转载:http://xinzhuxiansheng.com/articleDetail/
引言
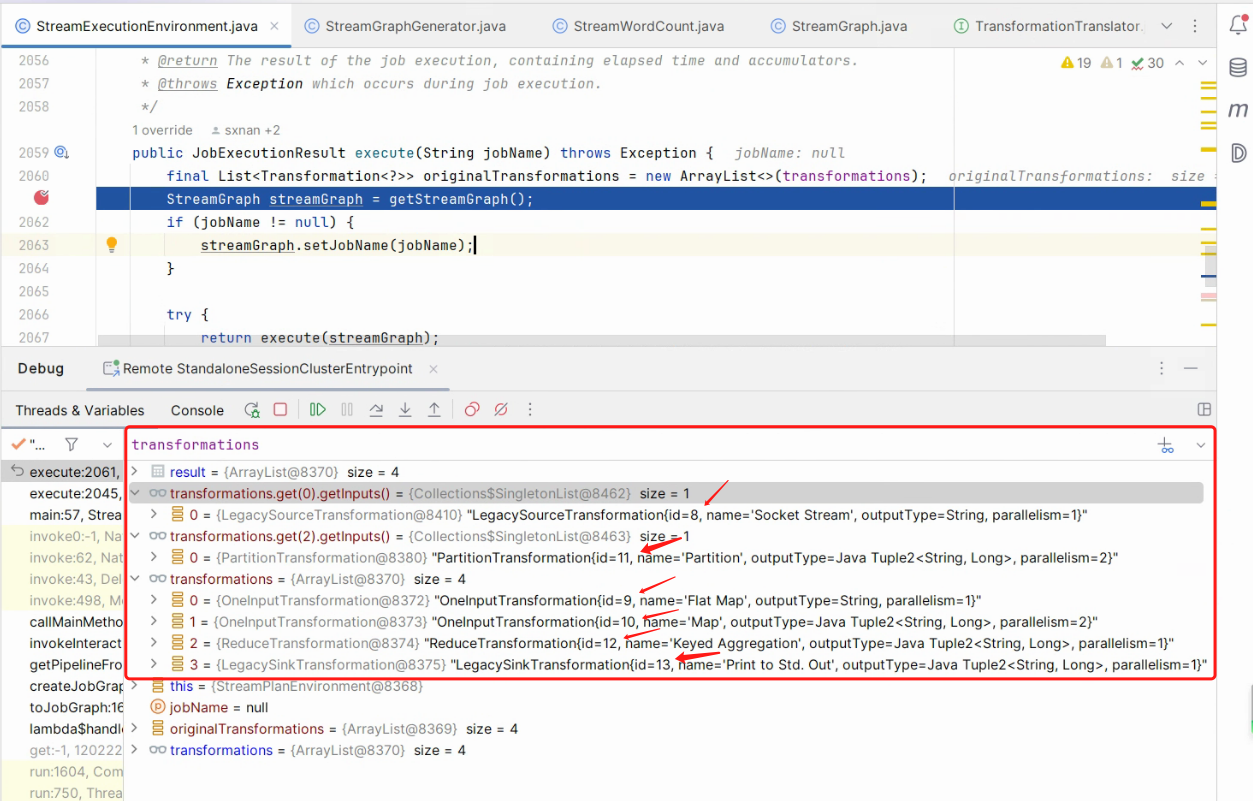
回顾之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”中的 StreamWordCount 示例中 .socketTextStream().flatMap().map().keyBy().sum() API 链路转换成 transformations 集合,同时每个 transformations 包含一个序号 id, 经过 StreamGraphGenerator会创建一个 StreamGraph 对象,其内部包含 streamNodes (真实节点),virtualPartitionNodes(虚拟节点)同时也会为虚拟节点生成一个 id,StreamGraph 的 streamNodes 和它每个子项中的 inEdges,outEdges 构成了一个有向无环图, 而 virtualPartitionNodes虚拟节点 它的每个子项是是由虚拟节点的 id 作为 key,而 value 是由上游的 streamNode id,StreamPartitioner 和 StreamExchangeMode 组成,这里特别注意,StreamGraph没有并发数的概念,所以,一个 streamNode,就仅代表一个节点,那 StreamWordCount 案例构成图如下:

List<Transformation> transformations:
transformations 链路的完整性是由 self 和它的 parent inputs 拼接而成的。
StreamGraph.streamNodes:
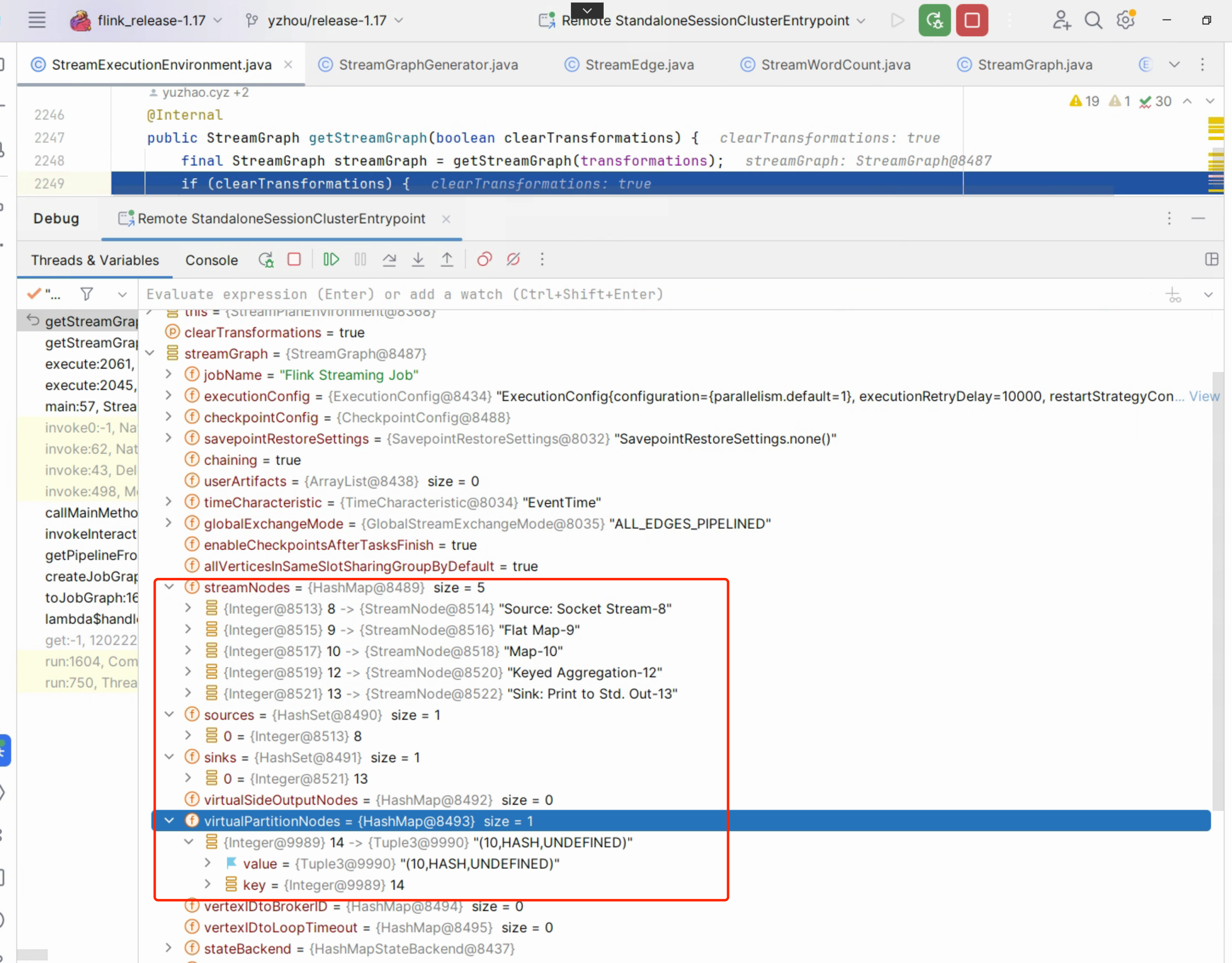
于上面关于 StreamGraph 的回顾,接下来,主要内容是 StreamGraph 转换成 JobGraph 的过程。
StreamGraph 转换成 JobGrap
回顾入口
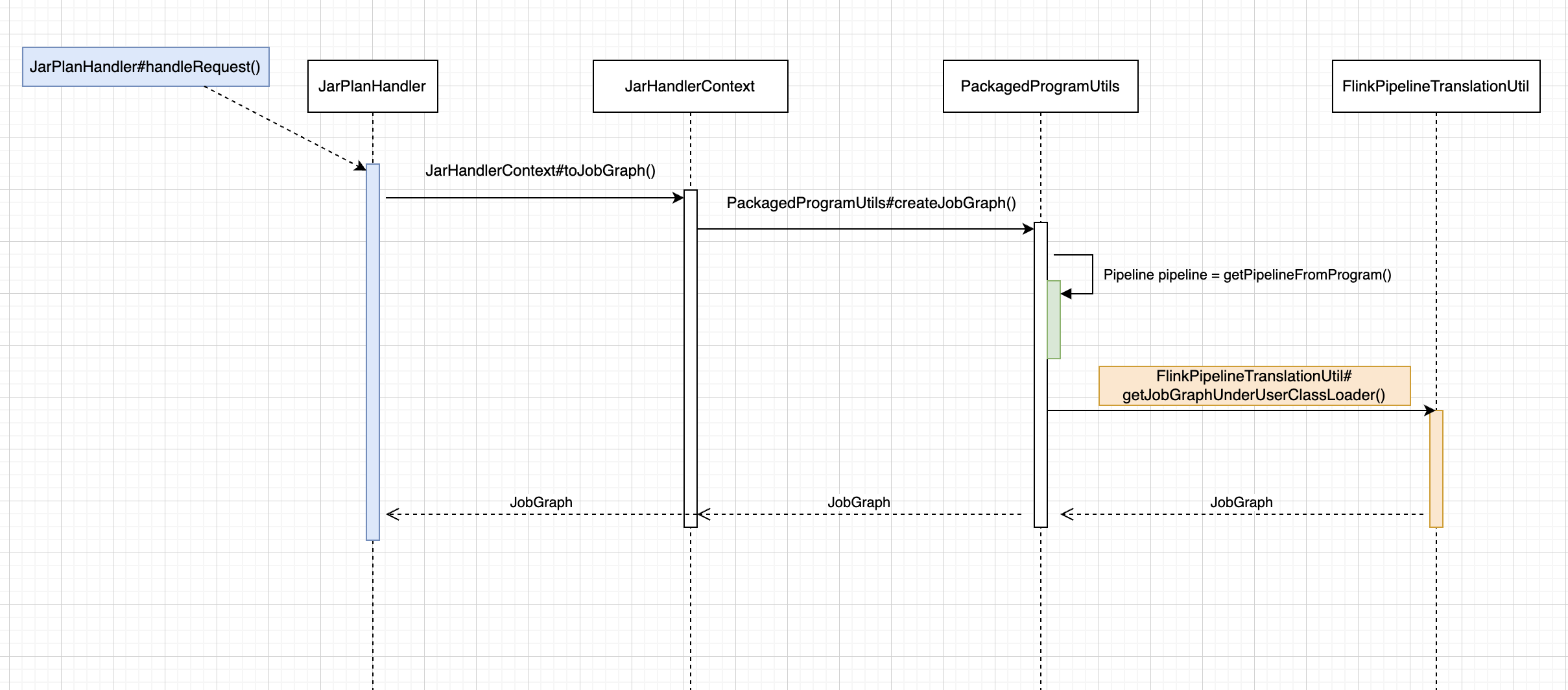
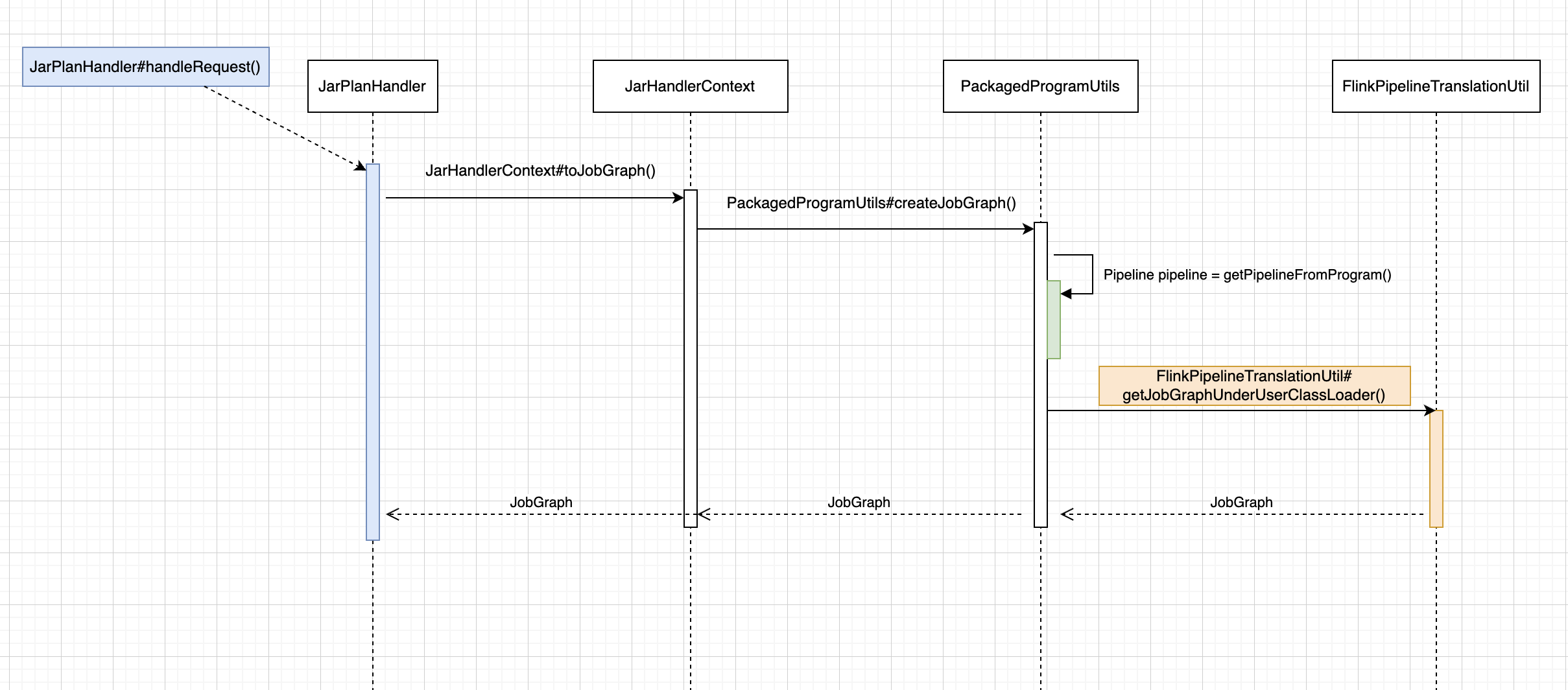
入口PackagedProgramUtils#createJobGraph() 下面是 Flink Job Show Plan入口流程图:
在之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”中大部分内容都在介绍 Pipeline pipeline = getPipelineFromProgram(...)的执行逻辑,也就是 StreamGraph,接下来关注的核心方法是:
1
2
3
4
5
6
|
final JobGraph jobGraph =
FlinkPipelineTranslationUtil.getJobGraphUnderUserClassLoader(
