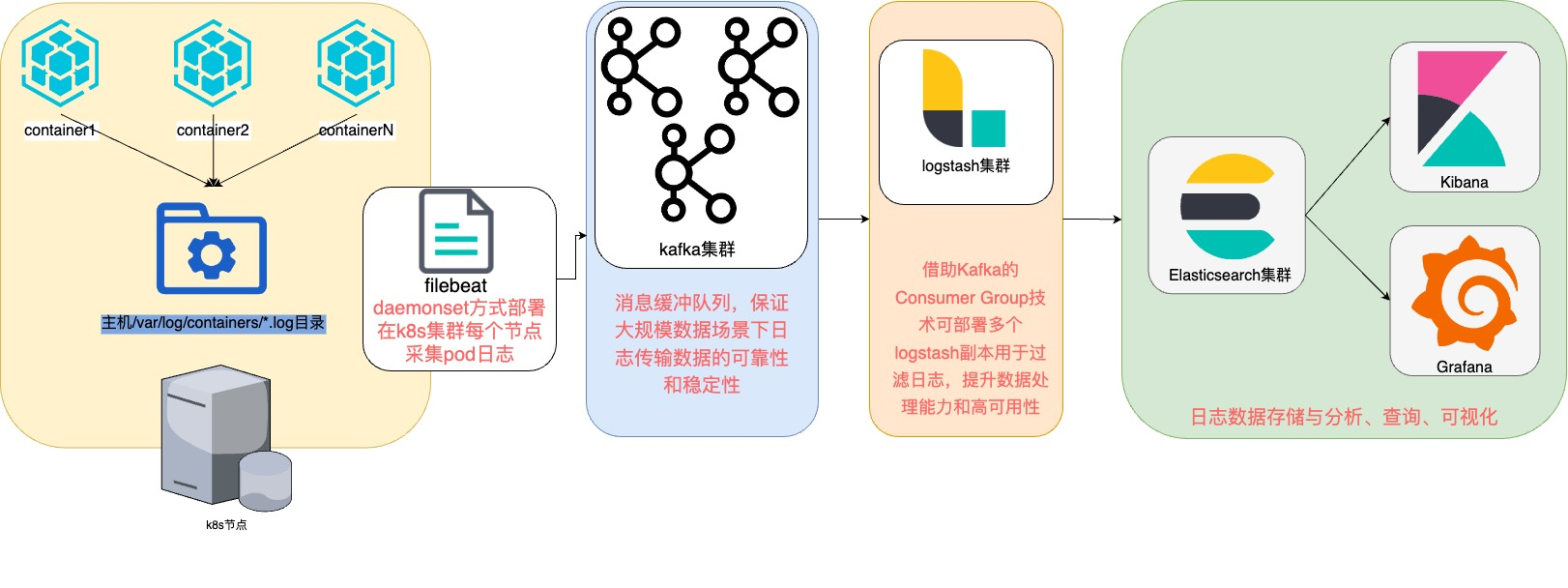
ELK 方案
方案介绍
面对大规模集群海量日志采集需求时,filebeat 相较于 fluent bit 拥有更高的性能,因此可以通过 daemonset 方式在每个 k8s 节点运行一个 filebeat 日志采集容器,用于采集业务容器产生的日志并暂存到 kafka 消息队列中。借助 Kafka 的 Consumer Group 技术部署多个 logstash 副本,由 logstash 集群逐个消费并写入 ES,防止瞬间高峰导致直接写入 ES 失败,提升数据处理能力和高可用性。
采集方案
kafka 部署
生产环境推荐的 kafka 部署方式为 operator 方式部署,Strimzi 是目前最主流的 operator 方案。集群数据量较小的话,可以采用 NFS 共享存储,数据量较大的话可使用 local pv 存储。
部署 operator
operator 部署方式 helm 或者 yaml 文件部署,此处以 helm 方式部署为例:
1
2
3
4
5
|
helm repo add strimzi https://strimzi.io/charts/
helm install strimzi -n kafka strimzi/strimzi-kafka-operator
kubectl get pod -n kafka
|
查看部署文件
Strimzi 官方仓库为我们提供了各种场景的示例文件,资源清单下载地址: https://github.com/strimzi/strimzi-kafka-operator/releases
1
2
3
4
5
6
7
8
9
10
11
12
|
wget https://github.com/stimzi/strimzi-kafka-operator/releases/download/0.43.0/strimzi-0.43.0.tar.gz
tar -zxvf strimzi-0.43.0.tar.gz
cd strimzi-0.43.0/examples/kafka
ls
# 输出以下
drwxr-xr-x 2 - xfhuang 23 Aug 17:47 -N kraft/
.rw-r--r-- 1 713 xfhuang 23 Aug 17:47 -N kafka-ephemeral-single.yaml
.rw-r--r-- 1 713 xfhuang 23 Aug 17:47 -N kafka-ephemeral.yaml
.rw-r--r-- 1 957 xfhuang 23 Aug 17:47 -N kafka-jbod.yaml
.rw-r--r-- 1 865 xfhuang 23 Aug 17:47 -N kafka-persistent-single.yaml
.rw-r--r-- 1 865 xfhuang 23 Aug 17:47 -N kafka-persistent.yaml
.rw-r--r-- 1 1.4k xfhuang 23 Aug 17:47 -N kafka-with-node-pools.yaml
|
- kafka-persistent.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的持久集群。(推荐)
- kafka-jbod.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点(每个节点使用多个持久卷)的持久集群。
- kafka-persistent-single.yaml:部署具有单个 ZooKeeper 节点和单个 Kafka 节点的持久集群。
- kafka-ephemeral.yaml:部署具有三个 ZooKeeper 和三个 Kafka 节点的临时群集。
- kafka-ephemeral-single.yaml:部署具有三个 ZooKeeper 节点和一个 Kafka 节点的临时群集。
创建 pvc 资源
此处以 nfs 存储为例,提前创建 pvc 资源,分别用于 3 个 zookeeper 和三个 kafka 持久化存储
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
# cat kafka-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-my-cluster-zookeeper-0
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-my-cluster-zookeeper-1
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-my-cluster-zookeeper-2
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-0-my-cluster-kafka-0
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-0-my-cluster-kafka-1
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: data-0-my-cluster-kafka-2
namespace: kafka
spec:
storageClassName: nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
|
部署 kafka 和 zookeeper
参考官方仓库的样例,部署 3zookeeper 和 3kafka 的集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
# cat kafka.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: kafka
spec:
kafka:
version: 3.8.0
