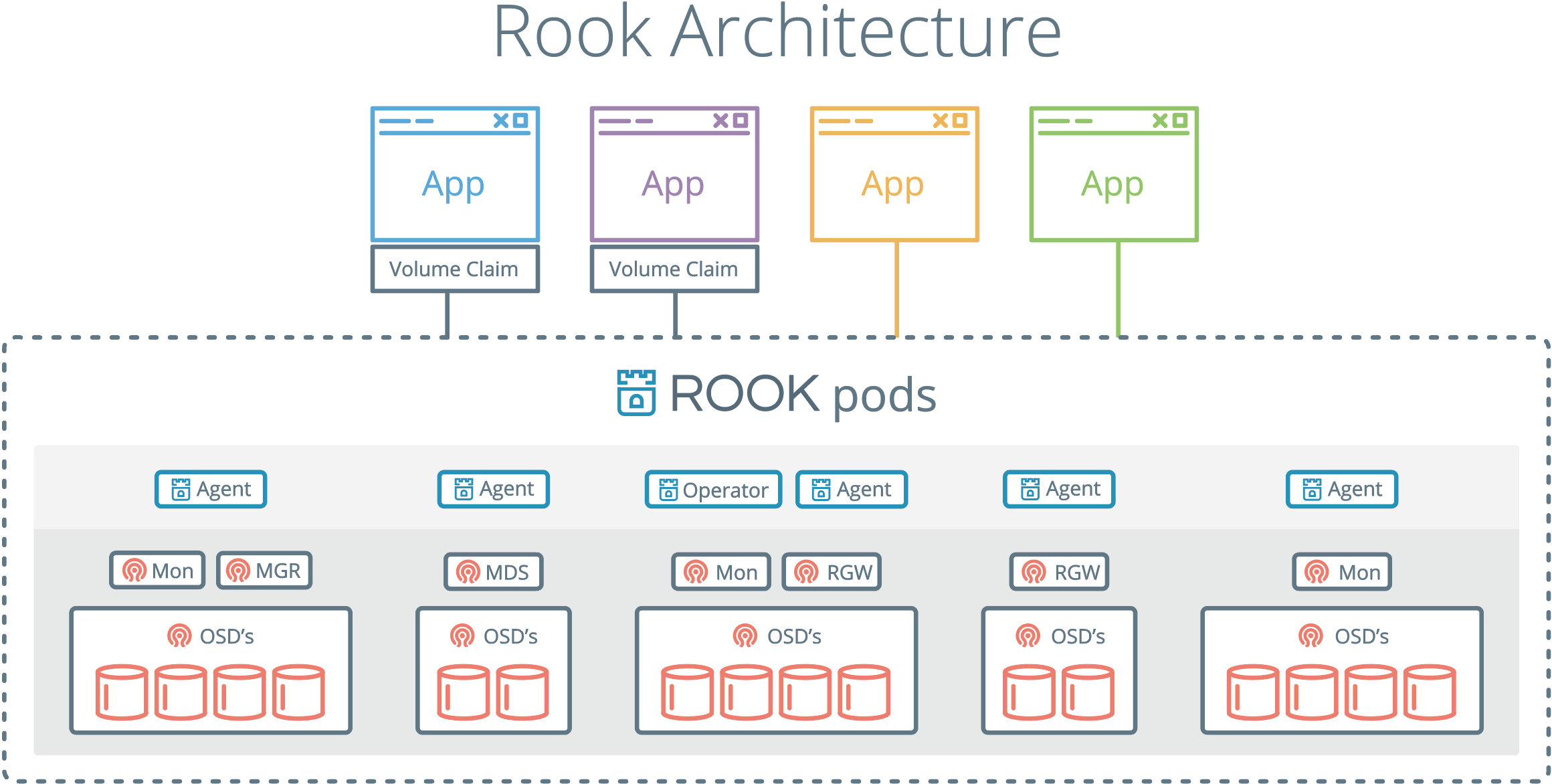
步骤1
准备磁盘来安装ceph 下载rook-ceph的yaml包
$ git clone –single-branch –branch v1.13.2 https://github.com/rook/rook.git 进入目录 cd rook/deploy/examples
注:v1.13.2可以更改为需要安装rook-ceph实际版本
关闭自动发现新增磁盘
vim operator.yaml ROOK_ENABLE_DISCOVERY_DAEMON: “false”
扫描发现磁盘间隔
name: ROOK_DISCOVER_DEVICES_INTERVAL value: “60s” 创建安装工具pod(这一步在步骤2镜像全部下载修改路径后执行)
执行create -f yaml创建operator工具 kubectl create -f crds.yaml -f common.yaml -f operator.yaml 查看创建的pod是否成功 kubectl -n rook-ceph get pod |grep operator
步骤2 查看rook-ceph所需的镜像版本
cat rook/deploy/examples/images.txt
拉取所需的镜像 镜像有两种方式,第一种直接拉取到本地的docker images 存放(docker pull),第二种拉取到harbor仓库统一管理。
示例:
本次采用通过拉取镜像存放到harbor仓库,这里不做过多叙述。
修改yaml的image路径为实际harbor的路径
vi /root/rook/deploy/examples/cluster.yaml ![[{26787234-DA89-4D38-A4B1-A772037D3BFD}.png]]
vi /root/rook/deploy/examples/operator.yaml ![[{3F4A1DF9-F5B3-4E76-B314-5967BA0F1C6C}.png]]
修改cluster.yaml的参数
vi /root/rook/deploy/examples/cluster.yaml
修改useAllNodes和useAllDevices的true为false storage: # cluster level storage configuration and selection useAllNodes: false useAllDevices: false #useAllNodes: true 表示将使用集群中的所有节点作为存储节点。这意味着存储将在集群中的每个节点上进行分布,以提供更好的容量和冗余。(比如有5台节点,只需要其中三台作为存储节点) #useAllDevices: true 表示将使用节点上的所有设备作为存储设备。这包括节点上的所有硬盘、SSD 或其他可用的存储设备。通过使用所有设备,可以最大化存储资源的利用和性能。
添加OSD主机和主机磁盘
vi /root/rook/deploy/examples/cluster.yaml ![[{108521D1-2CCE-493D-B3BB-9583B515BB4A}.png]]
创建ceph集群
kubectl create -f cluster.yaml
安装管理工具
kubectl create -f toolbox.yaml -n rook-ceph
进入管理工具查看ceph状态
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – bash
ceph -s
安装ceph dashboard
选择创建http或https
kubectl apply -f dashboard-external-https.yaml kubectl apply -f dashboard-external-http.yaml
账户admin,获取密码
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath=“{[‘data’][‘password’]}”|base64 –decode && echo
步骤3 使用块存储
创建存储类 kubectl create -f rook/deploy/examples/csi/rbd/storageclass.yaml kubectl get CephBlockPool -n rook-ceph && kubectl get StorageClass | grep rook-ceph-block
创建pv测试 kubectl create -f rook/deploy/examples/csi/rbd/pvc.yaml kubectl create -f rook/deploy/examples/csi/rbd/pod.yaml
注:修改storageclass.yaml里副本为实际
使用文件存储
创建存储类 kubectl apply -f rook/deploy/examples/filesystem.yaml kubectl apply -f rook/deploy/examples/csi/cephfs/storageclass.yaml 创建pvc测试 kubectl apply -f rook/deploy/examples/csi/cephfs/pvc.yaml kubectl apply -f rook/deploy/examples/csi/cephfs/pod.yaml kubectl -n rook-ceph get pod -l app=rook-ceph-mds
注:修改storageclass.yaml里副本为实际
常用命令 kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – bash 进入tools维护ceph kubectl logs -n rook-ceph rook-ceph-operator-123fajd 查看operator部署的日志用于诊OSD激活情况 kubectl -n rook-ceph delete pod -l app=rook-ceph-operator 通过 重启operator新增OSD ceph crash ls 查看错误log ceph crash info <错误> 查看详细错误 ceph crash rm <错误> 删除告警 ceph status #获取 Ceph 存储集群中 OSD 的状态信息 ceph osd status #查看osd的树状结构 ceph osd tree #查看osd详细信息,上一步查出来的,比如0,可以看到那块磁盘<bluestore_bdev_dev_node> ceph osd metadata #获取 Ceph 存储集群的分布式文件系统(CephFS)的容量和使用情况 ceph df 获取 Ceph 存储集群中 RADOS的容量和使用情况。PS:RADOS是 Ceph 存储集群的核心组件,它是一个高度可扩展、分布式的对象存储系统,用于存储和管理 Ceph 存储集群中的数据 rados df #查看osd磁盘信息 ceph mgr module enable rook 开启Rook模块 (新版本rook-ceph存在文件存储写入mon崩溃需要开启rook模块解决) ceph orch set backend rook 设置 orchestrator 后端为rook
排错路径 https://rook.io/docs/rook/latest-release/Getting-Started/intro/
磁盘上下盘操作记录
ceph存储上盘下盘操作
1、定位硬盘和报错日志
#1. 例如更换osd.1硬盘,找出osd.1对应的磁盘
[root@ceph1 mapper]# kubectl get po rook-ceph-osd-1-79fcff4bbd-4gq2b -n rook-ceph -o yaml | grep UUID
k:{“name”:“ROOK_OSD_UUID”}:
- name: ROOK_OSD_UUID
- “\nset -ex\n\nOSD_ID=1\nOSD_UUID=d3483ef7-2ddf-46d9-9f0d-79999b25180d\nOSD_STORE_FLAG="–bluestore"\nOSD_DATA_DIR=/var/lib/ceph/osd/ceph-"$OSD_ID"\nCV_MODE=lvm\nDEVICE=/dev/ceph-4abbbe54-da99-4cac-bdb7-f3ef744ecf78/osd-data-dc8616c1-9c3d-48cc-9eba-937861d419d4\nMETADATA_DEVICE="$ROOK_METADATA_DEVICE"\nWAL_DEVICE="$ROOK_WAL_DEVICE"\n\n#
"$OSD_ID" "$OSD_UUID"\n\n\t# copy the tmpfs directory to a temporary directory\n\t#
[root@ceph2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm
sdb 8:16 0 10G 0 disk