packagedProgram.getUserCodeClassLoader(),
pipeline,
configuration,
defaultParallelism);
|
首先使用一个流程图来说明 JobGraph 构造的入口调用关系,从 PackagedProgramUtils#createJobGraph() 定位到 StreamingJobGraphGenerator#createJobGraph()。
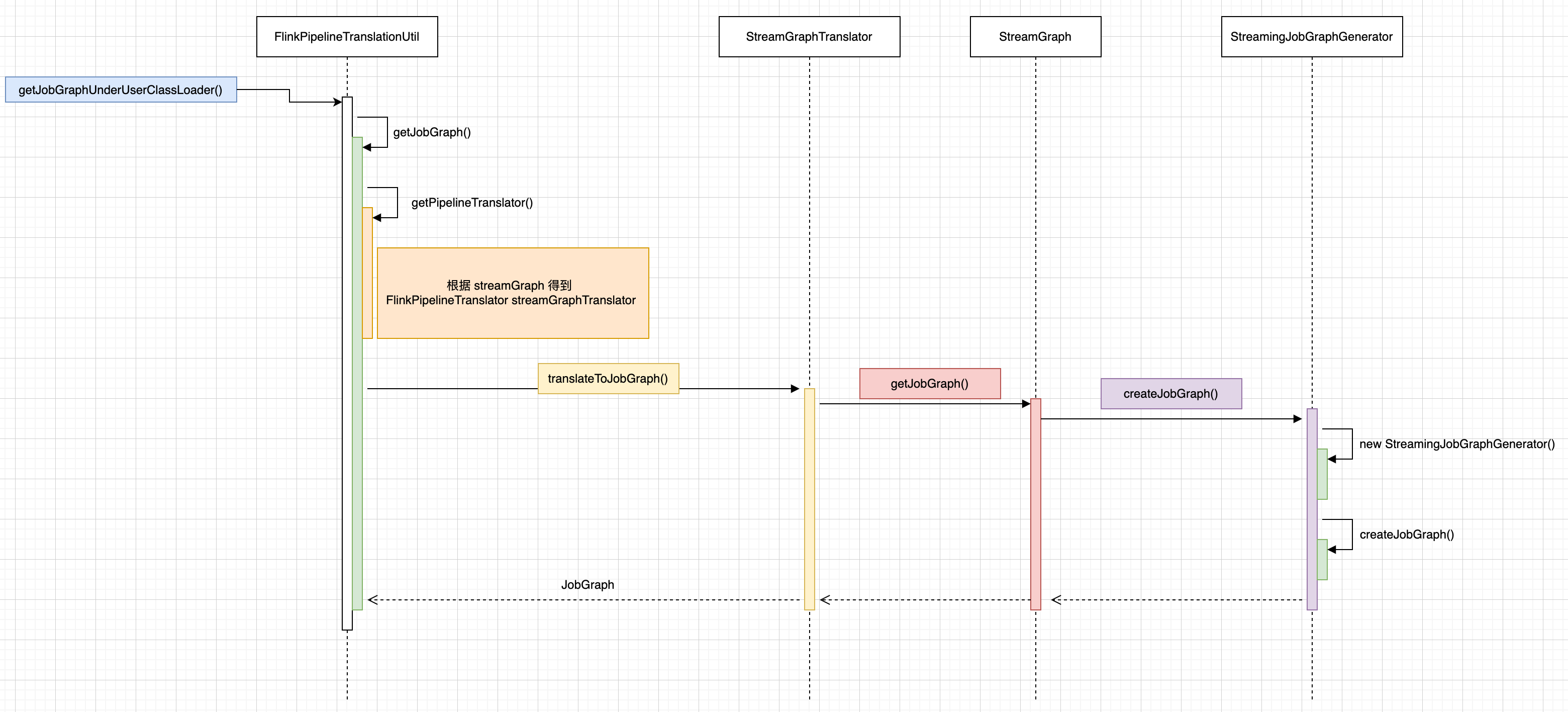
StreamingJobGraphGenerator#createJobGraph()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.setDynamic(streamGraph.isDynamic());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
if (jobGraph.isDynamic()) {
setVertexParallelismsForDynamicGraphIfNecessary();
}
// Note that we set all the non-chainable outputs configuration here because the
// "setVertexParallelismsForDynamicGraphIfNecessary" may affect the parallelism of job
// vertices and partition-reuse
final Map<Integer, Map<StreamEdge, NonChainedOutput>> opIntermediateOutputs =
new HashMap<>();
setAllOperatorNonChainedOutputsConfigs(opIntermediateOutputs);
setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs);
setPhysicalEdges();
markSupportingConcurrentExecutionAttempts();
validateHybridShuffleExecuteInBatchMode();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
jobGraph.setChangelogStateBackendEnabled(streamGraph.isChangelogStateBackendEnabled());
addVertexIndexPrefixInVertexName();
setVertexDescription();
// Wait for the serialization of operator coordinators and stream config.