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: '3.8'
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 20Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
|
访问验证
查看资源 pod 和 svc


部署 kafka-ui
创建 configmap 和 ingress 资源,在 configmap 中指定 kafka 连接地址。以 traefik 为例,创建 ingress 资源便于通过域名方式访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[root@tiaoban kafka]# cat kafka-ui.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-ui-helm-values
namespace: kafka
data:
KAFKA_CLUSTERS_0_NAME: "kafka-cluster"
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: "my-cluster-kafka-brokers.kafka.svc:9092"
AUTH_TYPE: "DISABLED"
MANAGEMENT_HEALTH_LDAP_ENABLED: "FALSE"
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: kafka-ui
namespace: kafka
spec:
entryPoints:
- web
routes:
- match: Host(`kafka-ui.local.com`)
kind: Rule
services:
- name: kafka-ui
port: 80
[root@tiaoban kafka]# kubectl apply -f kafka-ui.yaml
configmap/kafka-ui-helm-values created
ingressroute.traefik.containo.us/kafka-ui created
|
helm 方式部署 kafka-ui 并指定配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 安装kafka-ui
helm repo add kafka-ui https://provectus.github.io/kafka-ui-charts
[root@tiaoban kafka]# helm install kafka-ui kafka-ui/kafka-ui -n kafka --set existingConfigMap="kafka-ui-helm-values"
NAME: kafka-ui
LAST DEPLOYED: Mon Oct 9 09:56:45 2023
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace kafka -l "app.kubernetes.io/name=kafka-ui,app.kubernetes.io/instance=kafka-ui" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace kafka port-forward $POD_NAME 8080:8080
|
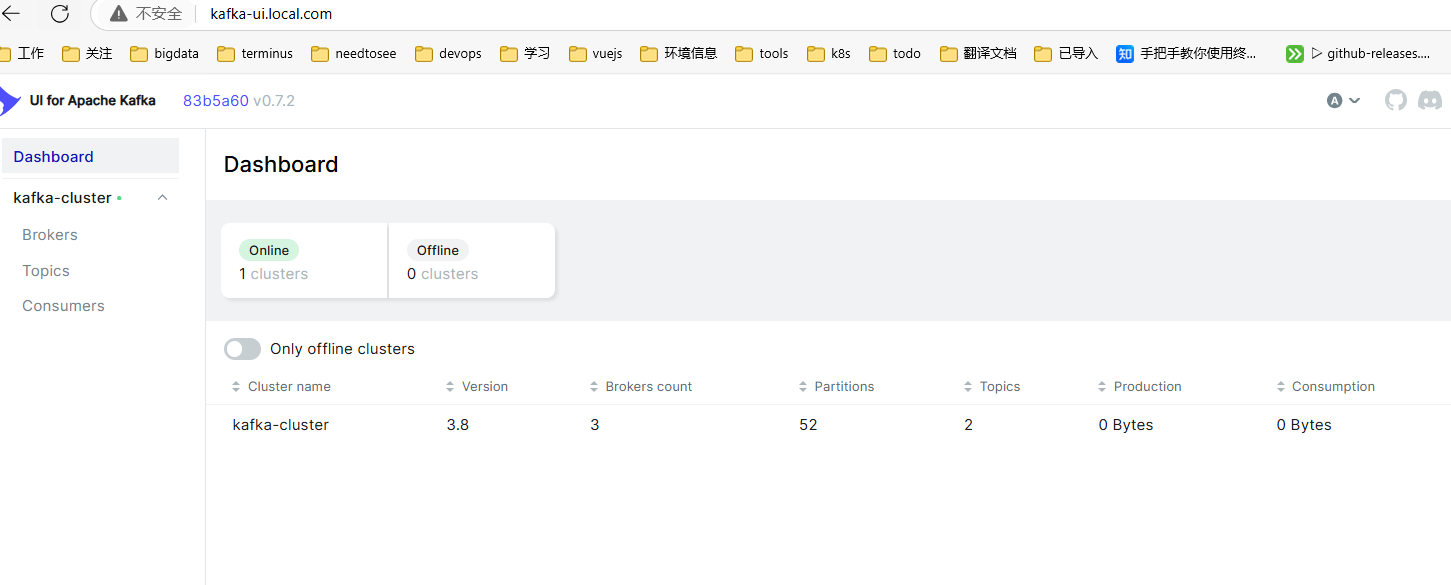
 添加 hosts 后,访问
添加 hosts 后,访问
filebeat 部署
资源清单
- rbac.yaml:创建 filebeat 用户和 filebeat 角色,并授予 filebeat 角色获取集群资源权限,并绑定角色与权限。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: elk
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
namespace: elk
rules:
- apiGroups: ["","apps","batch"]
resources: ["*"]
verbs:
- get
- watch
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
namespace: elk
subjects:
- kind: ServiceAccount
name: filebeat
namespace: elk
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
|
- filebeat-conf.yaml:使用 filebeat.autodiscover 方式自动获取 pod 日志,避免新增 pod 时日志采集不到的情况发生,并将日志发送到 kafka 消息队列中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: elk
data:
filebeat.yml: |-
filebeat.autodiscover:
providers: # 启用自动发现采集pod日志
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true
hints.default_config:
type: container
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
exclude_files: ['.*filebeat-.*'] # 排除filebeat自身日志采集
multiline: # 避免日志换行
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
