转载:http://xinzhuxiansheng.com/articleDetail/
引言
在 Flink 中,每个函数和算子都可以是有状态的,而有状态的函数和算子是将 Data 存储在 State 中,所以 State 提供了 Flink 中用于存储计算过程中数据的存储介质。 在 Flink 这种分布式系统中,必然存在 Fallacies of distributed computing (https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing) , So Flink 提供了一种叫做 检查点分布式快照机制(Checkpoint),用于保证有状态流处理的容错性,它会定期捕获和保存有状态的快照, 若 Job 发生故障后,Checkpoint 允许 Job 在发生故障时恢复到最近的检查点,从而恢复 Job 的状态和处理位置,这样可以确保数据处理的连续性和一致性。
State 是 Checkpoint 保护的对象,在 每次执行 Checkpoint 时,Flink 会将当前所有状态的快照保存下来。
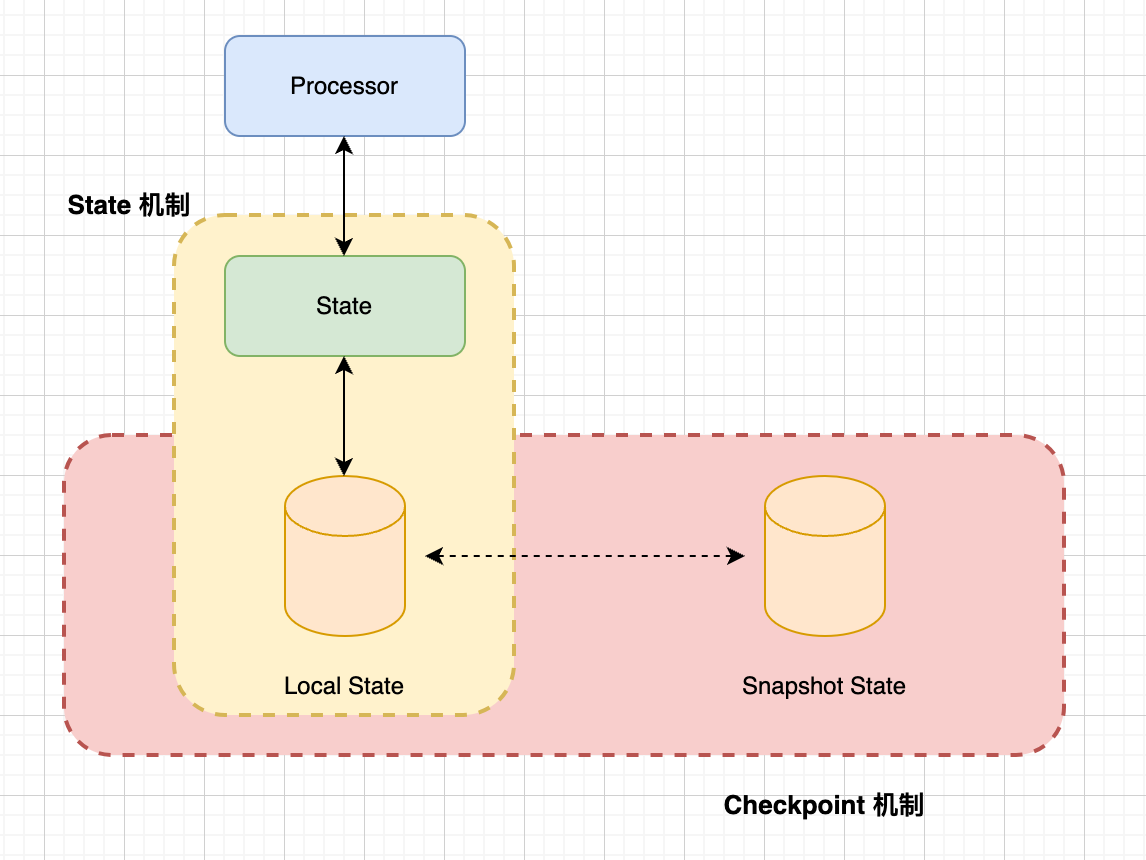
关于更多的 State & Checkpoint 可访问官网文档。