try {
FutureUtils.combineAll(
vertexConfigs.values().stream()
.map(
config ->
config.triggerSerializationAndReturnFuture(
serializationExecutor))
.collect(Collectors.toList()))
.get();
waitForSerializationFuturesAndUpdateJobVertices();
} catch (Exception e) {
throw new FlinkRuntimeException("Error in serialization.", e);
}
if (!streamGraph.getJobStatusHooks().isEmpty()) {
jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
}
return jobGraph;
}
|
初始化 JobGraph 对象的一些属性值
在创建StreamingJobGraphGenerator对象时,也会 JobGraph 对象,首先会给 jobGraph 赋值一些属性值,例如 jodID,jobName,jobType 以及开启本地恢复。
1
2
3
4
5
6
7
8
9
|
jobGraph = new JobGraph(jobID, streamGraph.getJobName());
...省略部分代码
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.setDynamic(streamGraph.isDynamic());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
|
为 StreamNode 生成确定性 hash
调用defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes() 为所有节点生成 hash,变量defaultStreamGraphHasher是 StreamGraphHasher 接口类型,在 StreamingJobGraphGenerator的构造方法中,使用 this.defaultStreamGraphHasher = new StreamGraphHasherV2(); 作为它的默认实现。
1
2
3
4
5
|
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
|
StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()方法会涉及到图的广度优先遍历算法,这里先补充下关于广度优先遍历:
在广度优先遍历中,我们通常使用一个队列(Queue)来存储待访问的节点。初始时,将起始节点放入队列。然后,执行以下操作直到队列为空:
1.从队列中取出一个节点。
2.访问该节点,并将其标记为已访问。
3.将该节点的所有未被访问的邻近节点加入队列。
示例演示流程:
下面是一颗二叉树,现在要其使用广度优先遍历。
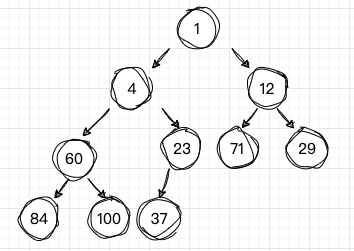 开始访问
开始访问 num1,然后将 num1 插入 队列Q ,注意这是“首次入队”
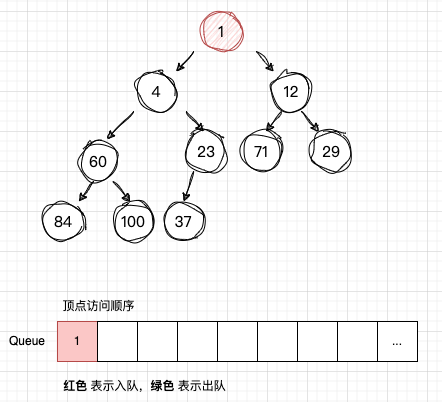
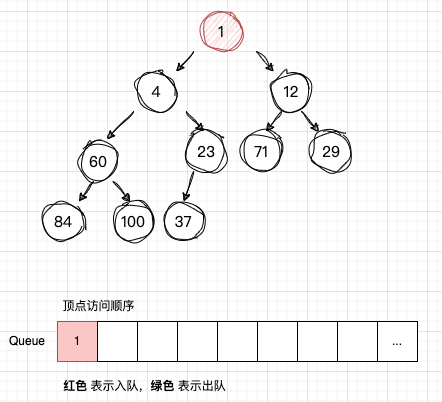
-
从队列Q读取 num1,获取num1 的子节点:num4 , num12,并且依次入队
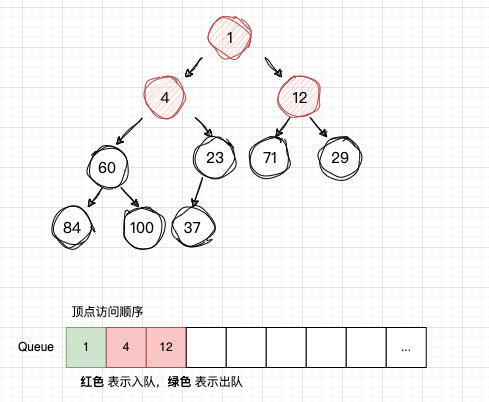
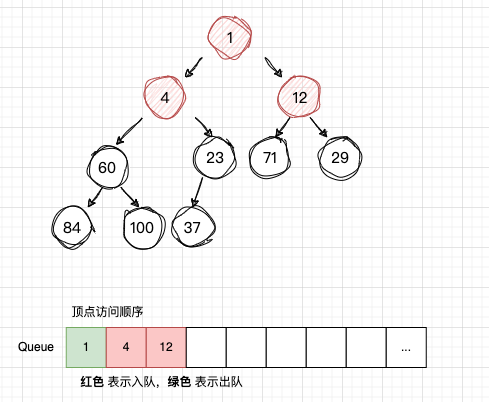
-
从队列Q读取 num4,获取num4 的子节点:num60 , num23,并且依次入队
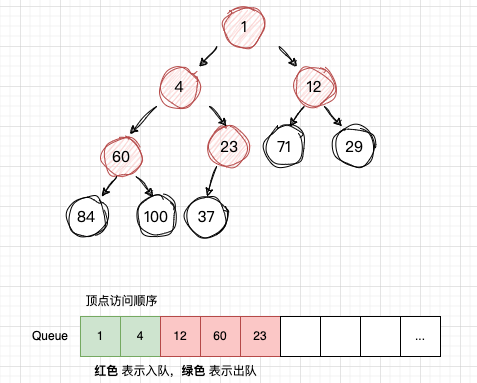
-
从队列Q读取 num12,获取num12 的子节点:num71 , num29,并且依次入队
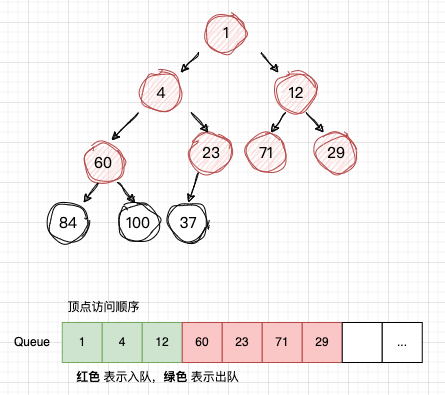
依次类推,
到这里,差不多可以写出一段伪代码:
1
2
3
4
5
6
7
8
|
创建队列 Q
将 root 节点 放入 Q中
while((node = Q.poll()!=null)){
获取 node 的子节点,subNodes;
将 subNodes for循环 添加到 队列 Q中
}
|
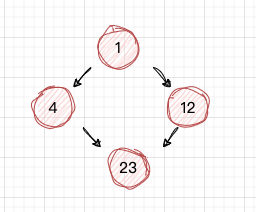
这样就完成了 广度优先遍历,其实在图数据结构中,它与树最大不同的是节点和边可以形成一个循环,它的节点和边的关系放在邻接表。 所以图的广度优先遍历,需要一个集合来判断当前节点是否遍历过,看下图中的 num23, 当 num4和num12 出队后,都读取了num23,显然它读取了2遍,所以 判断一个节点是否遍历过,是很重要的。
 接下来,看
接下来,看StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()的实现过程。
在StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()方法中,创建了 Set visited 、 Queue remaining 和 List sources , visited 存储已访问过的节点, remaining 存储待访问的节点, sources 存储 StreamGraph的 顶端节点。
for 循环,将 sources 节点放入 remaining,visited 集合中。
1
2
3
4
|
for (Integer sourceNodeId : sources) {
remaining.add(streamGraph.getStreamNode(sourceNodeId));
visited.add(sourceNodeId);
}
|
然后利用 while 循环遍历 remaining 队列里面的子项,在if 调用 generateNodeHash() 生成 hash值,并put 到 hashes集合中,但显然它也会返回 false。 这显然有些符合我们的示例中的预期,访问的结果一般不会希望再移除它,让它有机会再访问一次。 下面结合generateNodeHash()的实现来介绍后续处理逻辑;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
while ((currentNode = remaining.poll()) != null) {
// Generate the hash code. Because multiple path exist to each
// node, we might not have all required inputs available to
// generate the hash code.
if (generateNodeHash(
currentNode,
hashFunction,
hashes,
streamGraph.isChainingEnabled(),
streamGraph)) {
// Add the child nodes
for (StreamEdge outEdge : currentNode.getOutEdges()) {
StreamNode child = streamGraph.getTargetVertex(outEdge);
if (!visited.contains(child.getId())) {
remaining.add(child);
visited.add(child.getId());
}
}
} else {
// We will revisit this later.
visited.remove(currentNode.getId());
}
}
|
StreamGraphHasherV2#generateNodeHash()方法是生成 Node的hash 值的核心方法,下面是它的流程图:
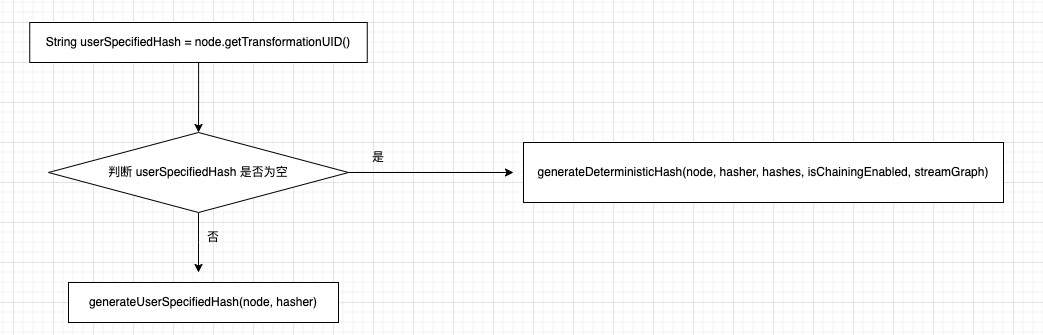
若用户通过 uid()函数配置了 transformationUID值,则重新初始化 hasher 计算 hash值, 否则调用generateDeterministicHash() 创建 hash 值, 不过 generateDeterministicHash()方法内部 generateNodeLocalHash()方法更让人琢磨不透,似乎 Hasher对象 生成hash 值有某种顺序似的。
hashes集合是在 StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes() 创建的,在 StreamGraph 的广度遍历过程中,计算 Operator的 Hash值 并放入 hashes 集合中, 下面是generateNodeLocalHash()方法的注释,其实目的是一目了然,StreamNode id计算 hash 无法保证它的不变性,所以,它使用 hashes 的下标,因为 StreamGraph 构造的图是一个有向图。
1
2
3
4
|
// Include stream node to hash. We use the current size of the computed
// hashes as the ID. We cannot use the node's ID, because it is
// assigned from a static counter. This will result in two identical
// programs having different hashes.
|
如果当前 Node 的父节点存在没有计算好 hash值,则返回 false,将它从 visited集群移除掉
1
2
3
4
5
6
7
8
9
10
11
12
|
if (userSpecifiedHash == null) {
// Check that all input nodes have their hashes computed
for (StreamEdge inEdge : node.getInEdges()) {
// If the input node has not been visited yet, the current
// node will be visited again at a later point when all input
// nodes have been visited and their hashes set.
if (!hashes.containsKey(inEdge.getSourceId())) {
return false;
}
}
// ...
|
为了验证上面需要优先遍历SourceId的逻辑,举一个示例说明,注意该示例其实没有什么业务逻辑价值,仅是为了拼凑Show Plan的链路,达到验证的效果。
StreamWordCountMultipleSourceVariation.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public class StreamWordCountMultipleSourceVariation {
private static Logger logger = LoggerFactory.getLogger(StreamWordCountMultipleSourceVariation.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(new Configuration());
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));
DataStreamSource<String> source1 = env.socketTextStream("localhost", 7777);
DataStreamSource<String> source2 = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String, Long>> source2Transformed = source2
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.setParallelism(2);
DataStream<String> source1AndTransformedSource2 = source1.union(source2Transformed.map(t -> t.f0).returns(Types.STRING));
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = source1AndTransformedSource2
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.setParallelism(2);
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1).setParallelism(1).uid("wc-sum");
result.print();
env.execute();
}
}
|
对上面示例进行打包mvn clean package, 然后在 Flink WEB UI 的 Submit New Job上传 Jar,点击Show Plan 得到下面拓扑图:
 在之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”中大部分内容都在介绍
在之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”中大部分内容都在介绍 Pipeline pipeline = getPipelineFromProgram(...)的执行逻辑,也就是 StreamGraph,接下来关注的核心方法是:
1
2
3
4
5
6
|
final JobGraph jobGraph =
FlinkPipelineTranslationUtil.getJobGraphUnderUserClassLoader(
packagedProgram.getUserCodeClassLoader(),
pipeline,
configuration,
defaultParallelism);
|
首先使用一个流程图来说明 JobGraph 构造的入口调用关系,从 PackagedProgramUtils#createJobGraph() 定位到 StreamingJobGraphGenerator#createJobGraph()。
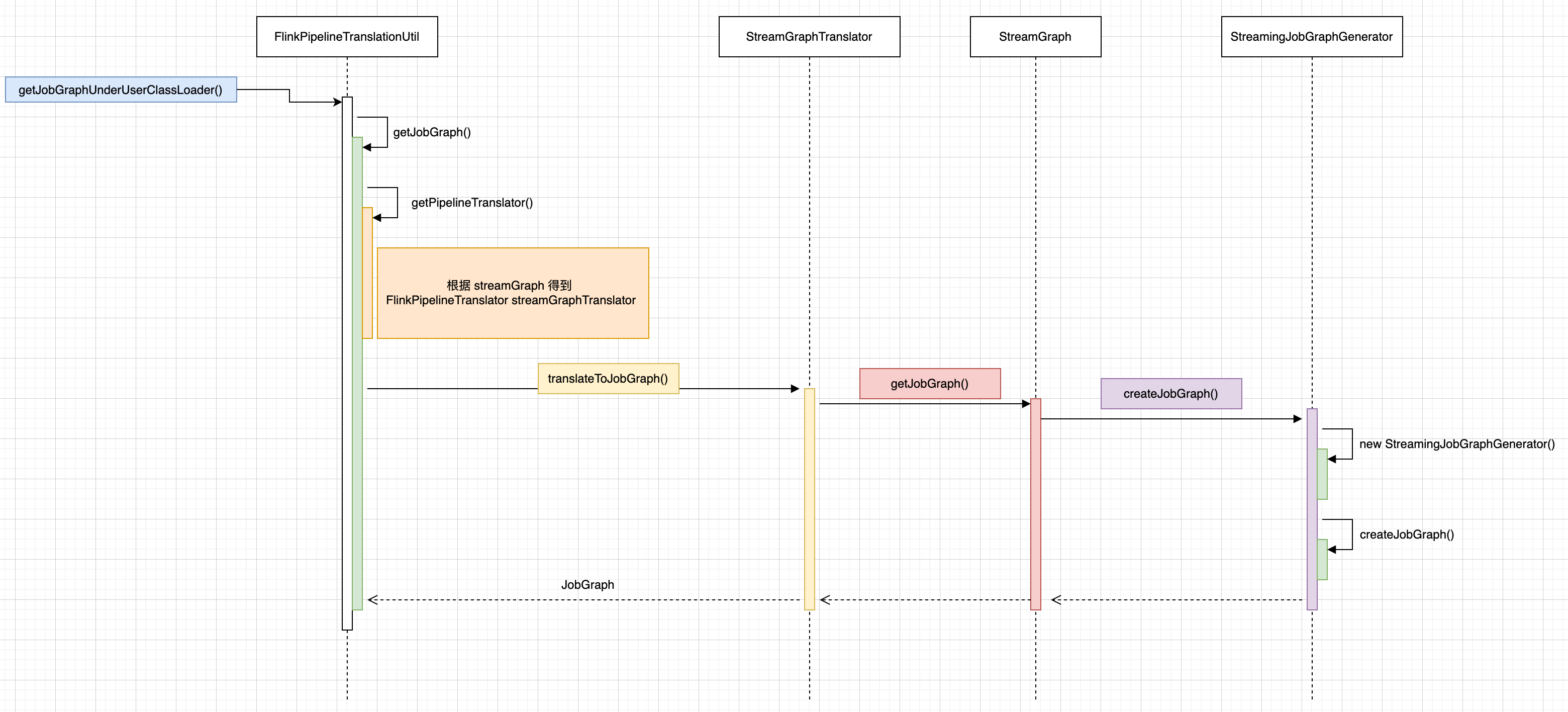
StreamingJobGraphGenerator#createJobGraph()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.setDynamic(streamGraph.isDynamic());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
if (jobGraph.isDynamic()) {
setVertexParallelismsForDynamicGraphIfNecessary();
}
// Note that we set all the non-chainable outputs configuration here because the
// "setVertexParallelismsForDynamicGraphIfNecessary" may affect the parallelism of job
// vertices and partition-reuse
final Map<Integer, Map<StreamEdge, NonChainedOutput>> opIntermediateOutputs =
new HashMap<>();
setAllOperatorNonChainedOutputsConfigs(opIntermediateOutputs);
setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs);
setPhysicalEdges();
markSupportingConcurrentExecutionAttempts();
validateHybridShuffleExecuteInBatchMode();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
jobGraph.setChangelogStateBackendEnabled(streamGraph.isChangelogStateBackendEnabled());
addVertexIndexPrefixInVertexName();
setVertexDescription();
// Wait for the serialization of operator coordinators and stream config.