processors:
- add_kubernetes_metadata: # 增加kubernetes的属性
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event: # 不收集debug日志
when:
contains:
message: "DEBUG"
output.kafka:
hosts: ["my-cluster-kafka-brokers.kafka.svc:9092"]
topic: "pod_logs"
partition.round_robin:
reachable_only: false
required_acks: -1
compression: gzip
monitoring: # monitoring相关配置
enabled: true
cluster_uuid: "ZUnqLCRqQL2jeo5FNvMI9g"
elasticsearch:
hosts: ["https://elasticsearch-es-http.elk.svc:9200"]
username: "elastic"
password: "2zg5q6AU7xW5jY649yuEpZ47"
ssl.verification_mode: "none"
|
- filebeat.yaml:使用 daemonset 方式每个节点运行一个 filebeat 容器,并挂载 filebeat 配置文件、数据目录、宿主机日志目录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: elk
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: harbor.local.com/elk/filebeat:8.9.1
args: ["-c","/etc/filebeat/filebeat.yml","-e"]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
cpu: 500m
memory: 1Gi
volumeMounts:
- name: timezone
mountPath: /etc/localtime
- name: config
mountPath: /etc/filebeat/filebeat.yml
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: containers
mountPath: /var/log/containers
readOnly: true
- name: logs
mountPath: /var/log/pods
volumes:
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: config
configMap:
name: filebeat-config
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
- name: containers
hostPath:
path: /var/log/containers
- name: logs
hostPath:
path: /var/log/pods
|
访问验证
查看 pod 信息,在集群每个节点上运行了一个 filebeat 采集容器。
通过 k9s 可以看见 filebeat 已经部署在 elk 的 namespace 下
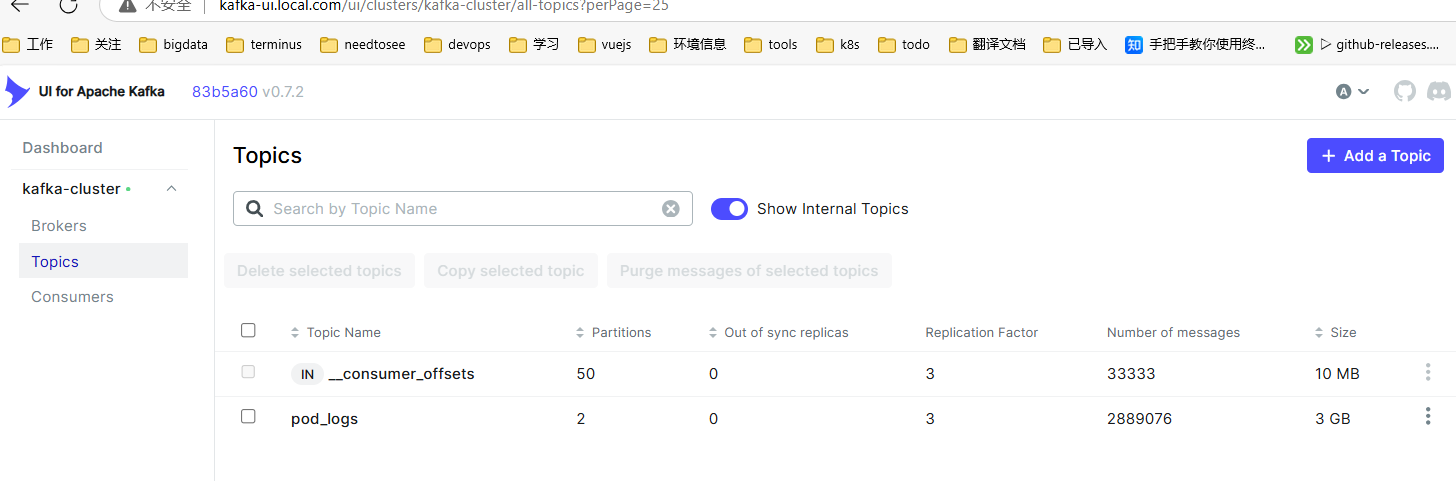
 查看 kafka topic 信息,已经成功创建了名为 pod_logs 的 topic,此时我们调整 partitions 为 2,方便 logstash 多副本消费。
查看 kafka topic 信息,已经成功创建了名为 pod_logs 的 topic,此时我们调整 partitions 为 2,方便 logstash 多副本消费。
Logstash 部署
构建镜像
由于 logstash 镜像默认不包含 geoip 地理位置数据库文件,如果需要解析 ip 位置信息时会存在解析失败的情况。因此需要提前构建包含 geoip 数据库文件的 logstash 镜像,并上传至 harbor 仓库中。
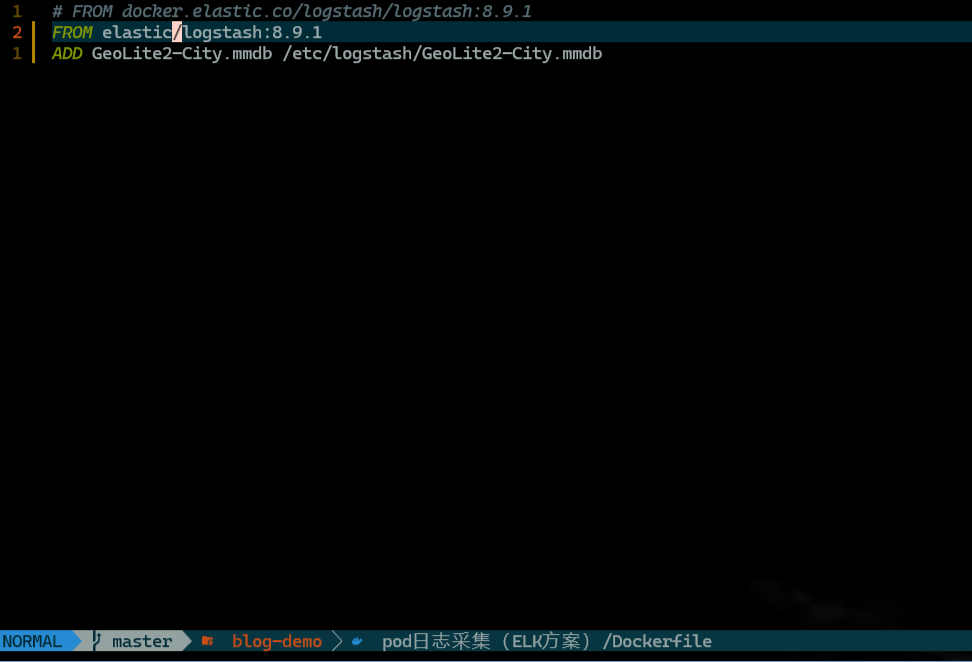
资源清单
- logstash-log4j2.yaml:容器方式运行时,logstash 日志默认使用的 console 输出, 不记录到日志文件中, logs 目录下面只有 gc.log,我们可以通过配置 log4j2 设置,将日志写入到文件中,方便 fleet 采集分析 logstash 日志。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
|
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-log4j2
namespace: elk
data:
log4j2.properties: |
status = error
name = LogstashPropertiesConfig
appender.console.type = Console
appender.console.name = plain_console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n
appender.json_console.type = Console
appender.json_console.name = json_console
appender.json_console.layout.type = JSONLayout
appender.json_console.layout.compact = true
appender.json_console.layout.eventEol = true
appender.rolling.type = RollingFile