State 官网文档介绍,可访问https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/concepts/stateful-stream-processing/
Checkpoint 官网文档介绍,可访问https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/checkpointing/
接下来,开始介绍基于 Standalone 的 State & Checkpoint 使用
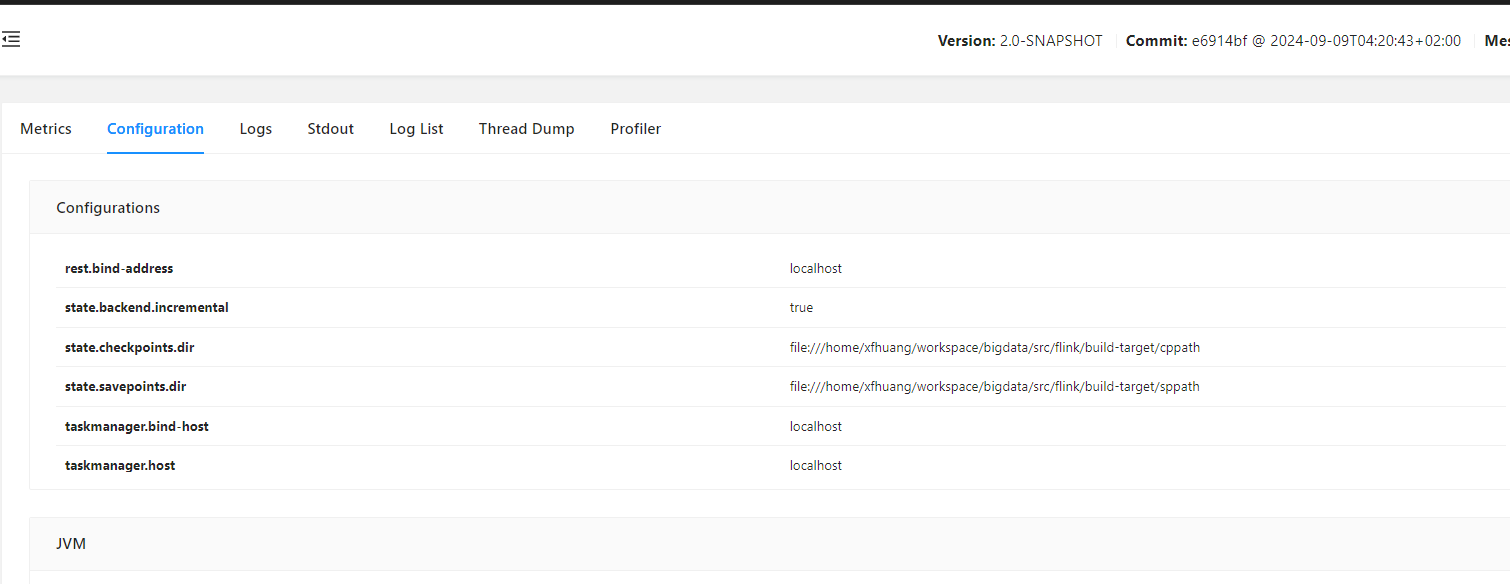
配置 Checkpoint Config
vim conf/flink-conf.yaml
|
|
配置重启 Standalone 集群后,可以在 Flink WEB UI 中看到 checkpoint 配置:
StreamWordCount 示例代码
下面的代码是 在之前 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph” 中的 StreamWordCount示例,接下来,我们仍然会使用该示例来测试, 但有一次修改,给.sum() 算子设置了 uid 为wc-sum,在下面的内容会讲解读取 State 的数据的时候会用 uid 来标识某个算子,可查看 StreamGraph transform JobGraph 过程中的StreamGraphHasherV2#generateNodeHash()方法,算子的 