try {
FutureUtils.combineAll(
vertexConfigs.values().stream()
.map(
config ->
config.triggerSerializationAndReturnFuture(
serializationExecutor))
.collect(Collectors.toList()))
.get();
waitForSerializationFuturesAndUpdateJobVertices();
} catch (Exception e) {
throw new FlinkRuntimeException("Error in serialization.", e);
}
if (!streamGraph.getJobStatusHooks().isEmpty()) {
jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
}
return jobGraph;
}
|
初始化 JobGraph 对象的一些属性值
在创建StreamingJobGraphGenerator对象时,也会 JobGraph 对象,首先会给 jobGraph 赋值一些属性值,例如 jodID,jobName,jobType 以及开启本地恢复。
1
2
3
4
5
6
7
8
9
|
jobGraph = new JobGraph(jobID, streamGraph.getJobName());
...省略部分代码
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.setDynamic(streamGraph.isDynamic());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
|
为 StreamNode 生成确定性 hash
调用defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes() 为所有节点生成 hash,变量defaultStreamGraphHasher是 StreamGraphHasher 接口类型,在 StreamingJobGraphGenerator的构造方法中,使用 this.defaultStreamGraphHasher = new StreamGraphHasherV2(); 作为它的默认实现。
1
2
3
4
5
|
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
|
StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()方法会涉及到图的广度优先遍历算法,这里先补充下关于广度优先遍历:
在广度优先遍历中,我们通常使用一个队列(Queue)来存储待访问的节点。初始时,将起始节点放入队列。然后,执行以下操作直到队列为空:
1.从队列中取出一个节点。
2.访问该节点,并将其标记为已访问。
3.将该节点的所有未被访问的邻近节点加入队列。
示例演示流程:
下面是一颗二叉树,现在要其使用广度优先遍历。
开始访问 num1,然后将 num1 插入 队列Q ,注意这是“首次入队”
从队列Q读取 num1,获取num1 的子节点:num4 , num12,并且依次入队
从队列Q读取 num4,获取num4 的子节点:num60 , num23,并且依次入队
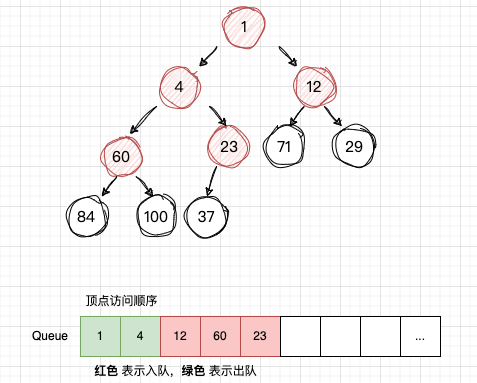 从
从队列Q读取 num12,获取num12 的子节点:num71 , num29,并且依次入队
依次类推,
到这里,差不多可以写出一段伪代码:
1
2
3
4
5
6
7
8
|
创建队列 Q
将 root 节点 放入 Q中
while((node = Q.poll()!=null)){
获取 node 的子节点,subNodes;
将 subNodes for循环 添加到 队列 Q中
}
|
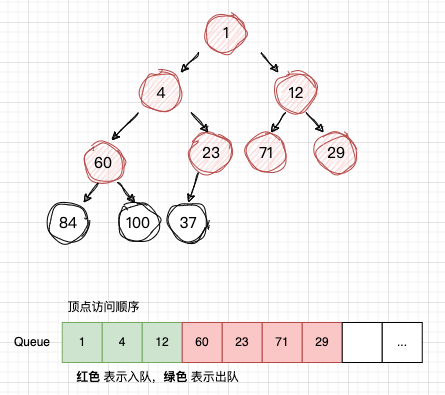
这样就完成了 广度优先遍历,其实在图数据结构中,它与树最大不同的是节点和边可以形成一个循环,它的节点和边的关系放在邻接表。 所以图的广度优先遍历,需要一个集合来判断当前节点是否遍历过,看下图中的 num23, 当 num4和num12 出队后,都读取了num23,显然它读取了2遍,所以 判断一个节点是否遍历过,是很重要的。
接下来,看StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()的实现过程。
在StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes()方法中,创建了 Set visited 、 Queue remaining 和 List sources , visited 存储已访问过的节点, remaining 存储待访问的节点, sources 存储 StreamGraph的 顶端节点。
for 循环,将 sources 节点放入 remaining,visited 集合中。
1
2
3
4
5
|
for (Integer sourceNodeId : sources) {
remaining.add(streamGraph.getStreamNode(sourceNodeId));
visited.add(sourceNodeId);
}
|
然后利用 while 循环遍历 remaining 队列里面的子项,在if 调用 generateNodeHash() 生成 hash值,并put 到 hashes集合中,但显然它也会返回 false。 这显然有些符合我们的示例中的预期,访问的结果一般不会希望再移除它,让它有机会再访问一次。 下面结合generateNodeHash()的实现来介绍后续处理逻辑;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
while ((currentNode = remaining.poll()) != null) {
// Generate the hash code. Because multiple path exist to each
// node, we might not have all required inputs available to
// generate the hash code.
if (generateNodeHash(
currentNode,
hashFunction,
hashes,
streamGraph.isChainingEnabled(),
streamGraph)) {
// Add the child nodes
for (StreamEdge outEdge : currentNode.getOutEdges()) {
StreamNode child = streamGraph.getTargetVertex(outEdge);
if (!visited.contains(child.getId())) {
remaining.add(child);
visited.add(child.getId());
}
}
} else {
// We will revisit this later.
visited.remove(currentNode.getId());
}
}
|
StreamGraphHasherV2#generateNodeHash()方法是生成 Node的hash 值的核心方法,下面是它的流程图:
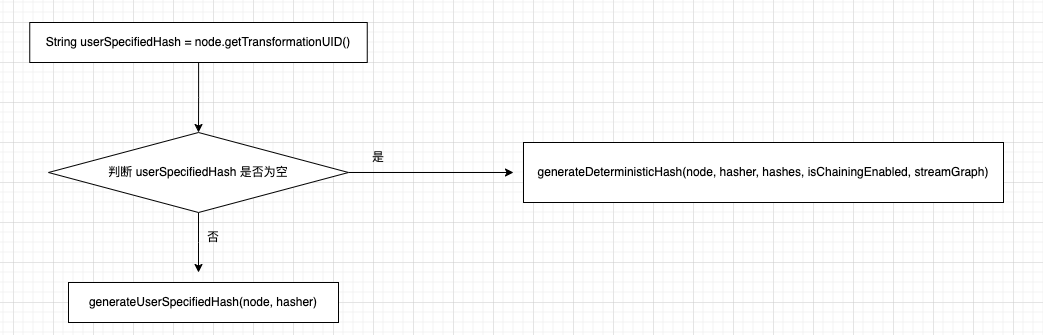
若用户通过 uid()函数配置了 transformationUID值,则重新初始化 hasher 计算 hash值, 否则调用generateDeterministicHash() 创建 hash 值, 不过 generateDeterministicHash()方法内部 generateNodeLocalHash()方法更让人琢磨不透,似乎 Hasher对象 生成hash 值有某种顺序似的。
hashes集合是在 StreamGraphHasherV2#traverseStreamGraphAndGenerateHashes() 创建的,在 StreamGraph 的广度遍历过程中,计算 Operator的 Hash值 并放入 hashes 集合中, 下面是generateNodeLocalHash()方法的注释,其实目的是一目了然,StreamNode id计算 hash 无法保证它的不变性,所以,它使用 hashes 的下标,因为 StreamGraph 构造的图是一个有向图。
1
2
3
4
5
|
// Include stream node to hash. We use the current size of the computed
// hashes as the ID. We cannot use the node's ID, because it is
// assigned from a static counter. This will result in two identical
// programs having different hashes.
|
如果当前 Node 的父节点存在没有计算好 hash值,则返回 false,将它从 visited集群移除掉
1
2
3
4
5
6
7
8
9
10
11
12
|
if (userSpecifiedHash == null) {
// Check that all input nodes have their hashes computed
for (StreamEdge inEdge : node.getInEdges()) {
// If the input node has not been visited yet, the current
// node will be visited again at a later point when all input
// nodes have been visited and their hashes set.
if (!hashes.containsKey(inEdge.getSourceId())) {
return false;
}
}
// ...