appender.rolling.name = plain_rolling
appender.rolling.fileName = ${sys:ls.logs}/logstash-plain.log
appender.rolling.filePattern = ${sys:ls.logs}/logstash-plain-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 30
appender.rolling.avoid_pipelined_filter.type = PipelineRoutingFilter
appender.json_rolling.type = RollingFile
appender.json_rolling.name = json_rolling
appender.json_rolling.fileName = ${sys:ls.logs}/logstash-json.log
appender.json_rolling.filePattern = ${sys:ls.logs}/logstash-json-%d{yyyy-MM-dd}-%i.log.gz
appender.json_rolling.policies.type = Policies
appender.json_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.json_rolling.policies.time.interval = 1
appender.json_rolling.policies.time.modulate = true
appender.json_rolling.layout.type = JSONLayout
appender.json_rolling.layout.compact = true
appender.json_rolling.layout.eventEol = true
appender.json_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.json_rolling.policies.size.size = 100MB
appender.json_rolling.strategy.type = DefaultRolloverStrategy
appender.json_rolling.strategy.max = 30
appender.json_rolling.avoid_pipelined_filter.type = PipelineRoutingFilter
appender.routing.type = PipelineRouting
appender.routing.name = pipeline_routing_appender
appender.routing.pipeline.type = RollingFile
appender.routing.pipeline.name = appender-${ctx:pipeline.id}
appender.routing.pipeline.fileName = ${sys:ls.logs}/pipeline_${ctx:pipeline.id}.log
appender.routing.pipeline.filePattern = ${sys:ls.logs}/pipeline_${ctx:pipeline.id}.%i.log.gz
appender.routing.pipeline.layout.type = PatternLayout
appender.routing.pipeline.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n
appender.routing.pipeline.policy.type = SizeBasedTriggeringPolicy
appender.routing.pipeline.policy.size = 100MB
appender.routing.pipeline.strategy.type = DefaultRolloverStrategy
appender.routing.pipeline.strategy.max = 30
rootLogger.level = ${sys:ls.log.level}
rootLogger.appenderRef.console.ref = ${sys:ls.log.format}_console
rootLogger.appenderRef.rolling.ref = ${sys:ls.log.format}_rolling
rootLogger.appenderRef.routing.ref = pipeline_routing_appender
# Slowlog
appender.console_slowlog.type = Console
appender.console_slowlog.name = plain_console_slowlog
appender.console_slowlog.layout.type = PatternLayout
appender.console_slowlog.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n
appender.json_console_slowlog.type = Console
appender.json_console_slowlog.name = json_console_slowlog
appender.json_console_slowlog.layout.type = JSONLayout
appender.json_console_slowlog.layout.compact = true
appender.json_console_slowlog.layout.eventEol = true
