今天遇到以下报错:
|
|
原因:
当 CoreDNS 日志包含messageLoop ... detected ...时,这意味着 loop 检测插件在上游 DNS 服务器之一中检测到无限转发循环。这是一个致命错误,因为使用无限循环操作会消耗内存和 CPU,直到主机最终内存不足而死亡。
转发循环通常由以下原因引起:
- 最常见的是,CoreDNS 将请求直接转发给自己。例如,通过环回地址,例如 127.0.0.1,::1 或 127.0.0.53
- 不太常见的是,CoreDNS 转发到上游服务器,然后将请求转发回 CoreDNS。
要解决此问题,请在您的 Corefile 中查找forward检测到循环的区域的任何 s。确保它们没有转发到本地地址或将请求转发回CoreDNS的另一个 DNS 服务器。如果 forward 正在使用文件(例如/etc/resolv.conf),请确保该文件不包含本地地址。
排查 Kubernetes 集群中的循环
当部署在 Kubernetes 中的 CoreDNS Pod 检测到循环时,CoreDNS Pod 将开始“CrashLoopBackOff”。这是因为每次 CoreDNS 检测到循环并退出时,Kubernetes 都会尝试重启 Pod。
systemd-resolvedKubernetes 集群中转发循环的一个常见原因是与主机节点(例如)上的本地 DNS 缓存的交互。例如,在某些配置中,systemd-resolved 会将环回地址 127.0.0.53 作为名称服务器放入/etc/resolv.conf. 默认情况下, Kubernetes(通过 kubelet)将使用 dnsPolicy 将此/etc/resolv.conf 文件传递给所有 defaultPod,使它们无法进行 DNS 查找(包括 CoreDNS Pod)。CoreDNS 使用它/etc/resolv.conf 作为上游列表来转发请求。由于它包含一个环回地址,CoreDNS 最终会将请求转发给它自己。
有很多方法可以解决这个问题,这里列出了一些:
- 将以下内容添加到您的 kubelet 配置 yaml 中:(resolvConf: 或通过–resolv-conf1.10 中已弃用的命令行标志)。您的“真实” resolv.conf 是包含您的上游服务器的实际 IP,并且没有本地/环回地址的那个。该标志告诉 kubelet 将替代传递 resolv.conf 给 Pod。对于使用 的系统 systemd-resolved, /run/systemd/resolve/resolv.conf 通常是“真实”的位置 resolv.conf,尽管这可能因您的发行版而异。
- 禁用主机节点上的本地 DNS 缓存,并恢复/etc/resolv.conf 到原始状态。
- 一个快速而肮脏的解决方法是编辑您的 Corefile,替换 forward . /etc/resolv.conf 为上游 DNS 的 IP 地址,例如 forward . 8.8.8.8. 但这仅解决了 CoreDNS 的问题,kubelet 将继续将无效的转发 resolv.conf 到所有 defaultdnsPolicy Pod,使它们无法解析 DNS。
解决方法
检查 Node 节点的 DNS 文件
|
|
但是发现问题不是这个样子的,修改之后依然报错了。
最后解决办法
删除 configmap 的 nodelocaldns 和 coredns 的 loop 插件即可。
最后总结一下,这个报错是 loop 插件看到有配置循环,但是这个东西,在其他几个节点都是正常的,但是 master 节点上总是报错
参考资料:

这里引出了另一个问题,自定义的 dns 如何配置文档: https://www.qikqiak.com/post/resolve-coredns-hosts-invalid/
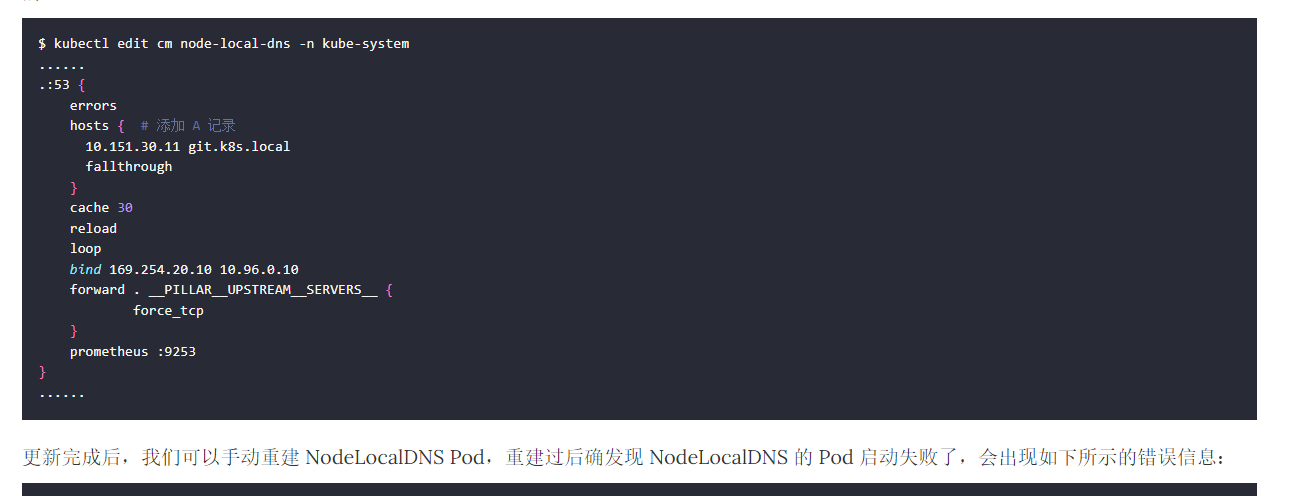
还没碰到的现象
coredns 总是 timeout
- https://github.com/kubernetes/kubernetes/issues/86762
- 添加 iptables 规则,重启 coredns
|
|