|
为了验证上面需要优先遍历SourceId的逻辑,举一个示例说明,注意该示例其实没有什么业务逻辑价值,仅是为了拼凑Show Plan的链路,达到验证的效果。
StreamWordCountMultipleSourceVariation.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public class StreamWordCountMultipleSourceVariation {
private static Logger logger = LoggerFactory.getLogger(StreamWordCountMultipleSourceVariation.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(new Configuration());
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));
DataStreamSource<String> source1 = env.socketTextStream("localhost", 7777);
DataStreamSource<String> source2 = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String, Long>> source2Transformed = source2
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.setParallelism(2);
DataStream<String> source1AndTransformedSource2 = source1.union(source2Transformed.map(t -> t.f0).returns(Types.STRING));
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = source1AndTransformedSource2
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.setParallelism(2);
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS.sum(1).setParallelism(1).uid("wc-sum");
result.print();
env.execute();
}
}
|
对上面示例进行打包mvn clean package, 然后在 Flink WEB UI 的 Submit New Job上传 Jar,点击Show Plan 得到下面拓扑图:
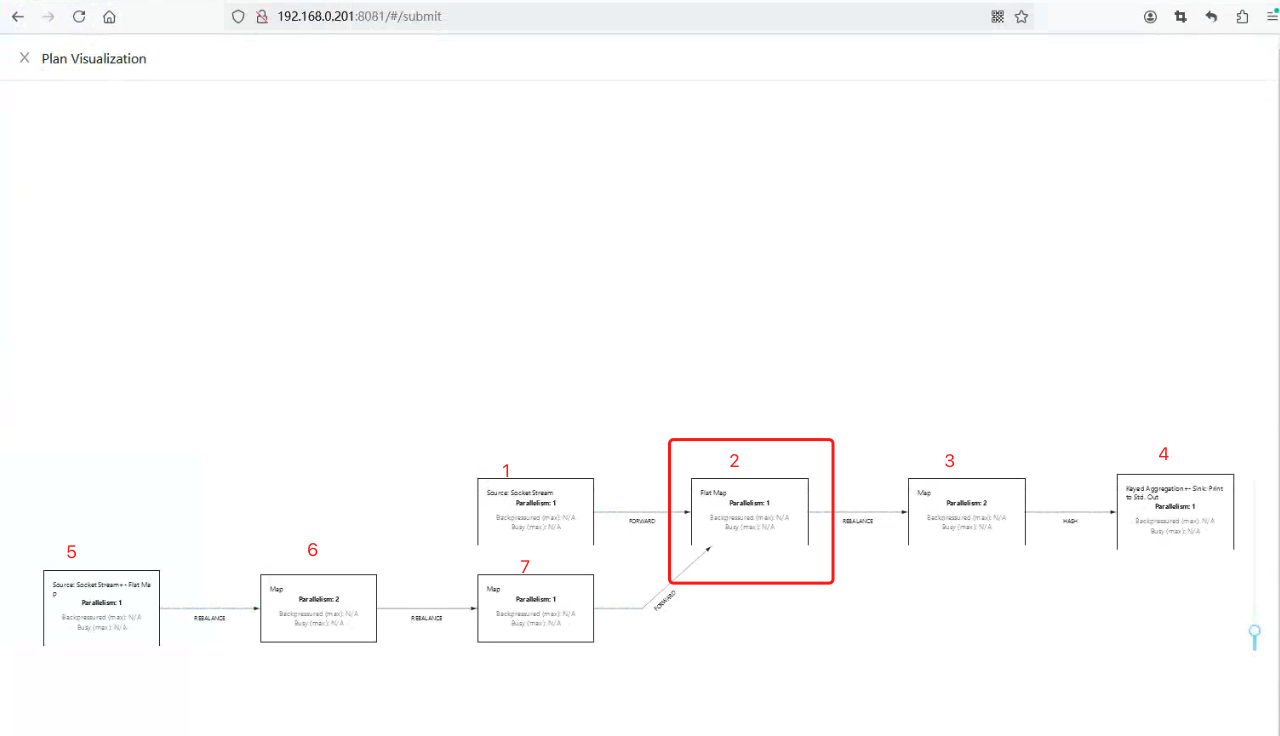
我对图中的节点进行标记了序号,注意,我们暂时不讨论节点的具体含义,但并没有忽略它与上游节点的关系处理,例如 我们将这种与上游关系的处理成为handlerUpstreamRelationships() ,仅是讨论图的广度遍历过程,图片中2个Source 起点,分别是 num1,num5, 那么按照广度遍历,将 num1,num2放入队列,若 num1 优先出队,num2再放入队列,此时队列中是[num5,num2], 完成读取后,将 num5出队,num6放入队列,此时队列中是[num2,num6], 在这之前每个numx出队都会去处理handlerUpstreamRelationships(),接着 num2 出队,你会发现它的上游 num1,num7, 我们仅处理了 num1,因为 num6还没有出队,所以num7还未处理到,所以 num2 应该延缓到 num7处理完后再处理handlerUpstreamRelationships()。
上面的测试 Case,表达的意思是,如果遍历某个节点时,它的上游节点(父节点)没有处理过,那它暂时不能处理,需上游节点处理过后,才能轮到自己。
那么回到 StreamGraphHasherV2#generateNodeHash()方法中的 for循环, 若hashes 处理过的集合中不包含它的上游节点,则返回 false。
1
2
3
4
5
6
7
8
9
|
for (StreamEdge inEdge : node.getInEdges()) {
// If the input node has not been visited yet, the current
// node will be visited again at a later point when all input
// nodes have been visited and their hashes set.
if (!hashes.containsKey(inEdge.getSourceId())) {
return false;
}
}
|
若上游节点都遍历过后,会调用generateDeterministicHash() 计算 Node 的 hash 值,注意其内部方法generateNodeLocalHash(hasher, hashes.size()) 将hashes.size()作为哈希算法的输入值(即以当前节点在 StreamGraph 中遍历位置作为哈希算法的输入参数)
1
2
3
4
5
6
|
// Include stream node to hash. We use the current size of the computed
// hashes as the ID. We cannot use the node's ID, because it is
// assigned from a static counter. This will result in two identical
// programs having different hashes.
generateNodeLocalHash(hasher, hashes.size());
|
还需注意它与是否能和下游节点 chain一起的个数有关,通过 for 循环遍历当前节点的 OutEdges,同时判断是否可以 chain在一起。
1
2
3
4
5
6
7
8
9
10
|
// Include chained nodes to hash
for (StreamEdge outEdge : node.getOutEdges()) {
if (isChainable(outEdge, isChainingEnabled, streamGraph)) {
// Use the hash size again, because the nodes are chained to
// this node. This does not add a hash for the chained nodes.
generateNodeLocalHash(hasher, hashes.size());
}
}
|
针对isChainable的处理逻辑:首选下游节点的 输入边大小只能为1(downStreamVertex.getInEdges().size() == 1); 在 isSameSlotSharingGroup()中:上下游 StreamNode 的 SlotSharingGroup 需是同一个 且 SlotShargingGroup 在不设置的情况在,它的缺省值是 default; 在 areOperatorsChainable()中:判断上下游 StreamNode 它是否支持 chain 策略; arePartitionerAndExchangeModeChainable() 判断 edge的分区策略; upStreamVertex.getParallelism() == downStreamVertex.getParallelism() 上下游节点的并行度要保持一致; 最后是 StreamGraph 要开启 chaining;
StreamingJobGraphGenerator#isChainable()
1
2
3
4
5
|
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph);
}
|
StreamingJobGraphGenerator#isChainableInput()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& arePartitionerAndExchangeModeChainable(
edge.getPartitioner(), edge.getExchangeMode(), streamGraph.isDynamic())
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled())) {
return false;
}
// check that we do not have a union operation, because unions currently only work
// through the network/byte-channel stack.
// we check that by testing that each "type" (which means input position) is used only once
for (StreamEdge inEdge : downStreamVertex.getInEdges()) {
if (inEdge != edge && inEdge.getTypeNumber() == edge.getTypeNumber()) {
return false;
}
}
return true;
}
|
最后通过for (StreamEdge inEdge : node.getInEdges()) 确保所有输入节点在进入循环之前已经设置了它们的哈希值(调用这个方法)。然后,对于每个输入边,它获取源节点的哈希值,并检查这个哈希值是否存在。如果不存在,它会抛出一个异常。最后,它使用异或和乘法操作来更新当前节点的哈希值。这个过程会对所有的输入边进行迭代,直到计算出最终的哈希值。
1
2
3
4
5
6
7
8
9
10
11
12
|
generateNodeLocalHash(hasher, hashes.size());
// Include chained nodes to hash
for (StreamEdge outEdge : node.getOutEdges()) {
if (isChainable(outEdge, isChainingEnabled, streamGraph)) {
// Use the hash size again, because the nodes are chained to
// this node. This does not add a hash for the chained nodes.
generateNodeLocalHash(hasher, hashes.size());
}
}
|
处理 UserHash
在StreamGraphHasherV2#generateNodeHash()处理逻辑可知节点 hash 值可根据transformationUID生成, 但也存在另一种: 在 StreamGraph还存在 UserHash 设置, 拿StreamWordCount示例进行改造, 针对每个操作符可通过UidHash()方法设置 hash 值。
1
2
|
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1).setParallelism(1).uid("wc-sum").setUidHash("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa");
|
// yzhou TODO 是否存在优先级 ??