appender.rolling_slowlog.type = RollingFile
appender.rolling_slowlog.name = plain_rolling_slowlog
appender.rolling_slowlog.fileName = ${sys:ls.logs}/logstash-slowlog-plain.log
appender.rolling_slowlog.filePattern = ${sys:ls.logs}/logstash-slowlog-plain-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling_slowlog.policies.type = Policies
appender.rolling_slowlog.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling_slowlog.policies.time.interval = 1
appender.rolling_slowlog.policies.time.modulate = true
appender.rolling_slowlog.layout.type = PatternLayout
appender.rolling_slowlog.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n
appender.rolling_slowlog.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling_slowlog.policies.size.size = 100MB
appender.rolling_slowlog.strategy.type = DefaultRolloverStrategy
appender.rolling_slowlog.strategy.max = 30
appender.json_rolling_slowlog.type = RollingFile
appender.json_rolling_slowlog.name = json_rolling_slowlog
appender.json_rolling_slowlog.fileName = ${sys:ls.logs}/logstash-slowlog-json.log
appender.json_rolling_slowlog.filePattern = ${sys:ls.logs}/logstash-slowlog-json-%d{yyyy-MM-dd}-%i.log.gz
appender.json_rolling_slowlog.policies.type = Policies
appender.json_rolling_slowlog.policies.time.type = TimeBasedTriggeringPolicy
appender.json_rolling_slowlog.policies.time.interval = 1
appender.json_rolling_slowlog.policies.time.modulate = true
appender.json_rolling_slowlog.layout.type = JSONLayout
appender.json_rolling_slowlog.layout.compact = true
appender.json_rolling_slowlog.layout.eventEol = true
appender.json_rolling_slowlog.policies.size.type = SizeBasedTriggeringPolicy
appender.json_rolling_slowlog.policies.size.size = 100MB
appender.json_rolling_slowlog.strategy.type = DefaultRolloverStrategy
appender.json_rolling_slowlog.strategy.max = 30
logger.slowlog.name = slowlog
logger.slowlog.level = trace
logger.slowlog.appenderRef.console_slowlog.ref = ${sys:ls.log.format}_console_slowlog
logger.slowlog.appenderRef.rolling_slowlog.ref = ${sys:ls.log.format}_rolling_slowlog
logger.slowlog.additivity = false
logger.licensereader.name = logstash.licensechecker.licensereader
logger.licensereader.level = error
# Silence http-client by default
logger.apache_http_client.name = org.apache.http
logger.apache_http_client.level = fatal
# Deprecation log
appender.deprecation_rolling.type = RollingFile
appender.deprecation_rolling.name = deprecation_plain_rolling
appender.deprecation_rolling.fileName = ${sys:ls.logs}/logstash-deprecation.log
appender.deprecation_rolling.filePattern = ${sys:ls.logs}/logstash-deprecation-%d{yyyy-MM-dd}-%i.log.gz