└─ceph–1dbde574–6d46–4378–8e58–3963835c0405-osd–data–12d2a2b5–81c6–467e–b17f–cae8c63ef3f4 253:3 0 10G 0 lvm
sdc 8:32 0 10G 0 disk
└─ceph–4abbbe54–da99–4cac–bdb7–f3ef744ecf78-osd–data–dc8616c1–9c3d–48cc–9eba–937861d419d4 253:2 0 10G 0 lvm
sr0 11:0 1 4.4G 0 rom
2、先把operator设置为0
[root@ceph1 mapper]# kubectl scale deploy -n rook-ceph rook-ceph-operator –replicas=0
deployment.apps/rook-ceph-operator scaled
3、修改配置,将需要移除的盘移除:
[root@ceph1 mapper]# kubectl edit cephcluster -n rook-ceph rook-ceph
cephcluster.ceph.rook.io/rook-ceph edited
- devices:
- name: sdb
- name: sdc (删除)
4、手动移除对应osd
[root@ceph1 ~]# kubectl exec -it -n rook-ceph rook-ceph-tools-6f44db7c58-zw47s bash
ceph osd set noup
ceph osd down 0
ceph osd out 0
#ceph -w查看数据均衡进度, 等待数据均衡完成
[root@ceph1 ~]# kubectl exec -it -n rook-ceph rook-ceph-tools-6f44db7c58-zw47s bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] – [COMMAND] instead.
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd set noup
noup is set
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05878 root default
-3 0.01959 host ceph1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
-5 0.01959 host ceph2
1 hdd 0.00980 osd.1 up 1.00000 1.00000
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-7 0.01959 host ceph3
3 hdd 0.00980 osd.3 up 1.00000 1.00000
4 hdd 0.00980 osd.4 up 1.00000 1.00000
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd down 1
marked down osd.1.
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd out 1
marked out osd.1.
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph -w
cluster:
id: ee795c82-8de1-4dc9-af64-764ffbafbd19
health: HEALTH_WARN
noup flag(s) set
services:
mon: 3 daemons, quorum a,b,c (age 4h)
mgr: a(active, since 4h)
osd: 6 osds: 5 up (since 15s), 5 in (since 3s)
flags noup
data:
pools: 2 pools, 33 pgs
objects: 0 objects, 0 B
usage: 5.1 GiB used, 45 GiB / 50 GiB avail
pgs: 17 active+clean
16 active+undersized
5、均衡数据完成后移除对应的osd
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd purge 1 –yes-i-really-mean-it
purged osd.1
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph auth del osd.1
entity osd.1 does not exist
6、检查ceph状态以及osd状态
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph -s
cluster:
id: ee795c82-8de1-4dc9-af64-764ffbafbd19
health: HEALTH_WARN
noup flag(s) set
services:
mon: 3 daemons, quorum a,b,c (age 4h)
mgr: a(active, since 4h)
osd: 5 osds: 5 up (since 4m), 5 in (since 4m)
flags noup
data:
pools: 2 pools, 33 pgs
objects: 0 objects, 0 B
usage: 5.1 GiB used, 45 GiB / 50 GiB avail
pgs: 33 active+clean
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]#
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.04898 root default
-3 0.01959 host ceph1
0 hdd 0.00980 osd.0 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
-5 0.00980 host ceph2
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-7 0.01959 host ceph3
3 hdd 0.00980 osd.3 up 1.00000 1.00000
4 hdd 0.00980 osd.4 up 1.00000 1.00000
7、移除pod,和判断删除对应的job
[root@ceph1 mapper]# kubectl delete deploy -n rook-ceph rook-ceph-osd-1
deployment.apps “rook-ceph-osd-1” deleted
8、恢复配置
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph osd unset noup
noup is unset
[root@rook-ceph-tools-6f44db7c58-zw47s /]# ceph -s
cluster:
id: ee795c82-8de1-4dc9-af64-764ffbafbd19
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 4h)
mgr: a(active, since 4h)
osd: 5 osds: 5 up (since 6m), 5 in (since 6m)
data:
pools: 2 pools, 33 pgs
objects: 0 objects, 0 B
usage: 5.1 GiB used, 45 GiB / 50 GiB avail
pgs: 33 active+clean
9、格式化磁盘或者下架磁盘
对应机器执⾏,输⼊对应需要下架的盘
#!/bin/bash
yum -y install gdisk
read -p “input your disk [/dev/sda]:” DISK
磁盘去格式化
DISK="/dev/sda”
Zap the disk to a fresh, usable state (zap-all is important, b/c MBR has to be d:clean)
You will have to run this step for all disks.
sgdisk –zap-all $DISK
dd if=/dev/zero of="$DISK" bs=1M count=100 oflag=direct,dsync
These steps only have to be run once on each node
If rook sets up osds using ceph-volume, teardown leaves some devices mapped that lock the disks.