设置 Chain链
StreamingJobGraphGenerator#setChaining()方法是设置 Chain链的入口,在buildChainedInputsAndGetHeadInputs()方法会对每个 Source 创建一个 OperatorChainInfo ,它的返回值是一个Map,其结构chainEntryPoints是一个以SourceId为 key,value 是 new OperatorChainInfo(sourceNodeId, hashes, legacyHashes, chainedSources, streamGraph) 的 Map, 取出 chainEntryPoints的 Value 转换成 initialEntryPoints。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
final Map<Integer, OperatorChainInfo> chainEntryPoints =
buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
final Collection<OperatorChainInfo> initialEntryPoints =
chainEntryPoints.entrySet().stream()
.sorted(Comparator.comparing(Map.Entry::getKey))
.map(Map.Entry::getValue)
.collect(Collectors.toList());
// iterate over a copy of the values, because this map gets concurrently modified
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}
|
createChain()
经过上面的铺垫,在没有开始介绍 createChain()方法之前,不知道你是否有一些预期结果, 再例如下面的图应该不会陌生:
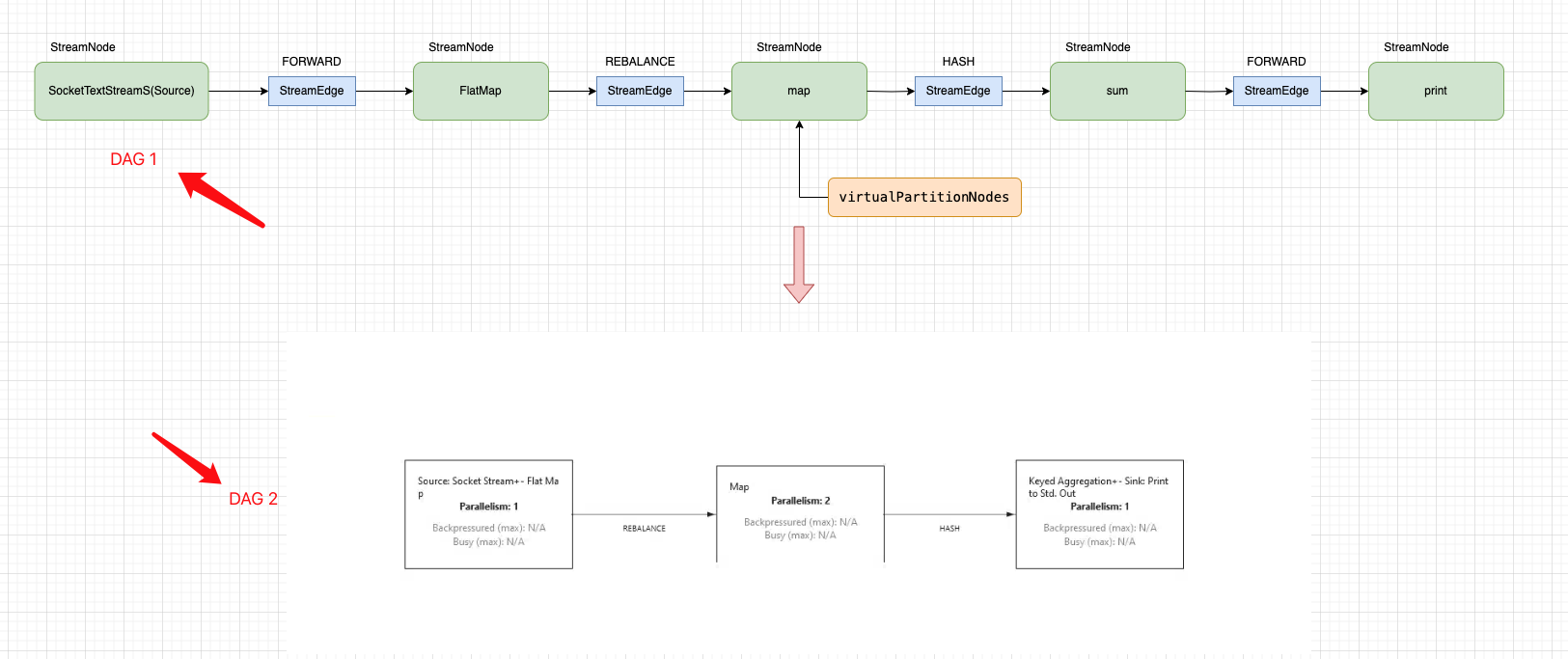 图中 DAG1 是 StreamGraph 中 StreamNode构建的有向无环图,而 DAG2 是 Flink WEB UI 展示的 Job Plan 图,拿 Source 和 FlatMap两个 StreamNode 节点合并示例来看,他们合并在一起, 并且有了新的节点名称还有其他的一些设置。 那有了这样的预期,我们再来了解 createChain() 的处理逻辑。
图中 DAG1 是 StreamGraph 中 StreamNode构建的有向无环图,而 DAG2 是 Flink WEB UI 展示的 Job Plan 图,拿 Source 和 FlatMap两个 StreamNode 节点合并示例来看,他们合并在一起, 并且有了新的节点名称还有其他的一些设置。 那有了这样的预期,我们再来了解 createChain() 的处理逻辑。
调用 createChain()方法传入的形参有: Source节点 Id,chain 下标(下标从 Source 为0 开始,下一个节点是 1), 算子链 Info,起始链头集合 chainEntryPoints。
首先从 chainInfo 获取起始节点 Id,那对于 StreamWordCount 案例来说,获取的是 Source 节点 Id,builtVertices集合用于存放已经构造的 StreamNode ,避免重复构造,那对于 Source 节点来说是第一次。
createChain()方法中存在3个集合容器,transitiveOutEdges存储整个算子链的出边,chainableOutputs存储可以构造 Chain链的 StreamEdge,nonChainableOutputs存储不可以构造 Chain链的 StreamEdge。
遍历 当前节点的 OutEdges(出边),根据 isChainable()方法判断是否可以合并,关于 isChainable()在上面生成节点 hash时,已介绍过,此处不再多做介绍,将可以链接的 StreamEdge 和 不可以链接的 StreamEdge 分别添加到对应的集合容器中,然后再分别遍历两个集合容器并且递归调用 createChain(), 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(
chainable.getTargetId(),
chainIndex + 1,
chainInfo,
chainEntryPoints));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
|
可以链接的chainableOutputs集合中的递归要与不可以链接的nonChainableOutputs集合中的递归结合一起看,因为涉及到 chainInfo、chainEntryPoints 两个变量的改变。
- 可以链接继续递归 StreamEdge的下游节点,并且 链的下标 + 1;
- 不可以链接继续递归 StreamEdge的下游节点,此时重置 chain链的下标为1, 重新开始计数,所以需要重新生成链路信息 chainInfo, 则 StreamEdge 的下游节点作为下次计算 Chain链合并的起点,将新生成的 chainInfo 放入
chainEntryPoints 集合中,所以可以从 chainEntryPoints集中查看 Chain链的多个起始位置。
而递归的终止条件是:当前节点没有 OutEdge(出边) 或者当前节点已经完成转换(builtVertices集合已存在)
createChain() 递归部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
// 从 chainInfo 获取起始节点 Id
Integer startNodeId = chainInfo.getStartNodeId();
// builtVertices 存放已经构建的 StreamNode ID,避免重复构建
if (!builtVertices.contains(startNodeId)) {
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
// chainableOutputs 存放可以构造 Chain链的 StreamEdge
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
// nonChainableOutputs 存放不可以构造 Chain链的 StreamEdge
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
// 当前 StreamNode
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
// 遍历当前 StreamNode 的 OutEdges,根据是否能构造 Chain链,分成存储在2个不同的集合中
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
/**
* 遍历可以构建算子链的 StreamEdge,递归调用 createChain(), 将所有结果全部添加到 transitiveOutEdges
*
*
* 递归终止:
* 当前节点没有 OutEdge
* 当前节点已经完成转换
*/
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(
chainable.getTargetId(),
chainIndex + 1,
chainInfo,
chainEntryPoints));
}
/**
* 遍历不可以构建算子链的 StreamEdge,将其添加到 transitiveOutEdges
* 为什么直接放入 transitiveOutEdges集合中,说明待会要直接创建链接的边
* 此时重新构建chainInfo.newChain(nonChainable.getTargetId()) 相当于
* startNodeId = TargetId
*/
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
省略部分代码 ...
}
|
通过递归终止条件可知,整个图的遍历是以深度优先,所以下面的代码逻辑(下面 createChain() 代码跳过了递归部分)优先处理的是Print Sink;
设置算子链的名称,它是由当前节点 OperatorName 或者 chainEntryPoints中的算子链名称拼接得到;设置算子链的最小资源以及首选资源,仍然与算子链有关;
chainInfo.addNodeToChain()其含义是将当前节点是否处理过 Chain,并添加到StreamingJobGraphGenerator.OperatorChainInfo#chainedNodes集合中,也会将节点hash 放入chainedOperatorHashes Map中,表示同一个算子链中全部的算子连接关系,key 是算子链的起始节点,value 存放链接关系,集合中的子项 f0是当前节点的 hash 值,f1是 legacyHashes,若操作符并未设置UidHash(),则它默认是 null。 OperatorChainInfo 对象代表一次链路信息,那它内部的 chainedNoeds集合属性代表是其内部节点信息。