appender.deprecation_rolling.policies.type = Policies
appender.deprecation_rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.deprecation_rolling.policies.time.interval = 1
appender.deprecation_rolling.policies.time.modulate = true
appender.deprecation_rolling.layout.type = PatternLayout
appender.deprecation_rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c]%notEmpty{[%X{pipeline.id}]}%notEmpty{[%X{plugin.id}]} %m%n
appender.deprecation_rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.deprecation_rolling.policies.size.size = 100MB
appender.deprecation_rolling.strategy.type = DefaultRolloverStrategy
appender.deprecation_rolling.strategy.max = 30
logger.deprecation.name = org.logstash.deprecation, deprecation
logger.deprecation.level = WARN
logger.deprecation.appenderRef.deprecation_rolling.ref = deprecation_plain_rolling
logger.deprecation.additivity = false
logger.deprecation_root.name = deprecation
logger.deprecation_root.level = WARN
logger.deprecation_root.appenderRef.deprecation_rolling.ref = deprecation_plain_rolling
logger.deprecation_root.additivity = false
|
- logstash-conf.yaml:修改 Logstash 配置,禁用默认的指标收集配置,并指定 es 集群 uuid。
1
2
3
4
5
6
7
8
9
10
11
|
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
namespace: elk
data:
logstash.conf: |
api.enabled: true
api.http.port: 9600
xpack.monitoring.enabled: false
monitoring.cluster_uuid: "ZUnqLCRqQL2jeo5FNvMI9g"
|
- pod-pipeline.yaml:配置 pipeline 处理 pod 日志规则,从 kafka 读取数据后移除非必要的字段,然后写入 ES 集群中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-pod-pipeline
namespace: elk
data:
pipeline.conf: |
input {
kafka {
bootstrap_servers=>"my-cluster-kafka-brokers.kafka.svc:9092"
auto_offset_reset => "latest"
topics=>["pod_logs"]
codec => "json"
group_id => "pod"
}
}
filter {
mutate {
remove_field => ["agent","event","ecs","host","[kubernetes][labels]","input","log","orchestrator","stream"]
}
}
output{
elasticsearch{
hosts => ["https://elasticsearch-es-http.elk.svc:9200"]
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "pod"
data_stream_namespace => "elk"
user => "elastic"
password => "2zg5q6AU7xW5jY649yuEpZ47"
ssl_enabled => "true"
ssl_verification_mode => "none"
}
}
|
- pod-logstash.yaml:部署 2 副本的 logstash 容器,挂载 pipeline、log4j2、logstash 配置文件、日志路径资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash-pod
namespace: elk
spec:
replicas: 2
selector:
matchLabels:
app: logstash-pod
template:
metadata:
labels:
app: logstash-pod
monitor: enable
spec:
securityContext:
runAsUser: 0
containers:
- image: harbor.local.com/elk/logstash:v8.9.1
name: logstash-pod
resources:
limits:
cpu: "1"
memory: 1Gi
args:
- -f
- /usr/share/logstash/pipeline/pipeline.conf
env:
- name: XPACK_MONITORING_ENABLED
value: "false"
ports:
- containerPort: 9600
volumeMounts:
- name: timezone
mountPath: /etc/localtime
- name: config
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
- name: log4j2
mountPath: /usr/share/logstash/config/log4j2.properties
subPath: log4j2.properties
- name: pipeline
mountPath: /usr/share/logstash/pipeline/pipeline.conf
subPath: pipeline.conf
- name: log
mountPath: /usr/share/logstash/logs
volumes:
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: config
configMap:
name: logstash-config
- name: log4j2
configMap:
name: logstash-log4j2
- name: pipeline
configMap:
name: logstash-pod-pipeline
- name: log
hostPath:
path: /var/log/logstash
type: DirectoryOrCreate
|
- logstash-svc.yaml:创建 svc 资源,用于暴露 logstash 监控信息接口。
1
2
3
4
5
6
7
8
9
10
11
|
apiVersion: v1
kind: Service
metadata:
name: logstash-monitor
namespace: elk
spec:
selector:
monitor: enable
ports:
- port: 9600
targetPort: 9600
|
添加监控指标采集
在 kibana 集成策略中安装 logstash 集群,并配置 metrics 接口地址为http://logstash-monitor.elk.svc:9600,注意部署节点Elastic Agent on ECK policy
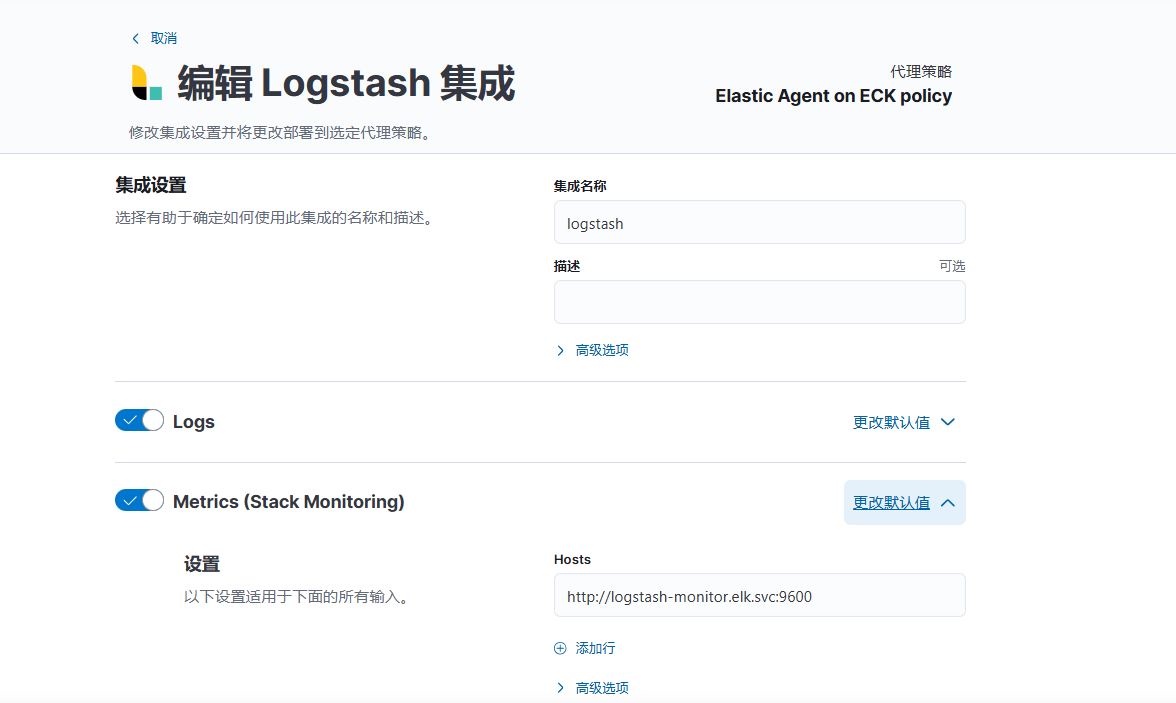
访问验证
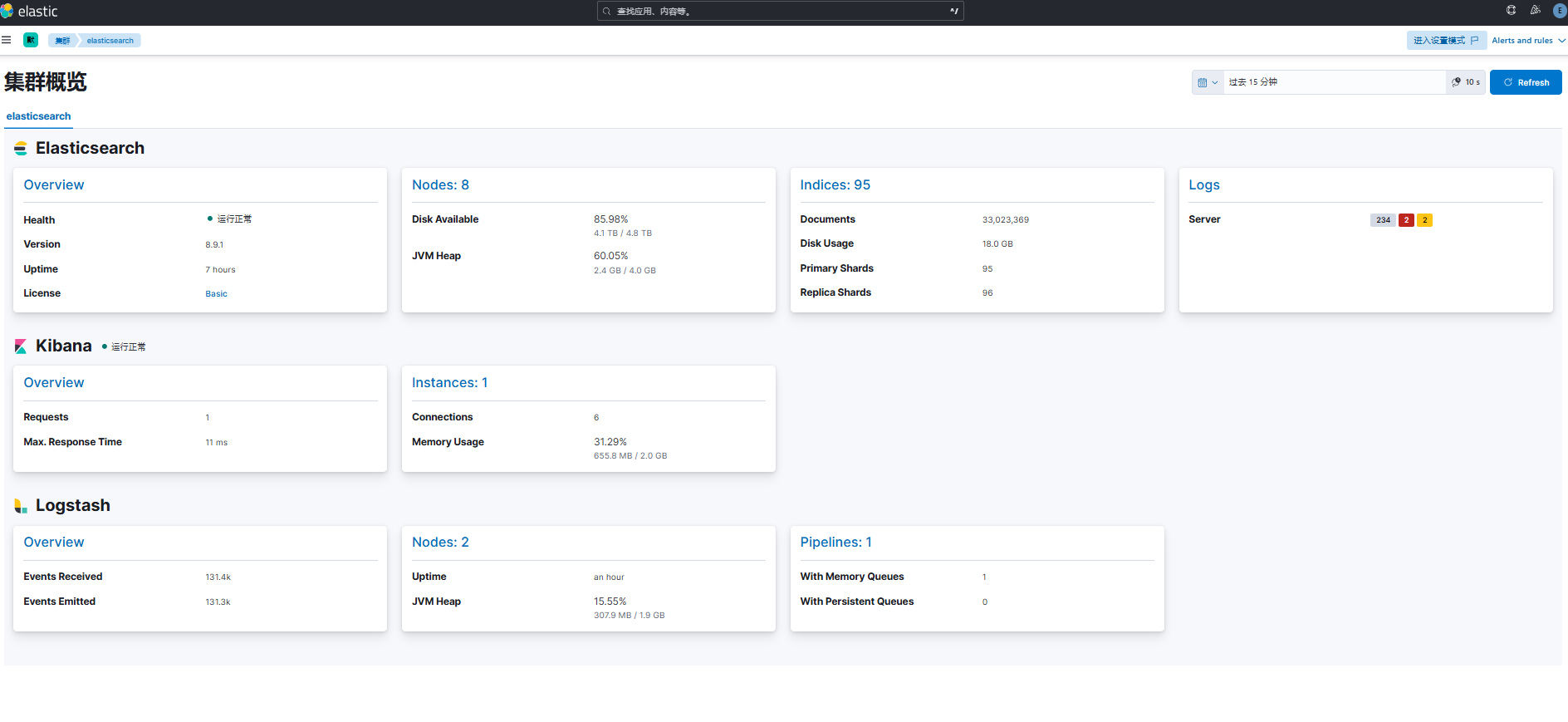
查看 pod 信息,已正常运行 2 副本的 logstash。
 登录 kibana 查看监控信息,已成功采集 filebeat 和 logstash 指标和日志数据。
登录 kibana 查看监控信息,已成功采集 filebeat 和 logstash 指标和日志数据。
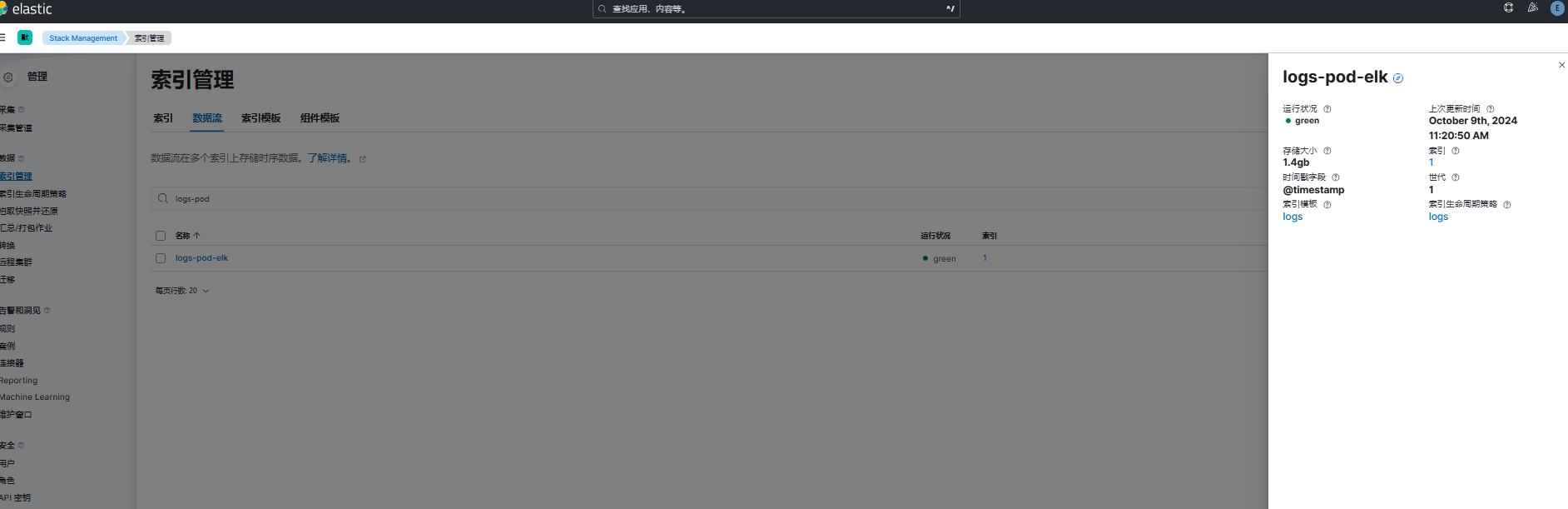
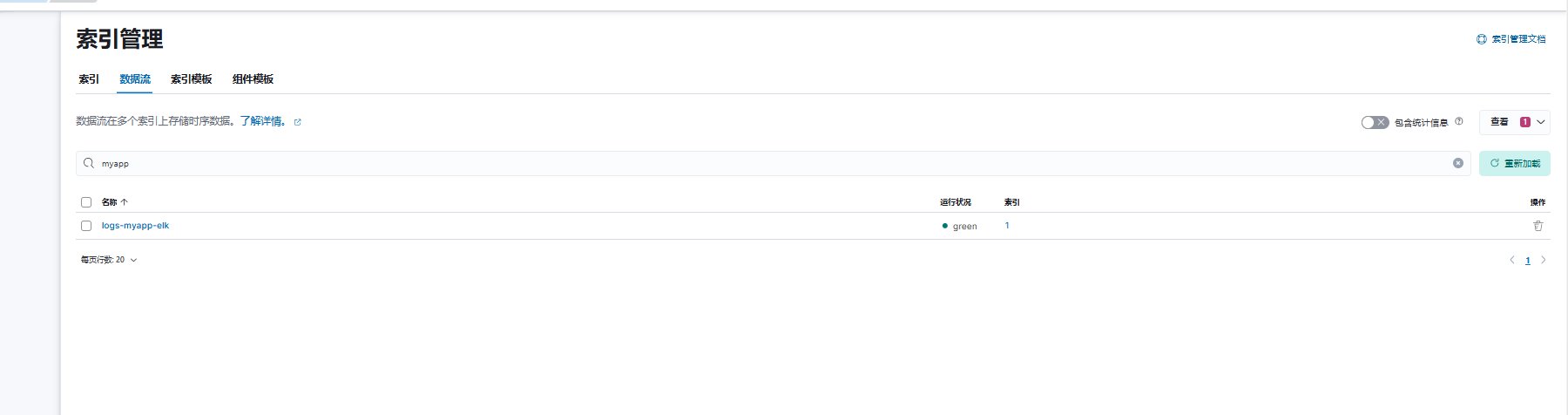
 查看数据流信息,已成功创建名为 logs-pod-elk 的数据流。
查看数据流信息,已成功创建名为 logs-pod-elk 的数据流。
查看数据流内容,成功存储解析了 pod 所在节点、namespace、container、日志内容等数据。
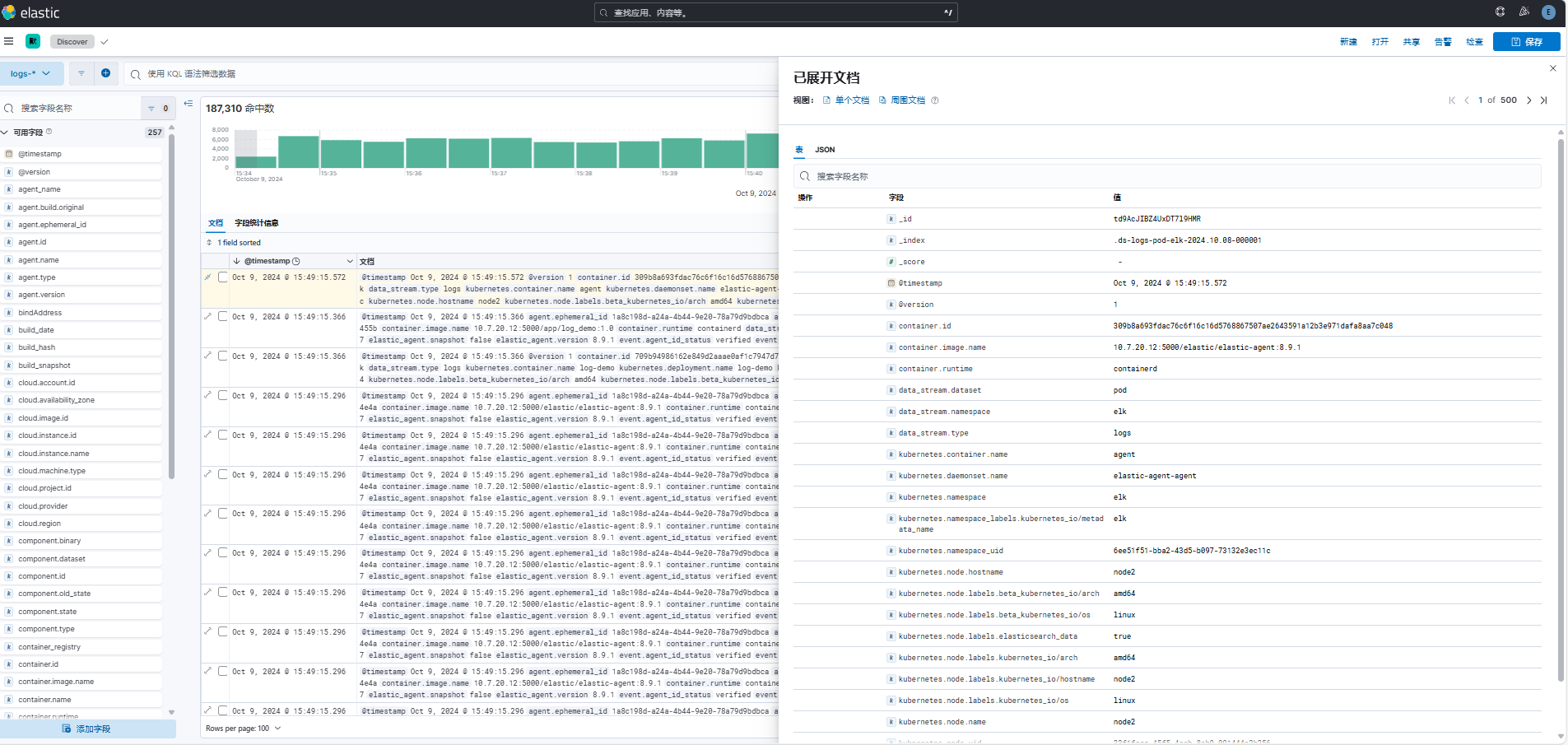
自定义日志解析
需求分析
默认情况下,fluent bit 会采集所有 pod 日志信息,并自动添加 namespace、pod、container 等信息,所有日志内容存储在 log 字段中。
以 log-demo 应为日志为例,将所有日志内容存储到 log 字段下,如果想要按条件筛选分析日志数据时,无法很好的解析日志内容,因此需要配置 logstash 解析规则,实现日志自定义日志内容解析。
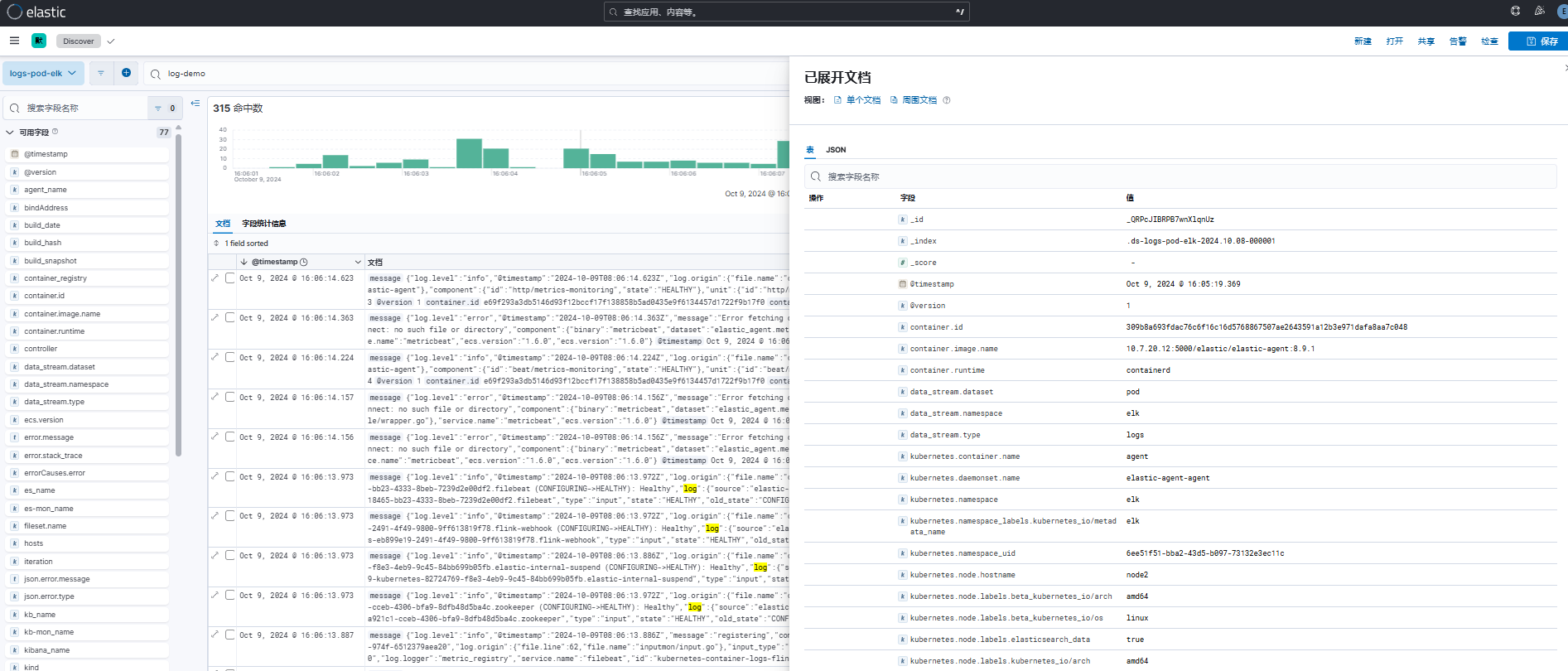
资源清单
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-myapp-pipeline
namespace: elk
data:
pipeline.conf: |
input {
kafka {
bootstrap_servers=>"my-cluster-kafka-brokers.kafka.svc:9092"
auto_offset_reset => "latest"
topics=>["pod_logs"]
codec => "json"
group_id => "myapp"
}
}
filter {
if [kubernetes][deployment][name] == "log-demo" {
grok{
match => {"message" => "%{TIMESTAMP_ISO8601:log_timestamp} \| %{LOGLEVEL:level} %{SPACE}* \| (?<class>[__main__:[\w]*:\d*]+) \- %{GREEDYDATA:content}"}
}
mutate {
gsub =>[
"content", "'", '"'
]
lowercase => [ "level" ]
}
json {
source => "content"
}
geoip {
source => "remote_address"
database => "/etc/logstash/GeoLite2-City.mmdb"
ecs_compatibility => disabled
}
mutate {
remove_field => ["agent","event","ecs","host","[kubernetes][labels]","input","log","orchestrator","stream","content"]
}
}
else {
drop{}
}