#找到对应的磁盘的ceph信息进行檫除
ls /dev/mapper/ceph–d41fd45b–a5e4–4c45–ab3f–d344c02fa4c9-osd–data–49dda9c2–1907–4225–ad8b–035424fd0484 | xargs -I% – dmsetup remove %
ceph-volume setup can leave ceph- directories in /dev (unnecessary clutter)
rm -rf /dev/rm -rf ceph-4abbbe54-da99-4cac-bdb7-f3ef744ecf78/
lsblk -f
[root@ceph2 mapper]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 xfs 4b8b54bd-9ac2-4bf0-8e64-c4a929a986fa /boot
└─sda2 LVM2_member 9kfG02-udDn-cx3l-2pxQ-fDwK-sUr1-9I079W
├─centos-root xfs 5085bc7a-4955-487e-ae36-b9357fbc9721 /
└─centos-swap swap 618b4fdd-5b18-436d-97c1-4fd786d706f4
sdb LVM2_member dCABKo-MdC0-mfNn-TT36-ZP2F-FEx1-624R8u
└─ceph–1dbde574–6d46–4378–8e58–3963835c0405-osd–data–12d2a2b5–81c6–467e–b17f–cae8c63ef3f4
sdc
sr0 iso9660 CentOS 7 x86_64 2020-11-04-11-36-43-00
10、恢复rook的operator
[root@ceph1 mapper]# kubectl scale deploy -n rook-ceph rook-ceph-operator –replicas=1
deployment.apps/rook-ceph-operator scaled
11、下盘完成
12、上盘,加入硬盘osd
1、修改配置,将需要加入的盘添加上去即可.如果是使用过的磁盘先格式化在添加
[root@ceph1 mapper]# kubectl edit cephcluster -n rook-ceph rook-ceph
和解决办法
Q1. 环境预准备 绝大多数MON创建的失败都是由于防火墙没有关导致的,亦或是SeLinux没关闭导致的。一定一定一定要关闭每个每个每个节点的防火墙(执行一次就好,没安装报错就忽视): CentOS
sed -i ‘s/SELINUX=.*/SELINUX=disabled/’ /etc/selinux/config setenforce 0 systemctl stop firewalld systemctl disable firewalld
iptables -F
service iptables stop
Q2. 清理环境 MON部署不上的第二大问题就是在旧的节点部署MON,或者在这个节点部署MON失败了,然后重新new再mon create-initial,请查看要部署MON的节点上的/var/lib/ceph/mon/目录下是否为空,如果不为空,说明已经在这个目录部署过MON,再次部署会检测子目录下的done文件,由于有了这个文件,就不会再建立新的MON数据库,并且不会覆盖之,导致了部署时的各种异常,这里就不赘述了,直接给出万能清理大法:
对于任何需要新部署MON的节点,请到这个节点下执行如下指令,确保环境已经清理干净:
ps aux|grep ceph |awk ‘{print $2}’|xargs kill -9 ps -ef|grep ceph #确保此时所有ceph进程都已经关闭!!!如果没有关闭,多执行几次。 rm -rf /var/lib/ceph/mon/* rm -rf /var/lib/ceph/bootstrap-mds/* rm -rf /var/lib/ceph/bootstrap-osd/* rm -rf /var/lib/ceph/bootstrap-rgw/* rm -rf /etc/ceph/* rm -rf /var/run/ceph/* 请直接复制粘贴,遇到过好些个自己打错打漏删了目录的。
Q3. 部署前最后的确认 这里介绍的都是个案,不过还是需要提一下:
确保每个节点的hostname都设置正确,并且添加至/etc/hosts文件中,然后同步到所有节点下。克隆出来的虚拟机或者批量建的虚拟机有可能发生此情形。 确保以下目录在各个节点都存在: /var/lib/ceph/ /var/lib/ceph/mon/ /var/lib/ceph/osd/ /etc/ceph/ /var/run/ceph/ 上面的目录,如果Ceph版本大于等于jewel,请确认权限均为ceph:ceph,如果是root:root,请自行chown。 Q4. 安装Ceph 官网指导方法是使用ceph-deploy install nodeX,但是因为是国外的源,速度慢得令人发指,所以我们换到阿里的源,并且使用yum install的方式安装,没差啦其实,这样反而还快点,毕竟多个节点一起装。
很多安装失败的都是因为没有添加epel源请在每个存储节点都执行以下指令,来安装Ceph:
yum clean all rm -rf /etc/yum.repos.d/*.repo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo sed -i ‘/aliyuncs/d’ /etc/yum.repos.d/CentOS-Base.repo sed -i ‘/aliyuncs/d’ /etc/yum.repos.d/epel.repo sed -i ‘s/$releasever/7.2.1511/g’ /etc/yum.repos.d/CentOS-Base.repo echo " [ceph] name=ceph baseurl=http://mirrors.aliyun.com/ceph/rpm-hammer/el7/x86_64/ gpgcheck=0 [ceph-noarch] name=cephnoarch baseurl=http://mirrors.aliyun.com/ceph/rpm-hammer/el7/noarch/ gpgcheck=0 " > /etc/yum.repos.d/ceph.repo yum install ceph ceph-radosgw -y
这里是安装的hammer版本的Ceph,如果需要安装jewel版本的,请执行:
sed -i ‘s/hammer/jewel/’ /etc/yum.repos.d/ceph.repo yum install ceph ceph-radosgw -y
如果安装了jewel版本的Ceph,想要换回hammer版本的Ceph,可以执行下面的指令:
卸载Ceph客户端
rpm -qa |grep ceph -v |awk ‘{print $3}’ |xargs rpm -e –nodeps
更改ceph.repo里面的Ceph版本
sed -i ‘s/jewel/hammer/’ /etc/yum.repos.d/ceph.repo yum install ceph ceph-radosgw -y
Q5. ceph-deploy ① Ceph-deploy 是什么?
Ceph-deploy是Ceph官方给出的用于部署Ceph的一个工具,这个工具几乎全部是Python写的脚本,其代码位于/usr/lib/python2.7/site-packages/ceph_deploy目录下(1.5.36版本)。最主要的功能就是用几个简单的指令部署好一个集群,而不是手动部署操碎了心,敲错一个地方就可能失败。所以对于新人来说,或者说以我的经验,接触Ceph少于一个月的,又或者说,集群规模不上PB的,都没有必要手动部署,Ceph-deploy完全足够了。
② Ceph-deploy怎么装?
这个包在ceph的源里面: yum install ceph-deploy -y
③Ceph-deploy装在哪?
既然Ceph-deploy只是个部署Ceph的脚本工具而已,那么这个工具随便装在哪个节点都可以,并不需要单独为了装这个工具再搞个节点,我一般习惯放在第一个节点,以后好找部署目录。
④Ceph-deploy怎么用?
详细的指令暂时不介绍,下面会有,在安装好后,需要在这个节点新建一个目录,用作部署目录,这里是强烈建议建一个单独的目录的,比如我习惯在集群的第一个节点下建一个/root/cluster目录,为了以后好找。Ceph-deploy的所有的指令都需要在这个目录下执行。包括new,mon,osd等等一切ceph-deploy的指令都需要在这个部署目录下执行!最后一遍,所有的ceph-deploy的指令都要在部署目录下执行!否则就会报下面的错:
[ceph_deploy][ERROR ] ConfigError: Cannot load config: [Errno 2] No such file or directory: ‘ceph.conf’; has ceph-deploy new been run in this directory?
⑤ Ceph-deploy怎么部署集群?
