转载:http://xinzhuxiansheng.com/articleDetail/
引言
在 Flink SQL 领域中 CLI 是非常重要的工具吗,下面是 Flink SQL Job 开发流程来介绍下,如下图所示:
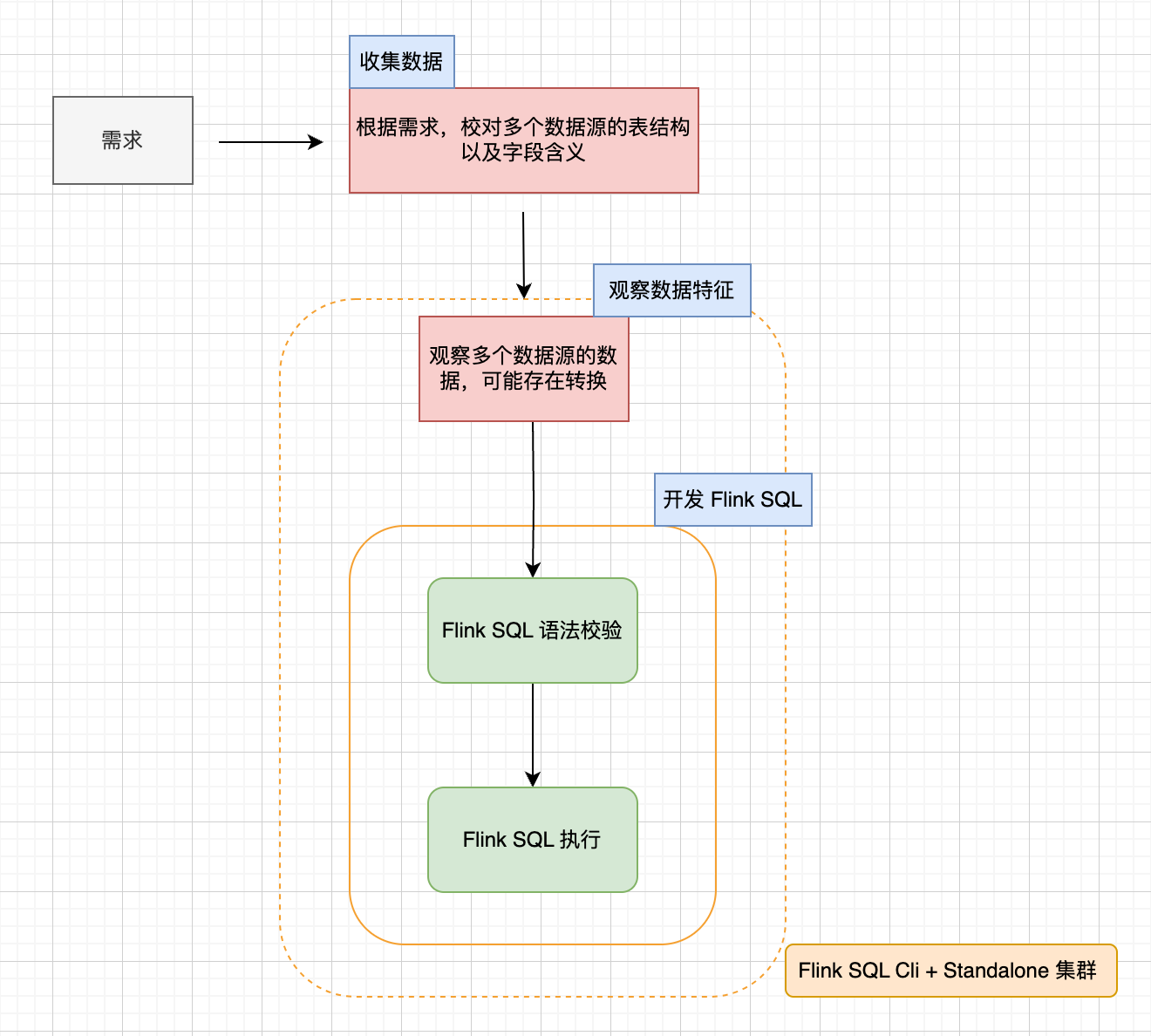 有一个实时需求,目前看可以使用 Flink SQL 实现,首先会根据需求,收集数据,校对多个数据源的表结构以及字段含义,可能这个过程会存在数据并未结构化存储,还需实现数据采集等操作。 有了数据源,会观察数据源的数据,是否需要根据需求对数据进行一些转换操作,最后开发 Flink SQL 实现实时需求。
有一个实时需求,目前看可以使用 Flink SQL 实现,首先会根据需求,收集数据,校对多个数据源的表结构以及字段含义,可能这个过程会存在数据并未结构化存储,还需实现数据采集等操作。 有了数据源,会观察数据源的数据,是否需要根据需求对数据进行一些转换操作,最后开发 Flink SQL 实现实时需求。
Flink SQL Cli 在开发流程中提供了 Flink SQL 语法校验 和 验证 Flink SQL 执行,甚至在“观察数据源的数据”环节都可能使用 Flink SQL Cli。
在 Flink 生态中,Flink on Yarn,Flink on Kubernetes 都能提供 SQL 语法校验、验证 Flink SQL 执行是否正确 功能, 那为什么选择 Flink SQL Cli 呢?