hash 值的计算存在一个 if 判断,若当前算子存在 uid 也就是 TransformationUID ,则根据它来进行 hash,所以,理解这点非常重要,通过提前设置 uid,在后续查找算子时,就很容易定位到具体算子。后续会分享 StreamGraph transform JobGraph 的过程。
com.yzhou.blog.wordcount.StreamWordCount
|
|
- 终端执行
nc -lk 7777 - 通过 Flink WEB UI 提交 StreamWordCount Job
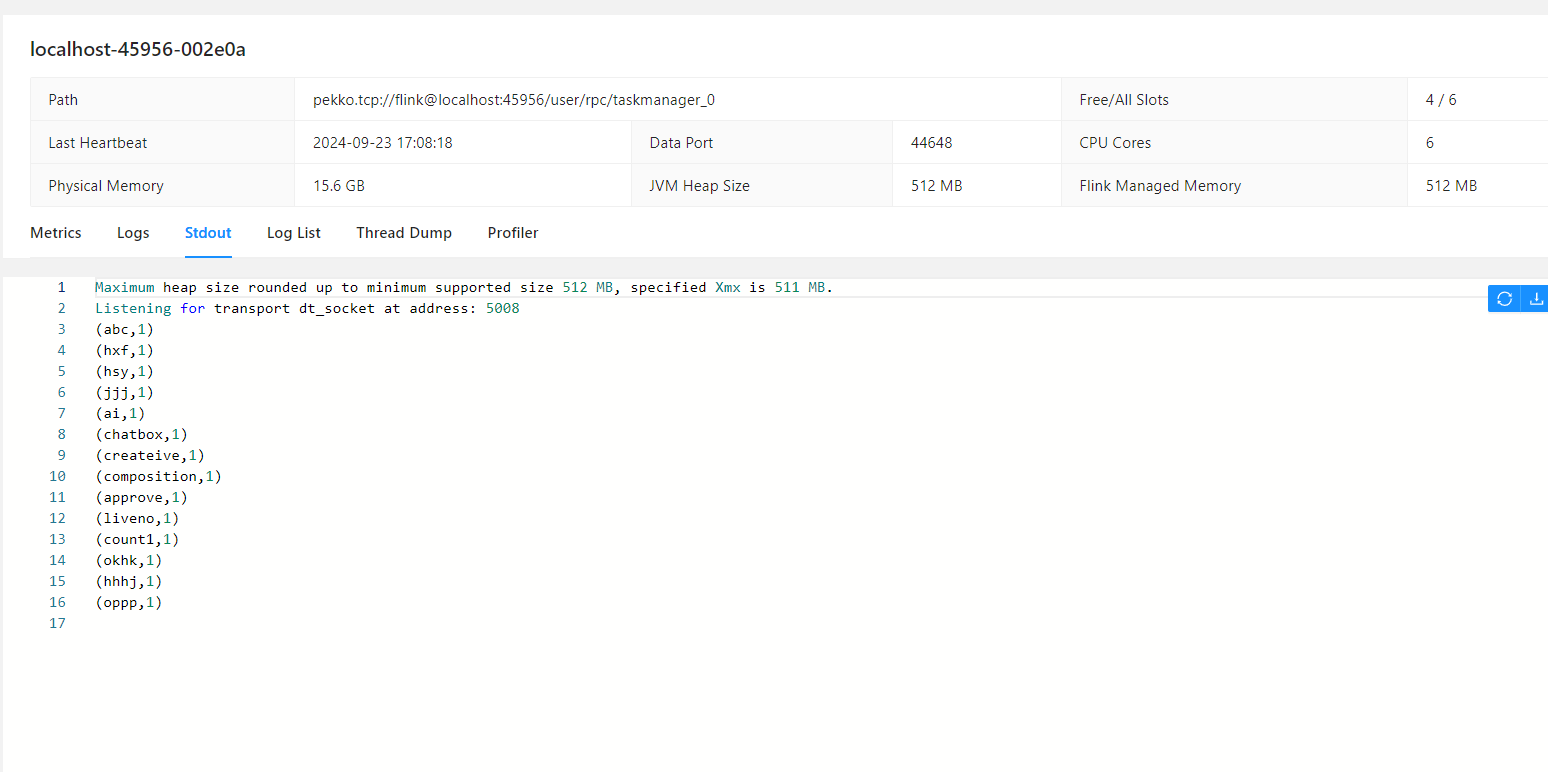
- 输入测试数据,最后 word count 的统计结果可在 Task Managers Stdout Log 页面查看,如下图所示:
触发 Checkpoint
通过 Flink WEB UI 页面,查看 Job 的 Checkpoint History,发现每隔 60s 触发一次 Checkpoint,可能你会有以下疑问:
1.StreamWordCount#main() 没有调用Checkpoint相关 API,那 Checkpoint 又是如何生效?
2.StreamWordCount#main() 没有调用State相关 API,那每隔 60s 触发一次 Checkpoint 存储的是什么呢?