}
output{
elasticsearch{
hosts => ["https://elasticsearch-es-http.elk.svc:9200"]
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "myapp"
data_stream_namespace => "elk"
user => "elastic"
password => "2zg5q6AU7xW5jY649yuEpZ47"
ssl_enabled => "true"
ssl_verification_mode => "none"
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash-myapp
namespace: elk
spec:
replicas: 2
selector:
matchLabels:
app: logstash-myapp
template:
metadata:
labels:
app: logstash-myapp
monitor: enable
spec:
securityContext:
runAsUser: 0
containers:
- image: harbor.local.com/elk/logstash:v8.9.1
name: logstash-myapp
resources:
limits:
cpu: "1"
memory: 1Gi
args:
- -f
- /usr/share/logstash/pipeline/pipeline.conf
env:
- name: XPACK_MONITORING_ENABLED
value: "false"
ports:
- containerPort: 9600
volumeMounts:
- name: timezone
mountPath: /etc/localtime
- name: config
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
- name: log4j2
mountPath: /usr/share/logstash/config/log4j2.properties
subPath: log4j2.properties
- name: pipeline
mountPath: /usr/share/logstash/pipeline/pipeline.conf
subPath: pipeline.conf
- name: log
mountPath: /usr/share/logstash/logs
volumes:
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: config
configMap:
name: logstash-config
- name: log4j2
configMap:
name: logstash-log4j2
- name: pipeline
configMap:
name: logstash-myapp-pipeline
- name: log
hostPath:
path: /var/log/logstash
type: DirectoryOrCreate
|
访问验证
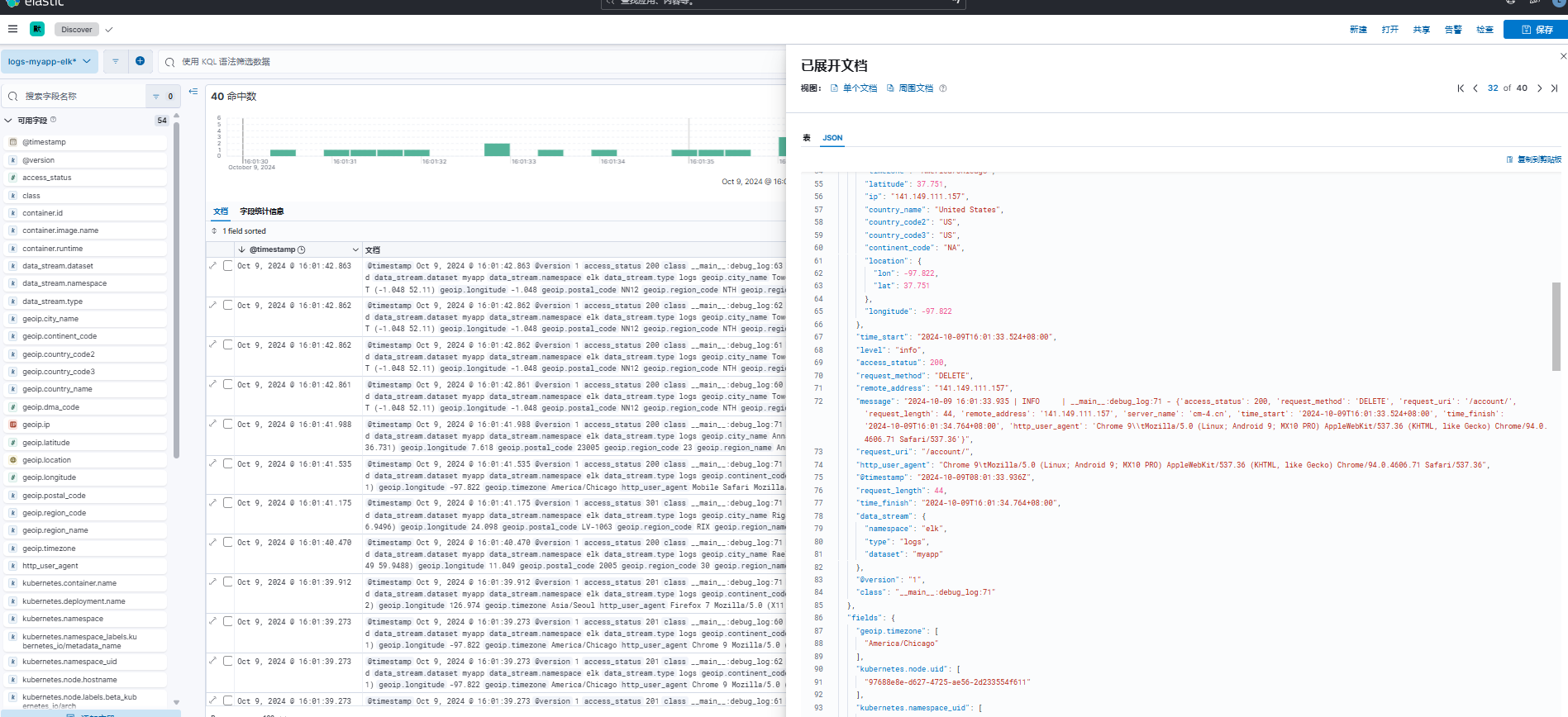
查看数据流信息,已成功创建名为 logs-myapp-elk 的数据流。
 查看数据流详细内容,成功解析了日志相关字段数据。
查看数据流详细内容,成功解析了日志相关字段数据。
注意事项
kafka partition 数配置
需要注意的是每个 consumer 最多只能使用一个 partition,当一个 Group 内 consumer 的数量大于 partition 的数量时,只有等于 partition 个数的 consumer 能同时消费,其他的 consumer 处于等待状态。因此想要增加 logstash 的消费性能,可以适当的增加 topic 的 partition 数量,但 kafka 中 partition 数量过多也会导致 kafka 集群故障恢复时间过长。
logstash 副本数配置
Logstash 副本数=kafka partition 数/每个 logstash 线程数(默认为 1,数据量大时可增加线程数,建议不超过 4)
完整资源清单
本实验案例所有 yaml 文件已上传至 git 仓库。访问地址如下:
github
https://github.com/cuiliang0302/blog-demo
gitee
https://gitee.com/cuiliang0302/blog_demo
参考文档
helm 部署 Strimzi:https://strimzi.io/docs/operators/latest/deploying#deploying-cluster-operator-helm-chart-str
filebeat 通过自动发现采集 k8s 日志:https://www.elastic.co/guide/en/beats/filebeat/current/configuration-autodiscover-hints.html
kubernetes 集群运行 filebeat:https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
filebeat 处理器新增 kubernetes 元数据信息:https://www.elastic.co/guide/en/beats/filebeat/current/add-kubernetes-metadata.html
filebeat 丢弃指定事件:https://www.elastic.co/guide/en/beats/filebeat/current/drop-event.html
logstash 参数设置最佳实践:https://www.elastic.co/guide/en/logstash/current/tips.html