我们暂且把部署目录所在的节点叫做部署节点。Ceph-deploy通过SSH到各个节点,然后再在各个节点执行本机的Ceph指令来创建MON或者OSD等。所以在部署之前,你需要从部署节点ssh-copy-id到各个集群节点,使其可以免秘钥登陆。
⑥Ceph-deploy部署的日志在哪里?
就在部署目录下面的ceph-deploy-ceph.log文件,部署过程中产生的所有的日志都会保存在里面,比如你大半年前敲的创建OSD的指令。在哪个目录下执行ceph-deploy指令,就会在这个目录下生成log,如果你跑到别的目录下执行,就会在执行目录里生成log再记下第四点的错。当然,这个LOG最有用的地方还是里面记录的部署指令,你可以通过cat ceph-deploy-ceph.log |grep “Running command"查看到创建一个集群所需的所有指令,这对你手动建立集群或者创建秘钥等等等等有着很大的帮助!!!
⑦ Ceph-deploy版本
写这段时的最新的版本号为1.5.36,下载链接为ceph-deploy-1.5.36-0.noarch.rpm, 之前的1.5.35里面有点bug在这个版本被修复了,如果使用1.5.25部署遇到了问题,可以更新至这个版本,会绕过一些坑。更新到1.5.36之后,腰也不酸了,退了不疼了,Ceph也能部署上了。
Q6. ceph-deploy new 做了什么 进入部署目录,执行ceph-deploy new node1 node2 node3,会生成两个文件(第三个是ceph-deploy-ceph.log,忽视之):
[root@blog cluster]# ls ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
new后面跟的是你即将部署MON的节点的hostname,推荐三个就够了,需要是奇数个MON节点。不要因为只有两个节点就搞两个MON,两个节点请用一个MON,因为两个MON挂掉一个,集群也就挂了,和一个MON挂掉一个效果是一样的。生成的ceph.conf默认情况下长成这样: [root@blog cluster]# cat ceph.conf [global] fsid = 13b5d863-75aa-479d-84ba-9e5edd881ec9 mon_initial_members = blog mon_host = 1.2.3.4 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx
会调用uuidgen生成一个fsid,用作集群的唯一ID,再将new后面的主机加入到mon_initial_members和mon_host里面,剩下的三行大家都是一样的,默认开启CephX认证。下面有一节会专门介绍这个,需要注意的是,部署的时候,千万不要动这三行 下面会有一节介绍之。还有一个文件ceph.mon.keyring:
[root@blog cluster]# cat ceph.mon.keyring [mon.] key = AQB1yWRYAAAAABAAhMoAcadfCdy9VtAaY79+Sw== caps mon = allow *
除了key的内容不一样,剩下的都会是一样的。因为是开启了CephX认证了,所以MON直接的通讯是需要一个秘钥的,key的内容就是秘钥。是不是对Ceph里面的明文认证感到吃惊,有总比没有强。如果,你再次执行new,会生成新的ceph.conf和新的ceph.mon.keyring,并将之前的这两个文件给覆盖掉,新旧文件唯一不同的就是fsid和key的内容,但是对Ceph来说,这就是两个集群了。这里说一下我个人非常非常非常反感的一个问题,有的朋友喜欢在/etc/ceph/目录下面执行ceph-deploy的命令,这么做和在部署目录下面做一般是没有差别的,因为这两个目录下面都有ceph.conf和ceph.client.admin.keyring,但是我还是强烈推荐创建独立的部署目录,因为/etc/ceph目录是Ceph节点的运行目录,为了体现各自的功能性,也为了安全性,请不要在/etc/ceph目录下部署集群!!!
Q7. 为ceph-deploy添加参数 Ceph-deploy的log还是很有看头的,查看ceph-deploy new blog(blog是我的一台主机)的log:
[root@blog cluster]# ceph-deploy new blog [ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf [ceph_deploy.cli][INFO ] Invoked (1.5.36): /usr/bin/ceph-deploy new blog [ceph_deploy.cli][INFO ] ceph-deploy options: [ceph_deploy.cli][INFO ] username : None [ceph_deploy.cli][INFO ] func : <function new at 0x288e2a8> [ceph_deploy.cli][INFO ] verbose : False [ceph_deploy.cli][INFO ] overwrite_conf : False [ceph_deploy.cli][INFO ] quiet : False [ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x28eccf8> [ceph_deploy.cli][INFO ] cluster : ceph [ceph_deploy.cli][INFO ] ssh_copykey : True [ceph_deploy.cli][INFO ] mon : [‘blog’] [ceph_deploy.cli][INFO ] public_network : None [ceph_deploy.cli][INFO ] ceph_conf : None [ceph_deploy.cli][INFO ] cluster_network : None [ceph_deploy.cli][INFO ] default_release : False [ceph_deploy.cli][INFO ] fsid : None [ceph_deploy.new][DEBUG ] Creating new cluster named ceph
可以看到有很多的参数被列出来了,比如:mon : [‘blog’],也有很多参数是False或者None, 这些参数能否被设置呢? 因为这里我们可以看到有fsid : None 这个参数,难道集群的fsid可以被指定吗?抱着这些疑惑,我就去看完了ceph-deploy的所有代码,答案是:可以设置。所有上面的参数都可以使用参数的形式进行设置,只需要在前面加上两个–,比如对于fsid可以执行:
ceph-deploy new blog –fsid xx-xx-xx-xxxx
如果想要查看每个执行可指定的参数,可以-h: [root@blog cluster]# ceph-deploy new -h usage: ceph-deploy new [-h] [–no-ssh-copykey] [–fsid FSID] [–cluster-network CLUSTER_NETWORK] [–public-network PUBLIC_NETWORK] MON [MON …] … optional arguments: -h, –help show this help message and exit –no-ssh-copykey do not attempt to copy SSH keys –fsid FSID provide an alternate FSID for ceph.conf generation –cluster-network CLUSTER_NETWORK specify the (internal) cluster network –public-network PUBLIC_NETWORK specify the public network for a cluster
这里就可以看到可以指定–cluster-network,–public-network,等等,如果optional arguments里面没有介绍这个参数,可以直接使用–xxarg的方式指定,比如–overwrite-conf,–verbose等等,能不能设置这些参数,自己动手试一下就知道了。需要注意的是,参数的位置根据指令而异,比如–overwrite-conf参数是跟在ceph-deploy后面的,而–public-network是跟在new后面的:
ceph-deploy –overwrite-conf –verbose new blog –fsid a-a-a-a [root@blog cluster]# cat ceph.conf |grep fsid fsid = a-a-a-a
Q8. Public VS Cluster 如果非要在刚刚生成的ceph.conf里面添加什么的话,那么可能就要加public_network或者cluster_network了。那么这两个配置项有什么用呢?这里简单得介绍下Ceph的Public(外网或者叫公网或者前端网)和Cluster(内网或者叫集群网或者叫后端网)这两个网络,在Ceph中,存在以下三种主要的网络通讯关系:
client-> mon =>public : 也就是客户端获取集群状态,或者叫客户端与MON通讯走的网络,是走的外网。 client-> osd => public : 也就是客户端向OSD直接写入数据走的也是外网。 osd<-> osd => cluster :也就是OSD之间的数据克隆,恢复走的是内网,客户端写第一份数据时通过外网写,对于三副本剩下的两个副本OSD之间通过内网完成数据复制。当OSD挂掉之后产生的recover,走的也是内网。 通常,我们会将外网配置为千兆网,而内网配置成万兆网,这是有一定原因的:
客户端可能由成百上千的计算节点组成,外网配成万兆成本太高。 存储节点一般只有几个到几十个节点,配置了万兆内网可以大大加快故障恢复速度,而且剩余的两副本写速度会大大加快,万兆网的性价比极高。举个例子,集群坏掉一个OSD千兆需要一小时,那么万兆网只需要五六分钟,一定程度上增加了集群的安全性。 借用官网的这张图来说明集群的网络走势:再假设你的节点有两个网段172.23.0.1和3.3.4.1,还记得我们上一节ceph-deploy new的时候是可以指定public_network和cluster_network的吗!如果不指定这两个参数,那么ceph-deploy怎么知道用哪个IP作为这个节点的mon_host的IP呢,其实他是随便选的,如果它选了172网段但是你想使用3.3网段作为这个节点的mon_host的IP,那么只需要指定–public-network 172.23.0.0/24 就可以了,其中的/24就相当于一个掩码,表示前面的IP的前24位,也就是172.23.0.XXX,只要你的主机上有一个处于这个范围内的IP,那么就会选择这个IP作为公网IP。类似的,/16表示范围:172.23.XXX.XXX。 如果想指定内网IP,那么只要指定–cluster-network 3.3.4.1/24就可以了。
一般情况下,会在new生成的ceph.conf文件里加入public_network配置项以指定公网IP。当然你的MON主机上需要有至少一个IP在公网范围内。除了在生成的ceph.conf文件中加入公网IP的方式,我们还可以使用参数的方式来指定公网IP:
[root@ceph-1 cluster]# ceph-deploy new ceph-1 –public-network 172.23.0.0/24 [ceph_deploy.cli][INFO ] Invoked (1.5.36): /usr/bin/ceph-deploy new ceph-1 –public-network 172.23.0.0/24 [ceph_deploy.cli][INFO ] ceph-deploy options: … [ceph_deploy.cli][INFO ] public_network : 172.23.0.0/24 … [ceph-1][DEBUG ] IP addresses found: [u’172.23.0.101’, u’10.0.2.15’] [ceph_deploy.new][DEBUG ] Resolving host ceph-1 [ceph_deploy.new][DEBUG ] Monitor ceph-1 at 172.23.0.101 [ceph_deploy.new][DEBUG ] Monitor initial members are [‘ceph-1’] [ceph_deploy.new][DEBUG ] Monitor addrs are [u’172.23.0.101’] [ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring… [ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf… [root@ceph-1 cluster]# cat ceph.conf [global] fsid = d2a2bccc-b215-4f3e-922b-cf6019068e76 public_network = 172.23.0.0/24 mon_initial_members = ceph-1 mon_host = 172.23.0.101 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx 在这里插入图片描述
查看部署log可以发现参数配置已经生效,而这个节点有两个IP,public_nwtwork这个参数限定了公网IP的搜索范围,生成的ceph.conf文件内也包含了public_network这个参数。
Q9. 参数是下划线还是空格分隔 这里只是简单的提一下这个小困惑,对于以下的两个参数书写方式,哪种会有问题呢: public_network = 172.23.0.1/24 public network = 172.23.0.1/24 osd_journal_size = 128 osd journal size = 128
这两种参数的书写方式其实都是正确的,说到底是因为底层调用的是Python的argparse模块。这两种方式都是等效的,所以不需要担心。
Q10. ceph-deploy mon create-initial如何一次性通过 这一步坑哭了多少迫切加入Ceph世界的新人,看到的最多的就是5s,10s,10s, 15s,20s。。。然后报了错。再执行,再报错。所以这里给出以下的预检清单,如果被报错失败所烦恼,请认真执行各个子项,尤其是失败后要执行清理环境:
请确保所有节点都安装了Ceph。 请确保所有节点的防火墙等都关闭了。参考环境预准备一节 请前往各个MON节点清理干净,不论你是否相信这个节点是干净的。参考清理环境一节。 请确保各个MON节点下存在以下目录,并且对于Jewel版本及之后的请确保目录权限为ceph:ceph。参考部署前最后的确认一节。 请在ceph-deploy new生成的ceph.conf内添加public_network配置项,参考Public VS Cluster一节。 这些总结来之不易,我帮过上百个人解决过部署问题和集群故障。我相信在认真确认过之后是肯定可以通过的(反正前三点如果有问题一般是不会建好MON的,为什么不认真确认下呢),我遇到过绝大多数都是因为防火墙没关,或者手动删除了一些目录,或者没有修改权限导致的问题。
相对来说,新环境只要关了防火墙就可以一次性通过,旧环境或者失败的环境只要清理环境就可以通过了。
Q11. mon create-initial 做了什么
简单介绍下流程:
ceph-deploy读取配置文件中的mon_initial_members的各个主机,然后依次SSH前往各个主机: 将部署目录下的ceph.conf推送到新节点的/etc/ceph/目录下。 创建/var/lib/ceph/mon/c l u s t e r − cluster-cluster−hostname/目录。 检查MON目录下是否有done文件,如果有则直接跳到第6步。 将ceph.mon.keyring拷贝到新节点,并利用该秘钥在MON目录下建立MON数据库。 在MON目录下建立done文件,防止重新建立MON。 启动MON进程。 查看/var/run/ceph/c l u s t e r − m o n . cluster-mon.cluster−mon.hostname.asokSOCKET文件,这个是由MON进程启动后生成的,输出MON状态。 在所有的MON都建立好后,再次前往各个主机,查看所有主机是否运行并且到达法定人群(quorum)。如果有没到到的,直接结束报错。如果都到达了,执行下一步。 调用auth get-or-create方法创建(如果不存在)或者拉取(已经存在)MON节点上的以下几个keyring到部署目录中: ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.bootstrap-rgw.keyring ceph.client.admin.keyring 指令结束。 Q12. mon create-initial 为什么会失败 我不喜欢讲怎么做,我愿意花很大的篇幅介绍为什么会造成各种各样的问题,如果知道了原因,你自然知道该怎么做,所以才会理解Ceph,而不是机械的去敲指令。
综合上面的所有小节,我来总结下这一步失败的基本上所有可能的原因:
所谓MON的quorum,相当于多个MON形成的一个群体,它们之间需要通过网络发送数据包来通讯达成某种协议,如果打开了防火墙,会阻断数据交流。所以不能构成群体,一直等待(5s->10s->10s->15s->20s)其他MON的数据包,既然被阻断了这样的等待是没有意义的,等了30s还没有正常,就可以直接ctrl+z去检查了。 我在配置文件里面添加了pubilc_network,但是有个主机的所有IP都不在公网IP段内,那么这个MON是建不好的,因为没有IP用作MON使用,public_network相当于一个过滤器。 搭好了一台虚拟机后,直接克隆了两台,没有修改主机名,导致socket文件路径名识别错误,报了异常,不过这很少发生。 如果在旧的MON节点上再次部署新的MON,再又没有清理环境,之前的MON数据库会保留着done文件,MON数据库里面还是记录着之前fsid,keyring等等,和新集群是两套完全不同的,所以这个节点的MON自然到达不了MON群体。 即使你单单删除了/var/lib/ceph/mon下的东西,而没有清理那些keyring,也有可能会因为收集了旧集群的秘钥而发生稀奇古怪的问题。 对于Jewel,你一不小心删除了/var/lib/ceph/mon目录,或者其他的OSD目录或者/var/run/ceph目录,然后又重建了目录,依然部署不上,是因为Jewel的所有Ceph指定都是运行在ceph:ceph用户下的,自然不能在root权限目录下建立任何文件,修改权限即可。 Ceph生成MON数据库是依照主机的hostname来命名至目录/var/lib/ceph/mon/c l u s t e r − {cluster}-cluster−{hostname}的,而检测SOCKET文件则是用ceph.conf里面的mon_initial_members里面的名字来检测的 ,如果mon_initial_members里面的名字和真是的主机名不一致,就会报错。 一旦你运行了ceph-deploy mon create-initial指令,并且失败了,有极大的可能性已经在某些节点建立好了MON的数据库,再次执行可能会因为旧的环境导致再次失败,所以如果失败了,执行一下第二节中的清理环境即可。清理完毕后,再执行ceph-deploy mon create-initial。
拉取镜像 拉取rook-ceph相关镜像,需要愚昧上网。
创建crd&common 获取rook部署yaml文件,此处可以自由选择版本,当然有人建议根据K8s的版本选择一个合适的rook版本。
#v1.12稳定版 git clone –single-branch –branch v1.12.11 https://github.com/rook/rook.git git clone –single-branch –branch v1.13.8 https://github.com/rook/rook.git 部署资源文件
cd rookv1.13.8 kubectl create -f crds.yaml -f common.yaml #删除 kubectl delete -f crds.yaml -f common.yaml 部署operator 一般来说不用修改。operator(操作器)是rook部署的核心,rook的操作都需要operator(操作器)进行。