需特别注意: chainInfo 链路信息,由于存在chainableOutputs和nonChainableOutputs 两个集合的递归遍历,若从深度优先遍历时,当前节点需判断它与链路信息的起始节点是否一致,可判断出它是可以链路的chainableOutputs递归的还是不可以链路nonChainableOutputs递归的,这是因为可以链路的chainableOutputs递归传入的 chainInfo 始终是上游的,只有在不可以链路的情况下,才会创建新的 chainInfo 链路信息。
检查当前节点是否有输入或输出格式,如果存在,则将添加到格式容器中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
省略部分代码 ...
// 把当前节点 id对应的
chainedNames.put(
currentNodeId,
createChainedName(
currentNodeId,
chainableOutputs,
Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
// chain 的最小资源
chainedMinResources.put(
currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
// chain 的首选资源
chainedPreferredResources.put(
currentNodeId,
createChainedPreferredResources(currentNodeId, chainableOutputs));
// 将当前节点添加到链中,并获取该节点的操作符 ID
OperatorID currentOperatorId =
chainInfo.addNodeToChain(
currentNodeId,
streamGraph.getStreamNode(currentNodeId).getOperatorName());
// 检查当前节点是否有输入或输出格式,如果存在,则将添加到格式容器中
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
省略部分代码 ...
}
|
判断当前节点是否是算子链的起始节点,不是则创建新 StreamConfig 对象,设置 chainIndex、OperatorName、设置当前节点的操作符设置(checkpoint,inputConfig,setTypeSerializerOut,时间语义配置)、链式输出配置(例如侧输出流)。 然后更新 currentNodeId 对应的 StreamConfig; 如果当前节点等于起始节点,则调用StreamingJobGraphGenerator#createJobVertex()方法生成 JobVertex,并且会存储在 jobVertices、jobGraph.taskVertices集合中,会将当前节点id 存储在 builtVertices。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
省略部分代码 ...
/**
* 根据当前节点是否是是 Chain链的起始节点,如果是起始节点,则调用 createJobVertex()方法创建它,否则,创建一个新的 StreamConfig 对象
*/
StreamConfig config =
currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
/**
* 尝试转换动态分区,AdaptiveBatchScheduler Flink 根据用户作业执行情况,自动设置并行度
*/
tryConvertPartitionerForDynamicGraph(chainableOutputs, nonChainableOutputs);
// 设置当前节点的操作符配置
setOperatorConfig(currentNodeId, config, chainInfo.getChainedSources());
//
setOperatorChainedOutputsConfig(config, chainableOutputs);
// we cache the non-chainable outputs here, and set the non-chained config later
opNonChainableOutputsCache.put(currentNodeId, nonChainableOutputs);
// 如果当前节点是起始节点
if (currentNodeId.equals(startNodeId)) {
chainInfo.setTransitiveOutEdges(transitiveOutEdges);
chainInfos.put(startNodeId, chainInfo);
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
// 如果不是构建 Map<Integer, StreamConfig> chainedTaskConfigs
chainedConfigs.computeIfAbsent(
startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
// 设置当前 operatorId uuid
config.setOperatorID(currentOperatorId);
// 设置可链接的边 chainEnd 结束标识
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
|
到这里,看似已经完成了setChaining(hashes, legacyHashes)方法的介绍, 可能你会像我一样在阅读源码过程中忽略了一些变量的定义和赋值,在StreamingJobGraphGenerator#setChaining(hashes, legacyHashes)方法没有返回值,在创建算子链的过程中,会统计当前节点的出边不能合并Chain链的个数,并且添加到Map<Integer, List<StreamEdge>> StreamingJobGraphGenerator.opNonChainableOutputsCache中, 避免出现一些遗漏,可参考下图所示处理流程,得到一些集合变量,它们会在后续构建 JobGraph的链路中起到承上启下的作用:
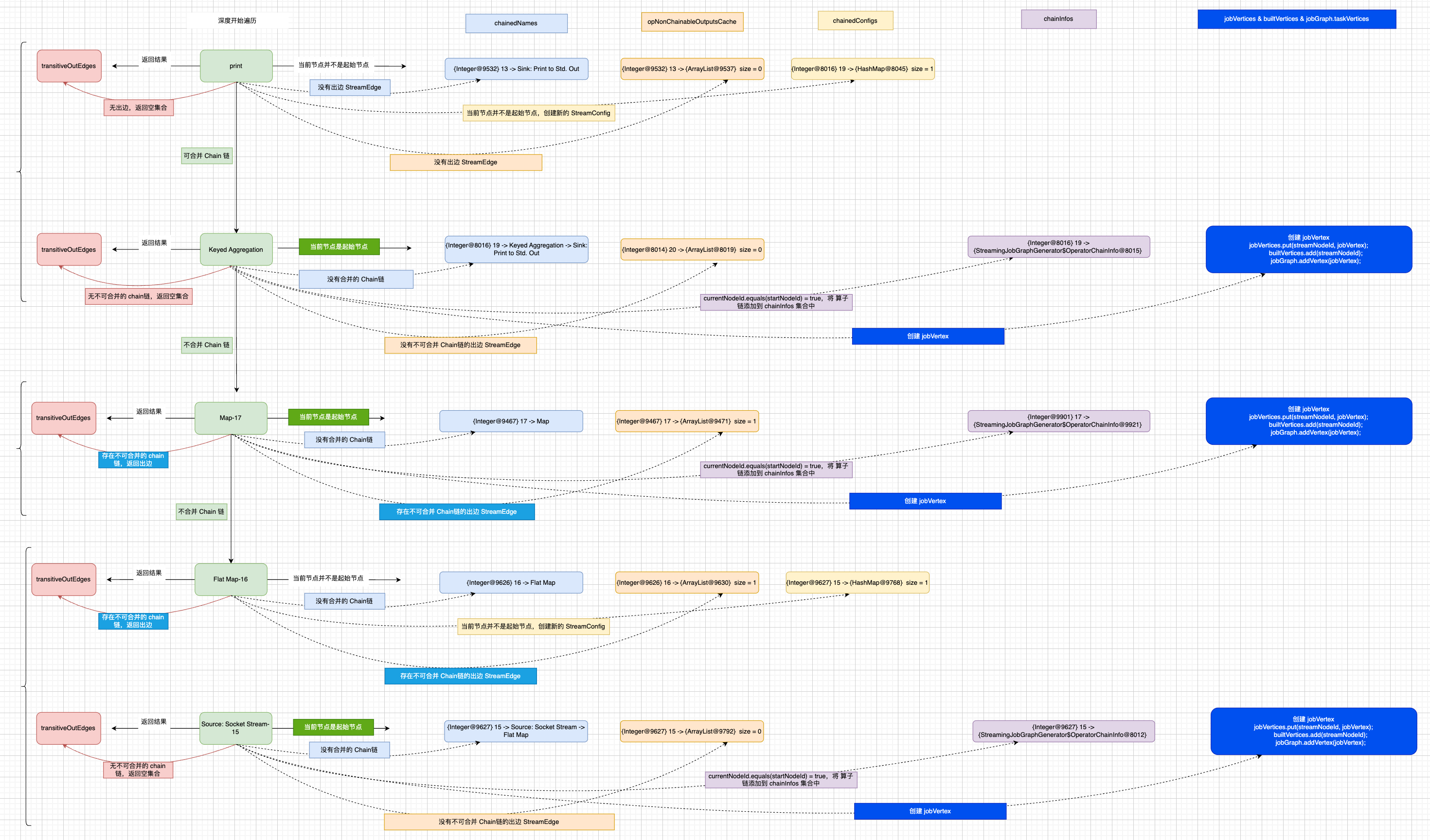
构建新链路
1
2
3
4
|
final Map<Integer, Map<StreamEdge, NonChainedOutput>> opIntermediateOutputs =
new HashMap<>();
setAllOperatorNonChainedOutputsConfigs(opIntermediateOutputs);
setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs);
|
setAllOperatorNonChainedOutputsConfigs(opIntermediateOutputs)
StreamingJobGraphGenerator#setAllOperatorNonChainedOutputsConfigs()方法中遍历了StreamingJobGraphGenerator.opNonChainableOutputsCache集合,它存放的是 StreamNodeId和它下游是不可以合并Chain链的出边信息。
该方法传入了一个空集合final Map<Integer, Map<StreamEdge, NonChainedOutput>> opIntermediateOutputs = new HashMap<>();, 利用computeIfAbsent()方法返回Value的引用,再调用StreamingJobGraphGenerator#setOperatorNonChainedOutputsConfig()方法设置出边的侧输出流、序列化等配置。
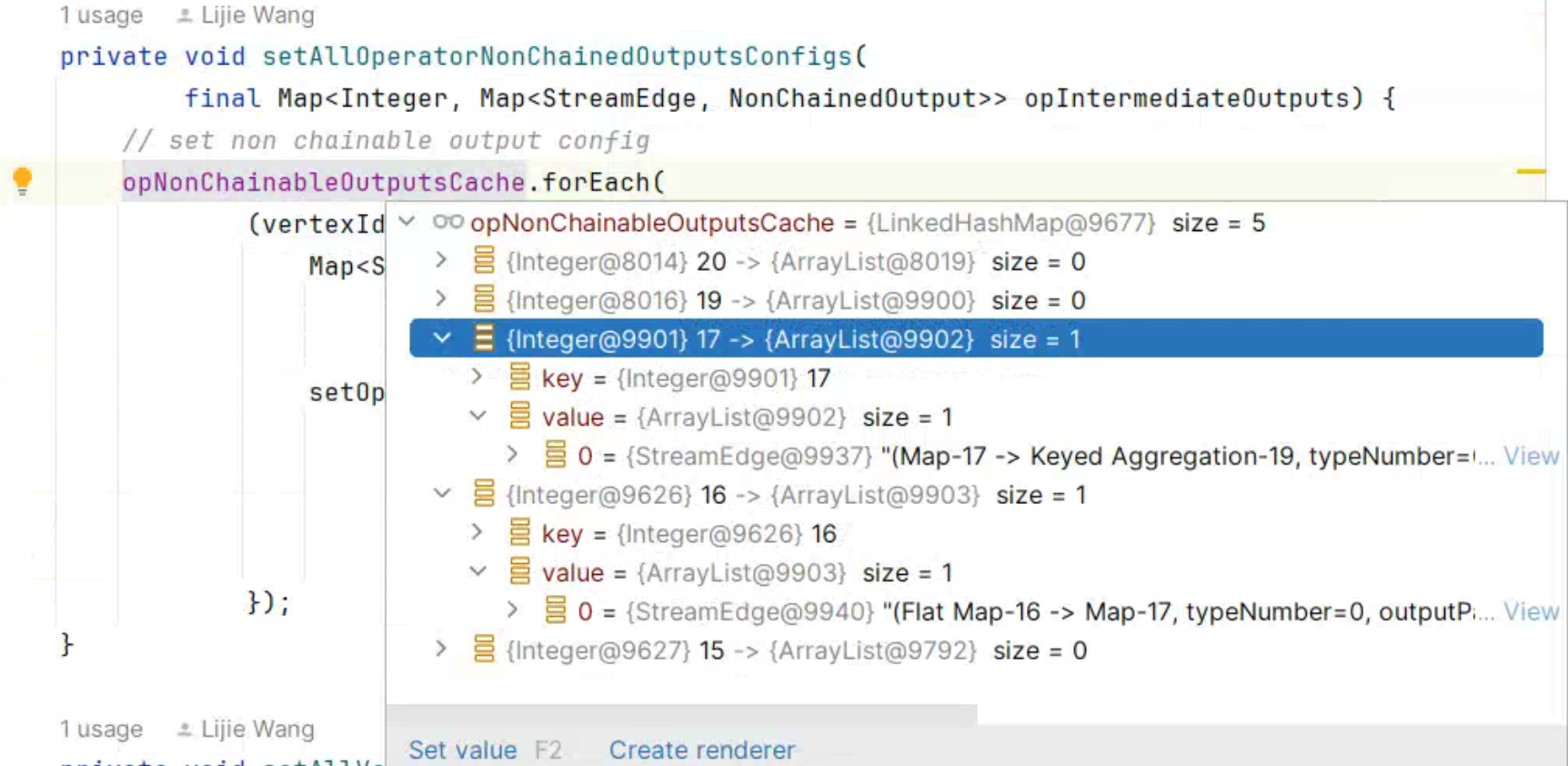
setAllVertexNonChainedOutputsConfigs(opIntermediateOutputs)
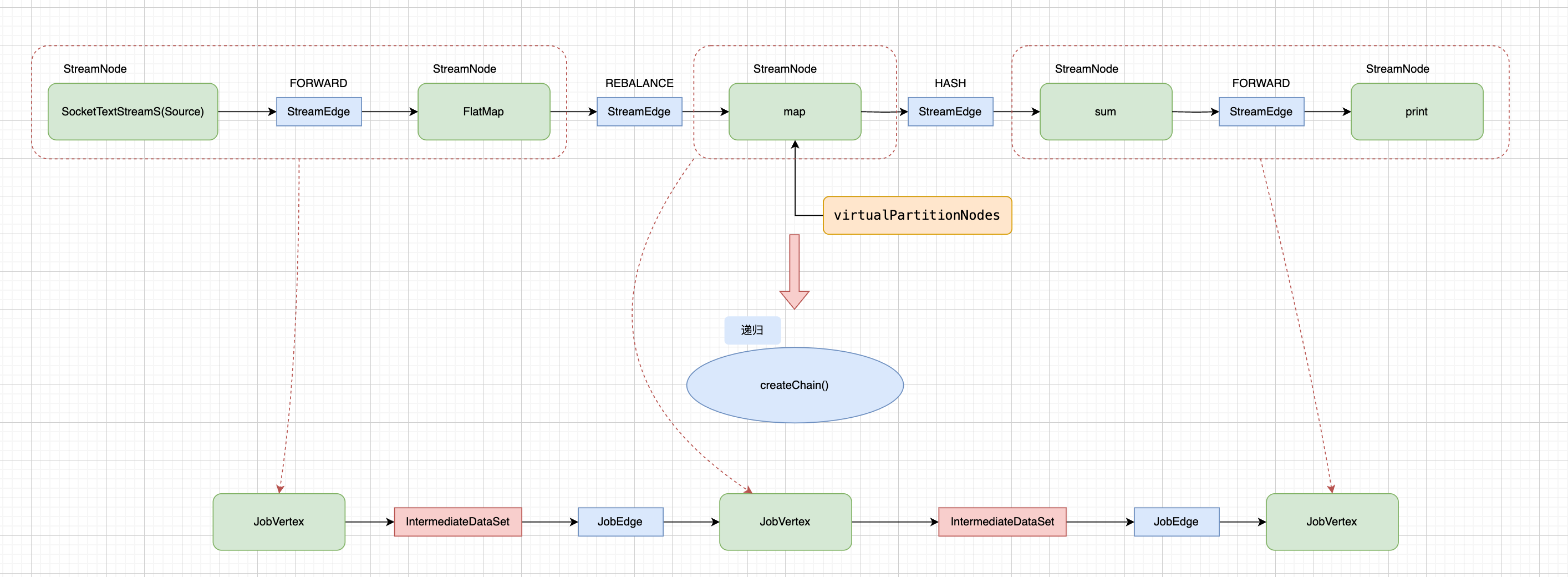
StreamingJobGraphGenerator#setAllVertexNonChainedOutputsConfigs()方法遍历 StreamNode 转换而来的 JobVertex 的 StreamNodeId,它同时也是每个算子链的 StartNodeId,以 StreamWordCount 为例,5个StreamNode,构建了3个 jobVerties, 如下图所示:
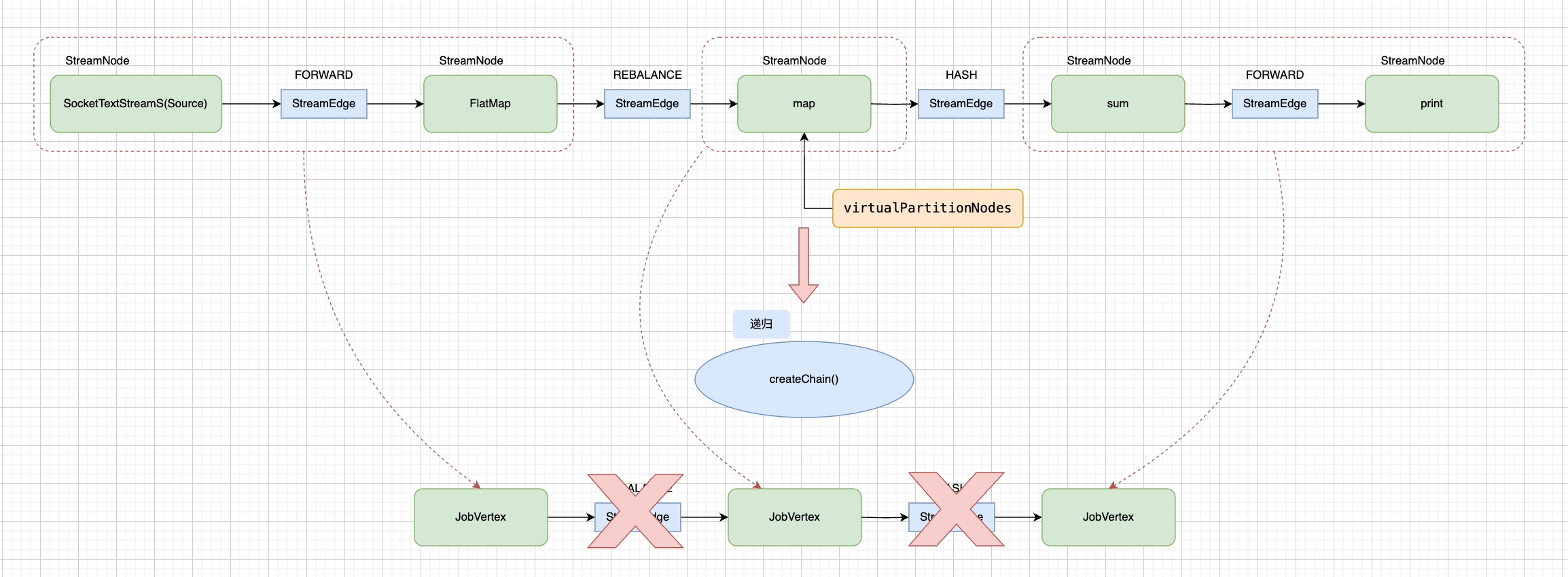
为了避免误导读者,我在上图中将 StreamEdge 标记了差号,因为 JobVertex 中间的边的信息后面会有改变;
遍历算子链,判断当前算子链是否包含不可以合并Chain链的出边, 对于没有出边仅是更新下 config 信息。而对于存在不可以合并Chain链的出边会调用StreamingJobGraphGenerator#connect()方法构建新的边。