是因为 Flink SQL Cli 可减少开发时间成本,主要从以下几点体现出来:
- 1.Flink SQL Job 提交到 Flink Standalone 集群 耗时较少,所以,频繁修改、验证 Flink SQL 的正确,涉及到多次提交 Job,那积累起来的节约时间优势与其他部署方式相比就特别明显。
- 2.查看 log 简单,Flink on Yarn,Flink on Kubernetes 太依赖于外部组件,而 Flink Standalone 集群的 log 查看起来就简单的多,直接使用 less 命令查看即可。
- 3.SQL 任意组合执行,改动成本低。
关于 Flink SQL CLI 可访问
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sqlclient/
接下来,我们通过一些 Flink SQL Cli 的使用案例来了解它。
启动 sql-client

案例分析
使用以下 Flink CREATE TABLE SQL,创建 Table
|
|
注意一行一行输入。 查看 table
|
|
执行 SELECT * 预览数据,注意,因为数据源是 JDBC,属于有界数据源,需执行SET 'execution.runtime-mode' = 'batch';(在 Flink SQL Cli 默认以 stream 方式处理数据源),以下是完整数据结果:
|
|
注意这里需要导入 flink-connector-jdbc-3.1.2-1.17.jar 导入 lib 包下,还需要 mysql 的驱动包。

测试 UDF
在 Flink SQL 中大多数时候会使用一些System(Built-in) Functions,也存在 Flink 提供的系统函数无法支持的一些数据处理,所以需要开发User-defined Functions, 那开发的 UDF 也是可以在 Flink SQL Cli 验证它的正确性,接下来,演示在 Flink SQL Cli 调用 UDF。
系统内置函数可参考
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/systemfunctions/
关于 UDF 可参考https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/udfs/、
案例背景介绍
现在有一个 Kafka 的数据源,存放格式为:{"id":1,"name":"yzhou","addressId":1}的数据, 还有一个 MySQL 数据源,它是用来存放地址信息,它的字段 id,name,需要使用 Flink SQL 实现 Kafka Join MySQL, 利用 UDF 将 Kafka 中的 name 与 MySQL 中的 name 拼接成 一个新字段 info;如下图所示:
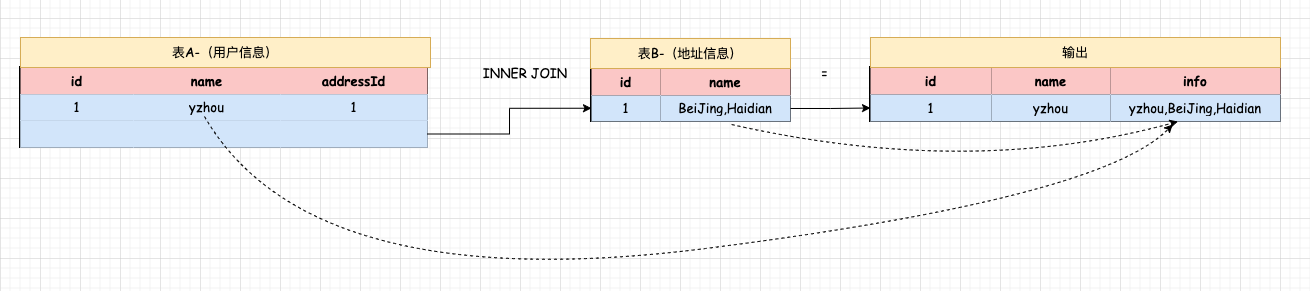
注意,上述需求并非不能用系统函数实现,只是通过简化需求来测试 UDF。