kubectl create -f operator.yaml #删除部署 kubectl delete -f operator.yaml #查看状态,比如保证operator处于running状态 kubectl get pod -n rook-ceph NAME READY STATUS RESTARTS AGE rook-ceph-operator-9f688fcc5-cg689 1/1 Running 0 3s 部署cluster 使用磁盘序列号进行绑定,避免重启后nvme硬盘识别号发生变化。一般来说不存在这个问题,但是某些超微主板在添加同型号SSD后,硬盘位置为发生变化, 所以可以执行磁盘序列号绑定。
udevadm info –query=all –name=/dev/nvme1n1 P: /devices/pci0000:00/0000:00:03.3/0000:01:00.0/nvme/nvme1/nvme1n1 N: nvme1n1 L: 0 S: disk/by-id/nvme-eui.5cd2e4259141745f S: disk/by-id/nvme-INTEL_SSDPEKKF010T8L_PHHH838101SW1P0E_1 S: disk/by-id/nvme-INTEL_SSDPEKKF010T8L_PHHH838101SW1P0E 部署
kubectl create -f cluster.yaml #删除 kubectl delete -f cluster.yaml cluster.yaml存储了使用的硬盘信息。下面是一个复杂的设置:配置了两种型号的硬盘SSD和HDD,其中为HDD配置SSD缓存。深入理解,可以参考rook给出的deviceClass的说明。
deviceClass:用于此选择的存储设备的CRUSH 设备类。 (默认情况下,如果尚未设置设备的类别,OSD 将根据 Linux 内核公开的硬件属性自动将设备的类别设置为hdd、ssd或。)然后可以使用这些存储类别来选择支持的设备通过将它们指定为池规范字段的nvme值来创建存储池。deviceClass.。来源:https://rook.io/docs/rook/latest-release/CRDs/Cluster/ceph-cluster-crd/#storage-class-device-sets
storage: # cluster level storage configuration and selection useAllNodes: false useAllDevices: false config: {} nodes: - name: “k8s-w32-ip31-7513” devices: - name: “/dev/disk/by-id/nvme-WUS4BB076D7P3E3_A05E1AB6” config: osdsPerDevice: “4” - name: “/dev/disk/by-id/nvme-WUS4BB076D7P3E3_A0614749” config: osdsPerDevice: “4” - name: “sda” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdb” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdc” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdd” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sde” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdf” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdg” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdh” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” - name: “sdi” config: metadataDevice: “/dev/disk/by-id/nvme-Micron_7450_MTFDKBG960TFR_22263B92A0F1” 安装ceph客户端工具 #创建toolbox kubectl create -f toolbox.yaml -n rook-ceph kubectl delete -f toolbox.yaml -n rook-ceph
查看pod
kubectl get pod -n rook-ceph -l app=rook-ceph-tools #直接执行命令 kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph status kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph osd lspools #进入pod kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – bash #查看集群状态 ceph status 暴露Dashboard Dashboard可以让我们查看Ceph集群的状态,包括整体的运行状况、mon仲裁状态、mgr、osd 和其他Ceph守护程序的状态、查看池和PG状态、显示守护程序的日志等。关于Dashboard的更多配置,请参考:https://rook.io/docs/rook/v1.11/Storage-Configuration/Monitoring/ceph-dashboard/
查看dashboard的svc,Rook将启用端口 8443 以进行 https 访问:
kubectl get svc -n rook-ceph NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE rook-ceph-mgr ClusterIP 10.140.249.105 9283/TCP 12m rook-ceph-mgr-dashboard ClusterIP 10.140.217.133 8443/TCP 12m rook-ceph-mon-a ClusterIP 10.140.21.78 6789/TCP,3300/TCP 13m rook-ceph-mon-b ClusterIP 10.140.36.54 6789/TCP,3300/TCP 13m rook-ceph-mon-c ClusterIP 10.140.9.120 6789/TCP,3300/TCP 13m
rook-ceph-mgr:是 Ceph 的管理进程(Manager),负责集群的监控、状态报告、数据分析、调度等功能,它默认监听 9283 端口,并提供了 Prometheus 格式的监控指标,可以被 Prometheus 拉取并用于集群监控。
rook-ceph-mgr-dashboard:是 Rook 提供的一个 Web 界面,用于方便地查看 Ceph 集群的监控信息、状态、性能指标等。
rook-ceph-mon:是 Ceph Monitor 进程的 Kubernetes 服务。Ceph Monitor 是 Ceph 集群的核心组件之一,负责维护 Ceph 集群的状态、拓扑结构、数据分布等信息,是 Ceph 集群的管理节点。
查看默认账号admin的密码
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath=”{[‘data’][‘password’]}" | base64 –decode && echo 使用 NodePort 类型的Service暴露dashboard dashboard-external-https.yaml
kubectl create -f dashboard-external-https.yaml #删除部署 kubectl delete -f dashboard-external-https.yaml
清除rook-ceph 删除 Ceph 集群,按照建立顺序反向删除,crd.yaml不用删除
#查看已经建立的pv、pvc kubectl get pv,pvc kubectl delete pvc pvc名称 kubectl delete pv pv名称 #删除storage kubectl get storageclass -A kubectl delete storageclass rook-ceph-es-sc #删除文件系统 ceph fs fail nvmefs ceph fs rm nvmefs –yes-i-really-mean-it #删除存储池 kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph osd lspools kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph osd pool delete replicapool replicapool –yes-i-really-really-mean-it kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph osd pool delete ec-pool ec-pool –yes-i-really-really-mean-it kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – ceph osd pool delete .mgr .mgr –yes-i-really-really-mean-it #删除集群。如果不需要更改rook-ceph的命名空间,可以到此为止。 kubectl delete -f cluster.yaml kubectl delete -f operator.yaml kubectl delete -f common.yaml 验证清理,验证所有资源是否已经被清理干净。
kubectl get all -n rook-ceph kubectl -n rook-ceph get all,pvc,secret,configmap,cephclusters.ceph.rook.io,cephblockpools.ceph.rook.io,cephfilesystems.ceph.rook 卡主的解决方案 查看和删除Finalizers: Kubernetes资源(如CephCluster)可能因为finalizer阻塞而不能被删除。您可以检查并手动移除这些finalizer以解除删除阻塞:
在编辑界面中,找到metadata部分下的finalizers,删除所有列出的finalizer条目,然后保存并退出编辑器。这应该会移除删除阻塞。
kubectl edit cephcluster rook-ceph -n rook-ceph 卡主的解决方案2 故障排除,原文链接:https://blog.csdn.net/zh_admini/article/details/124090548
如果清理指令没有按照上面的顺序执行,或者你很难清理集群,这里有一些事情可以尝试。
清理集群最常见的问题是rook-ceph命名空间或集群 CRD 无限期地保持在terminating状态中。命名空间在其所有资源都被删除之前无法被删除,因此请查看哪些资源正在等待终止。
kubectl -n rook-ceph get pod
kubectl -n rook-ceph get cephcluster
for CRD in $(kubectl get crd -n rook-ceph | awk ‘/ceph.rook.io/ {print $1}’); do
kubectl get -n rook-ceph “$CRD” -o name |
xargs -I {} kubectl patch -n rook-ceph {} –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
done
kubectl api-resources –verbs=list –namespaced -o name
| xargs -n 1 kubectl get –show-kind –ignore-not-found -n rook-ceph
kubectl -n rook-ceph patch configmap rook-ceph-mon-endpoints –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
kubectl -n rook-ceph patch secrets rook-ceph-mon –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
清理节点 重新部署之前,必需清理节点
对于每个参与过 Ceph 集群的节点,你可能需要手动清理相关的数据目录和设备。这通常包括删除 OSD 数据、mon 数据和日志文件。
#手动登录到每个节点并清理 Ceph 使用的磁盘和目录 sudo rm -rf /var/lib/rook sudo rm -rf /var/lib/rook-hdd
#将磁盘置为初始状态 lsblk sudo wipefs -a /dev/sda #元数据盘 sudo wipefs -a /dev/nvme3n1 sudo cfdisk #如果cfdisk 删除分区后,lsblk还存在lvm分区,此时需要重启电脑。 三、创建cephfs文件系统 CephFS,或者称为 Ceph 文件系统,是一种分布式文件系统,允许多个客户端同时连接到一个 Ceph 存储集群来访问文件。与传统的文件系统(如 NTFS、EXT4 等)不同,CephFS 主要设计用于提供高性能、可扩展和高可用性的存储解决方案。然而,关于您提到的“文件格式”,这里有几个相关的概念需要澄清:
文件系统类型:CephFS 本身就是一种文件系统类型,就像 EXT4、XFS 或 BTRFS 等 Linux 文件系统。它处理文件的存储方式、元数据管理以及数据冗余和恢复等任务。
存储数据格式:CephFS 存储数据在后端的 Ceph 集群中,通常是以 RADOS(Reliable Autonomic Distributed Object Store)块为基础。这些数据块由 Ceph 内部以对象的形式管理,而不是传统的文件系统所使用的连续磁盘块。CephFS 通过其元数据服务器来管理文件系统的层次结构和文件元数据,而实际的文件数据被存储在这些对象中。
文件兼容性:对于终端用户来说,CephFS 提供了一个标准的 POSIX 文件系统接口,这意味着用户和应用程序可以像使用任何本地文件系统一样使用 CephFS,而无需担心后端存储的具体实现细节。因此,任何标准的文件类型(如文本文件、图像、视频等)都可以存储在 CephFS 中,而这些文件的格式是由创建它们的应用程序决定的,与 CephFS 无关。
访问和交互:CephFS 可以通过多种方式挂载和访问,包括内核模块、FUSE 客户端以及通过网络文件系统协议(如 NFS)。这些方法都提供对 CephFS 的透明访问,让它表现得就像一个普通的文件系统。
总的来说,CephFS 自身并没有所谓的“文件格式”,它提供的是文件系统服务,允许存储和访问各种格式的文件。用户层面看到的文件格式由具体的应用程序决定,CephFS 仅负责安全和效率地存储这些文件。如果您有关于如何在 CephFS 上操作特定类型文件的问题,或者需要进一步的帮助,随时欢迎提问!
创建用的yaml文件,rook给出的示例有问题,可以参考这个,此处不在重复yaml文件以及建立过程。
Rook-CephのCephFSを使ってWordpress環境の構築をする - Qiita
四、创建NFS导出 如果K8s工作集群和rook存储集群是分开的,那么需要创建NFS导出为K8s的工作集群使用。
但是问题是NFS挂载性能不行,因此高性能场景不建议使用NFS挂载。
五、CEPH调优 调整PG和PGP 在Ceph集群中,**放置组(Placement Groups,简称PG)和放置组的副本数量(PGP,Placement Group Placement)**是确保数据存储和检索的效率和一致性的关键概念。了解这两个概念有助于深入理解Ceph的工作原理和如何优化其性能。
PG(放置组) 放置组是Ceph用来组织和管理数据的一个基本单位。当数据存储到Ceph集群时,它们不是直接存储到物理硬盘上,而是先被划分为更小的单位,然后存储到这些放置组中。每个放置组对应一组OSD(对象存储设备),这些OSD负责存储该放置组内的数据。放置组的主要目的包括:
负载均衡:通过均匀分配数据到不同的放置组和OSD,Ceph能够确保没有单一的OSD过载,从而优化整个集群的性能和扩展性。
数据复制和恢复:在放置组内,Ceph通过复制同一数据到多个OSD来实现数据的高可用和容错。如果一个OSD发生故障,Ceph可以从其他OSD中的副本恢复数据。
PGP(放置组的副本数量) PGP是指放置组的物理位置或其副本的放置策略。在Ceph的早期版本中,pg_num和pgp_num可以被独立设置,以允许细致控制放置组的数据分布,而不必重新映射整个放置组。这可以用来平滑地调整放置组的分布,而不会引起大规模的数据移动。但在最新的Ceph版本中,通常推荐保持pg_num和pgp_num一致,以简化管理并优化数据分布的一致性。
数据分布与CRUSH算法 Ceph使用CRUSH(Controlled Replication Under Scalable Hashing)算法来计算数据应该存储在哪个放置组以及这些放置组应该分布到哪些OSD上。CRUSH算法使得Ceph能够高效地扩展到数千个硬件节点,同时提供一致的数据分布和快速的数据检索能力。
调整PG的数量是一个复杂的操作,通常在集群规模变化或性能调优时进行。查看当前的PG数量和建议值,可以使用:
#获取pg和pgp数量 ceph osd pool get pg_num ceph osd pool get pgp_num ceph osd pool get nvme-replicapool pg_num ceph osd pool get nvme-replicapool pgp_num
ceph osd pool get mynfs-metadata pg_num ceph osd pool get nvme-replicapool pgp_num ceph osd pool get mynfs-replicated pg_num 如果您有 50 多个 OSD,我们建议每个 OSD 大约 50-100 个 PG,以平衡资源使用量、数据持久性和分布。如果您没有 50 个 OSD,理想的做法是在 PG Count 中选择 Small Clusters。对于单个对象池,您可以使用以下公式来获取基准:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count
其中,池大小 是复制池的副本数量,或者是纠删代码池的 K+M 和(由 ceph osd erasure-code-profile get返回)。
结算的结果往上取靠近2的N次方的值。比如总共OSD数量是160,复制份数3,pool数量也是3,那么按上述公式计算出的结果是1777.7。取跟它接近的2的N次方是2048,那么每个pool分配的PG数量就是2048。
调整pg数,调整pg数的大小,推荐的增长幅度为2的幂
设置命令如下:
ceph osd pool set pg_num <new_pg_num> ceph osd pool set nvme-replicapool pg_num 256 ceph osd pool set nvmefs-replicated pg_num 256 ceph osd pool set nvmefs-metadata pg_num 256 ceph osd pool set hddreplicapool pg_num 1024
ceph osd pool set mynfs-metadata pg_num 1024 ceph osd pool set mynfs-replicated pg_num 1024 可以使用ceph -w来查看集群pg分布状态,并等待集群恢复正常(会引起部分pg的分布变化,但不会引起pg内的对象的变动)。
调整pgp,在pg增长之后,通过下面的命令,设置pgp和pg数保持一致,并触发数据平衡。
ceph osd pool set pgp_num <new_pgpnum> ceph osd pool set nvme-replicapool pgp_num 256 ceph osd pool set nvmefs-replicated pgp_num 256 ceph osd pool set nvmefs-metadata pgp_num 256 ceph osd pool set hddreplicapool pgp_num 1024
ceph osd pool set mynfs-metadata pgp_num 1024 ceph osd pool set mynfs-replicated pgp_num 1024 参考:
3.3. PG Count Red Hat Ceph Storage 4 | Red Hat Customer Portal