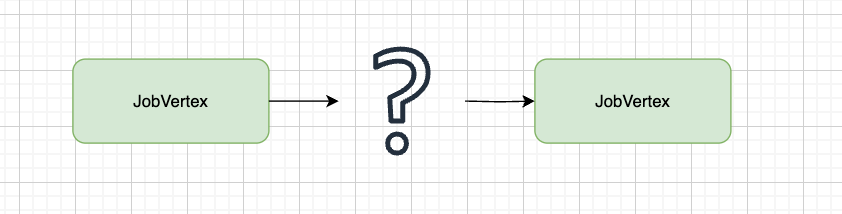
接下来,探索新的边的构造流程;
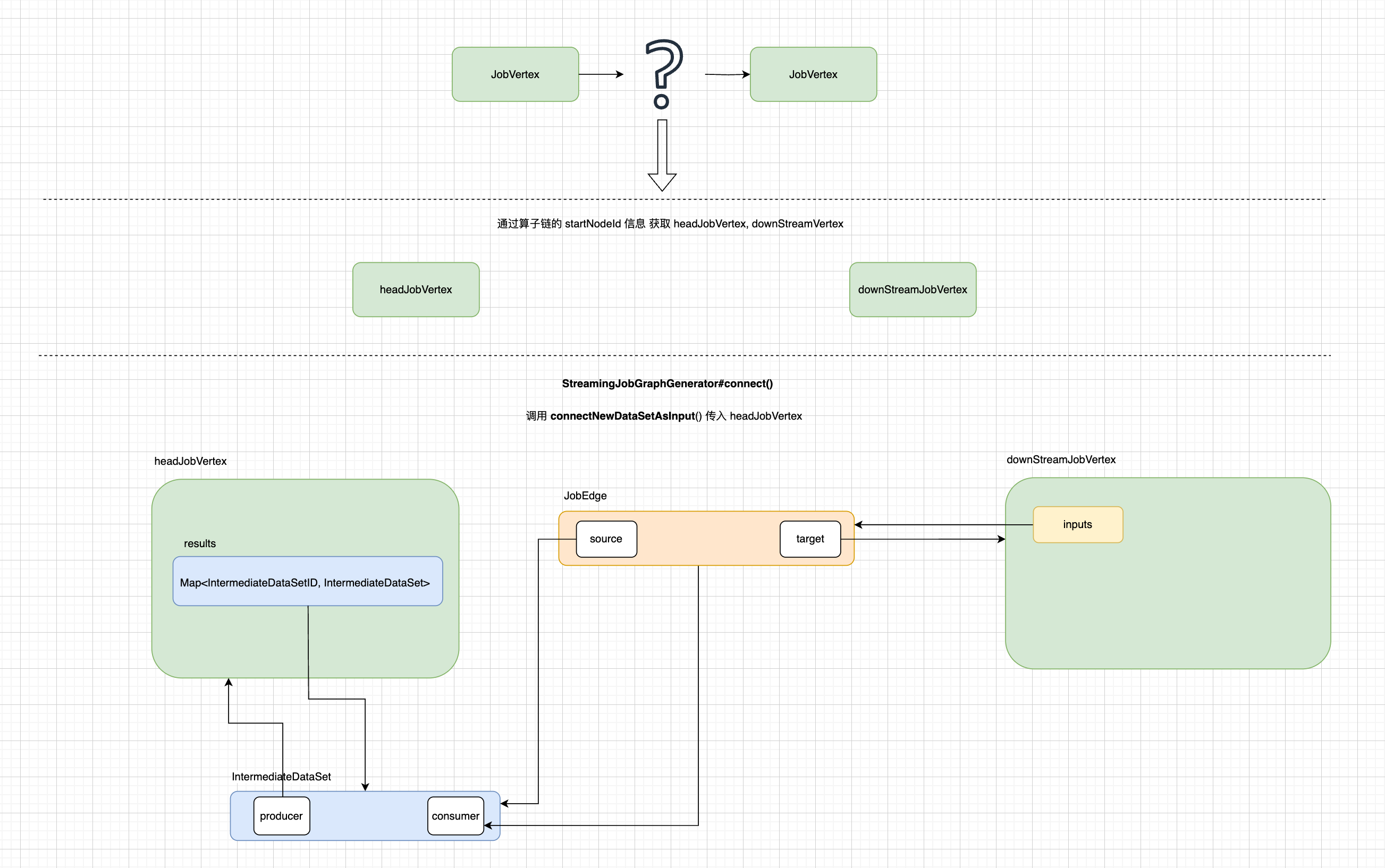
根据 jobvertex 的出边 StreamEdge 获取 head、downStream 的 jobvertex,在根据数据的分发模式创建JobEdge jobEdge, 创建 jobEdge的方法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType,
IntermediateDataSetID intermediateDataSetId,
boolean isBroadcast) {
IntermediateDataSet dataSet =
input.getOrCreateResultDataSet(intermediateDataSetId, partitionType);
JobEdge edge = new JobEdge(dataSet, this, distPattern, isBroadcast);
this.inputs.add(edge);
dataSet.addConsumer(edge);
return edge;
}
|
根据 headJobVertex#getOrCreateResultDataSet()方法会创建IntermediateDataSet对象,在它的构造方法中可了解到,JobEdge 内部target指向的是一个 jobVertex,source指向的是IntermediateDataSet对象。 下面是 JobEdge的构造方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public JobEdge(
IntermediateDataSet source,
JobVertex target,
DistributionPattern distributionPattern,
boolean isBroadcast) {
if (source == null || target == null || distributionPattern == null) {
throw new NullPointerException();
}
this.target = target;
this.distributionPattern = distributionPattern;
this.source = source;
this.isBroadcast = isBroadcast;
}
|
创建完 jobEdge,会将它添加到 JobVertex.inputs属性中,再将 jobEdge添加到IntermediateDataSet.consumers集合中。特别注意,JobEdge是如何关联 JobVertex,应该有了大体的了解,如下图:
所以经过 setAllVertexNonChainedOutputsConfigs()处理,完成了 JobVertex 的关联关系。
JobGraph 的其他配置
对于JobGraph的 图的构造上面已经完成,下面会涉及到一些 JobGraph 实例的其他设置,比如节点的槽位共享组信息设置、资源设置、用户自定义文件设置等。
setPhysicalEdges()将每个 JobVertex 的入边集合也序列化到该 JobVertex 的 StreamConfig 中, setSlotSharingAndCoLocation()为每个 JobVertex 指定所属的 SlotSharingGroup 以及设置 CoLocationGroup;
后面的一些参数配置,等到它的具体的使用时,介绍会更深刻。此时不能算是该篇的核心。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
private JobGraph createJobGraph() {
// 省略部分代码 ...
// 设置物理边(Physical Edges)。物理边通常指的是在任务之间实际传输数据的边。
setPhysicalEdges();
// 标记哪些任务支持并发执行尝试。在某些情况下,Flink 允许任务尝试并发执行,以提高容错性和性能。
markSupportingConcurrentExecutionAttempts();
// 验证shuffle是否在批处理模式下执行。
validateHybridShuffleExecuteInBatchMode();
// 设置槽(Slot)共享和协同定位(Co-location)
setSlotSharingAndCoLocation();
// 设置管理的内存比例。这是为了分配和管理 Flink 任务的内存资源
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
// 配置检查点(Checkpointing)。检查点是 Flink 的容错机制,用于在任务失败时恢复状态。
configureCheckpointing();
// 设置 JobGraph 的保存点(Savepoint)恢复设置
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
// 准备用户定义的资源(如文件或对象)
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
// 将用户定义的资源添加到 JobGraph 中,比如 cache
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
// 设置 JobGraph 的执行配置(ExecutionConfig)。这个配置包含了任务执行时的各种参数和设置。
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
// 设置 JobGraph 的作业配置(JobConfiguration)。这通常包含了作业的元数据和其他设置。
jobGraph.setChangelogStateBackendEnabled(streamGraph.isChangelogStateBackendEnabled());
// 在顶点的名称中添加顶点索引的前缀。这可能是为了更清晰地标识图中的每个顶点。
addVertexIndexPrefixInVertexName();
// 设置顶点的描述。这通常用于记录或显示顶点的信息,帮助用户或开发者更好地理解图中的每个顶点。
setVertexDescription();
/**
* vertexConfigs.values().stream():从 vertexConfigs 的值中创建一个流。
* map:将每个配置对象(config)映射为通过 triggerSerializationAndReturnFuture 方法触发的序列化操作,并返回一个 Future 对象。这个 Future 对象代表了一个异步操作的结果。
* collect(Collectors.toList()):将所有 Future 对象收集到一个列表中。
* FutureUtils.combineAll(...):等待所有 Future 对象完成。这通常意味着等待所有配置对象的序列化操作完成。
* .get():阻塞当前线程,直到所有 Future 对象都完成,并获取结果。如果在这个过程中有任何异常发生,它将在此处被抛出。
*/
// Wait for the serialization of operator coordinators and stream config.
try {
FutureUtils.combineAll(
vertexConfigs.values().stream()
.map(
config ->
config.triggerSerializationAndReturnFuture(
serializationExecutor))
.collect(Collectors.toList()))
.get();
/**
* 等待序列化完成并更新作业顶点.
* 用于确保所有序列化的 Future 对象都已经完成,并更新 JobGraph 中的相关顶点。
* 这可能是因为在序列化过程中可能修改了顶点的某些属性或状态,需要更新到 JobGraph 中
*/
waitForSerializationFuturesAndUpdateJobVertices();
} catch (Exception e) {
throw new FlinkRuntimeException("Error in serialization.", e);
}
/**
* 检查 streamGraph 是否有作业状态钩子(JobStatusHooks)。作业状态钩子通常用于在作业生命周期的不同阶段执行自定义逻辑,如作业提交、恢复等。
* 如果有,将 streamGraph 中的作业状态钩子设置到 jobGraph 中,以确保这些钩子在 jobGraph 执行时也会被触发。
*/
if (!streamGraph.getJobStatusHooks().isEmpty()) {
jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
}
return jobGraph;
}
|
总结
从 StreamGraph 到 JobGraph 分析完后,感觉自己离真想又更近一步。