建表语句
Kafka Source
|
|
注意:若使用
SELECT * FROM Kafka_Source;查看 kafka Topic 数据,在 Flink Version 1.17.2 版本中,Job 需触发 Checkpoint 后,终端才会展示 Topic 数据。
MySQL Source
|
|
myql 的建表语句
|
|
开发 UDF
- 添加 pom.xml
|
|
- 开发 UDF 方法
|
|
在 SQL CLI 测试 UDF
- 将 UDF jar 添加到 lib/ 下,重启 Standalone 集群
- 执行 Kafka,MySQL 的 Flink Create Table SQL
- 创建临时函数,
Concatenate2Fields是定义函数名称,com.yzhou.udf.scalarfunction.Concatenate2Fields指向类的完全限定名。
|
|
- 准备数据
将 user_address 维表插入:1,Beijing,Haidian 数据 - 执行 SQL
|
|
- 使用 shell 发送数据到 yzhoujsontp01 topic
|
|
注意:查看执行 SQL 的结果,在 Flink Version 1.17.2 版本中,Job 需触发 Checkpoint 后,终端才会展示 Topic 数据。
Output log:
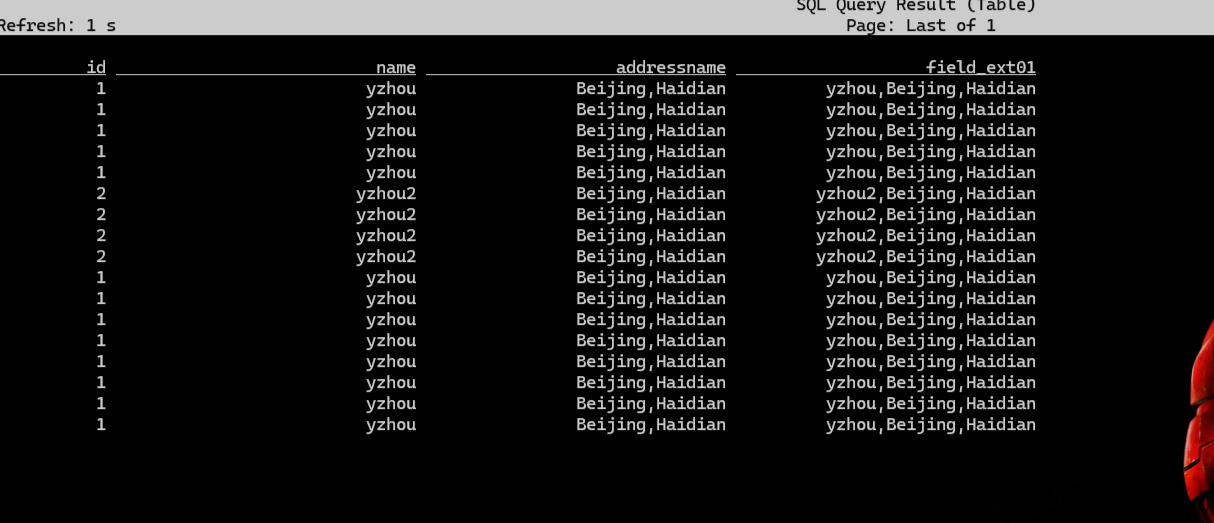 测试 UDF 功能,测试完成。
测试 UDF 功能,测试完成。
小结
在 Flink SQL Cli 查询数据源数据或者查看 Flink SQL 执行结果,会存在一些前置条件,还需多注意。 例如,设置 batch 处理模式,触发 Checkpoint。
4.查看 Flink SQL Job Plan
在之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph"介绍过 Flink Jar Job 的 Plan 查看,它对于 Job 的执行优化提供了专业性的指标参考。同样, Flink SQL Job 可利用 Flink SQL Cli 工具查看 Job 的 Plan。
接下来,使用下面的 SQL 案例来演示 Plan。
使用 EXPLAIN PLAN FOR 关键字
|
|
Output log:
|
|
refer
1.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sqlclient/
2.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/systemfunctions/
3.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/udfs/
4.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sql/overview/