CEPH系列之性能调优:怎样设置PG数量? - 大天使之剑 - twt企业IT交流平台
cloud.tencent.com
六、CEPH运维手册 https://lihaijing.gitbooks.io/ceph-handbook/content/Troubleshooting/troubleshooting_pg.html
https://access.redhat.com/documentation/zh-cn/red_hat_ceph_storage/4/html/administration_guide/placement-group-states_admin ————————————————
删除rook-ceph 删除依赖的资源 kubectl delete -f ../wordpress.yaml kubectl delete -f ../mysql.yaml kubectl delete -n rook-ceph cephblockpool replicapool kubectl delete storageclass rook-ceph-block kubectl delete -f csi/cephfs/kube-registry.yaml kubectl delete storageclass csi-cephfs
备注:如果没有使用到以上资源对象或者外部没有关联storageclass,可以跳过执行,在删除 Rook operator和agent之前删除以上资源很重要,否则可能无法正确清理资源。
删除 CephCluster CRD kubectl -n rook-ceph patch cephcluster rook-ceph –type merge -p ‘{“spec”:{“cleanupPolicy”:{“confirmation”:“yes-really-destroy-data”}}}’ kubectl -n rook-ceph delete cephcluster rook-ceph kubectl -n rook-ceph get cephcluster 1 2 3 备注:如果在 Rook Cluster 上创建的资源没有被完全删除,清理作业可能不会启动
删除 Operator 及相关资源 kubectl delete -f operator.yaml kubectl delete -f common.yaml kubectl delete -f crds.yaml 1 2 3 备注:如果cleanupPolicy已应用 并且清理作业已在所有节点上完成,则集群拆除已成功。如果您跳过添加cleanupPolicy然后按照下面提到的手动步骤来拆除集群
删除主机上的数据 rm -rf /datarook/rook //dataDirHostPath指定的路径 ls /dev/mapper/ceph-* | xargs -I% – dmsetup remove % rm -rf /dev/ceph-* rm -rf /dev/mapper/ceph–* DISK="/dev/sdc" dd if=/dev/zero of="$DISK" bs=512k count=1 wipefs -af $DISK 1 2 3 4 5 6 7 故障排除 如果清理指令没有按照上面的顺序执行,或者你很难清理集群,这里有一些事情可以尝试。 清理集群最常见的问题是rook-ceph命名空间或集群 CRD 无限期地保持在terminating状态中。命名空间在其所有资源都被删除之前无法被删除,因此请查看哪些资源正在等待终止。
kubectl -n rook-ceph get pod
kubectl -n rook-ceph get cephcluster
for CRD in $(kubectl get crd -n rook-ceph | awk ‘/ceph.rook.io/ {print $1}’); do
kubectl get -n rook-ceph “$CRD” -o name |
xargs -I {} kubectl patch -n rook-ceph {} –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
done
kubectl api-resources –verbs=list –namespaced -o name
| xargs -n 1 kubectl get –show-kind –ignore-not-found -n rook-ceph
kubectl -n rook-ceph patch configmap rook-ceph-mon-endpoints –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
kubectl -n rook-ceph patch secrets rook-ceph-mon –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’
备注:删除之后可以通过etcdctl 查看资源是否彻底删除
ETCDCTL_API=3 etcdctl –cacert=/opt/kubernetes/ssl/ca.pem –cert=/opt/kubernetes/ssl/server.pem –key=/opt/kubernetes/ssl/server-key.pem –endpoints=https://192.168.1.92:2379,https://192.168.1.93:2379,https://192.168.1.94:2379 get /registry –prefix –keys-only=true | grep ‘/registry’ |grep rook 1 详情请参考:ROOK官网 ————————————————
重新再集群上安装rook-ceph 简直是灾难,复杂。
|
|
. CephCluster “rook-ceph/rook-ceph” will not be deleted until all dependents are removed: CephFilesystem: [myfs]
kubectl label nodes k-n1 role=ceph kubectl label nodes k-n2 role=ceph kubectl label nodes k-n3 role=ceph
设置 rook-ceph 部署和存储Osd 节点标签
kubectl label nodes k-n1 node.kubernetes.io/storage=rook
kubectl label nodes k-n2 node.kubernetes.io/storage=rook
kubectl label nodes k-n3 node.kubernetes.io/storage=rook
安装 ceph csi plugin 节点
kubectl label nodes k-n1 node.rook.io/rook-csi=true
kubectl label nodes k-n2 node.rook.io/rook-csi=true
kubectl label nodes k-n3 node.rook.io/rook-csi=true
在operator文件中修改节点选择
CSI_PROVISIONER_NODE_AFFINITY: “node.kubernetes.io/storage=rook”
CSI_PLUGIN_NODE_AFFINITY: “node.kubernetes.io/storage=rook”
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
修改集群配置文件 cluster.yaml,增加节点亲和配置 placement: all: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node.kubernetes.io/storage operator: In values: - rook 查询节点:
[root@k-m1 examples]# kubectl get nodes -l node.kubernetes.io/storage=rook NAME STATUS ROLES AGE VERSION k-n1 Ready 2y86d v1.24.2 k-n2 Ready 2y86d v1.24.2 k-n3 Ready 2y86d v1.24.2
curl -k -H “Content-Type: application/json” -X PUT –data-binary @tmp.json http://127.0.0.1:8001/api/v1/namespaces/rook-ceph/finalize
出错::: failed to update cluster condition to {Type:Progressing Status:True Reason:ClusterProgressing Message:Configuring the Ceph cluster LastHeartbeatTime:2025-01-07 08:33:00.965912578 +0000 UTC m=+2154.997832975 LastTransitionTime:2025-01-07 08:33:00.96591247 +0000 UTC m=+2154.997832890}. failed to update object “rook-ceph/rook-ceph” status: Operation cannot be fulfilled on cephclusters.ceph.rook.io “rook-ceph”: the object has been modified; please apply your changes to the latest version and try again 2025-01-07 08:33:00.987875 I | op-mon: start running mons 2025-01-07 08:33:01.064637 I | ceph-spec: creating mon secrets for a new cluster
获得的报错是什么 e0 get_health_metrics reporting 32 slow ops, oldest is log(1 entries from seq 1 at 2025-01-07T08:46:53.292453+0000)