针对第一个疑问:bin/flink-conf.yaml的配置是全局性,是因为StreamWordCount#main() 在创建 StreamExecutionEnvironment 对象时, 会调用 StreamExecutionEnvironment#configure()来关联 Checkpoint 的相关参数, 下面是相关代码块:
创建 StreamExecutionEnvironment
|
|
设置 Checkpoint 配置
|
|
调试 tip:
调试源码过程中,存在源码不知道在哪触发? 例如StreamWordCount#main()并没有Checkpoint相关配置,但通过 Flink WEB UI 查看作业情况,Checkpoint 是生效的, 所以,在源码中搜索execution.checkpointing.interval, 然后在获取此参数配置的get方法打断点,再根据 Idea 查看, 例如图片中的示例:
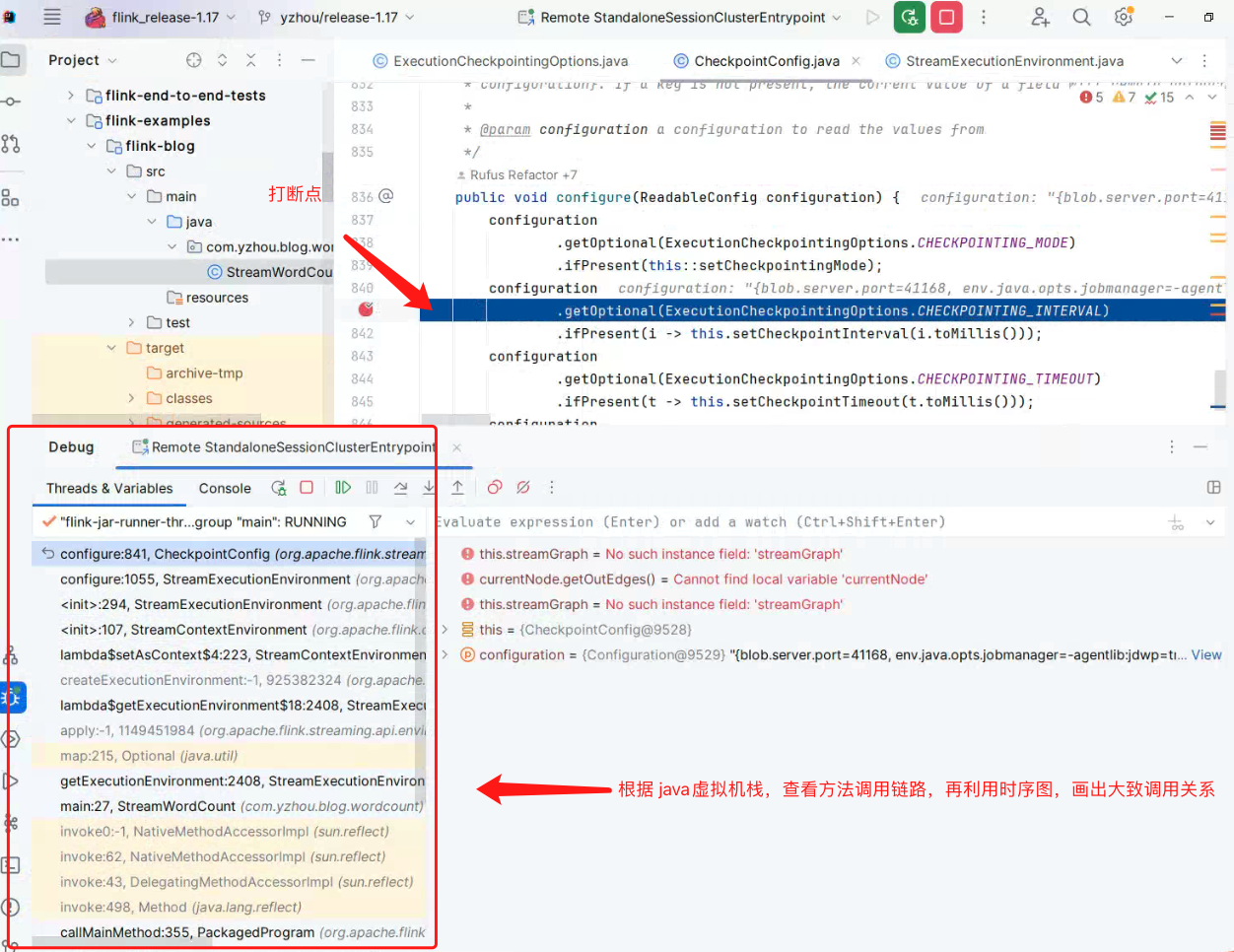 根据
根据CheckpointConfig#configure()方法,由此可知 StreamWordCount Job 启动时,Flink 会默认给它配置的一些参数以及缺省值,config 代码如下:
CheckpointConfig#configure()
|
|
通过CheckpointConfig#configure()可以总结出配置的具体参数项以及它的默认值,内容如下:
|
|
了解配置参数对于了解 Checkpoint 的机制是个很不错的入口,同样对于 Checkpoint 调优非常重要(可以不配置,走缺省值,但不能不知道该配置)。
到这里,第一个疑问应该解释的差不多了,可了解StreamWordCount#main()若设置 Checkpoint 配置参数,那它的优先级是高于 bin/flink-conf.yaml。
接下来,一起探索第二个疑问。
从 检查点(Checkpoint)恢复 StreamWordCount Job
了解 Checkpoint 目录结构
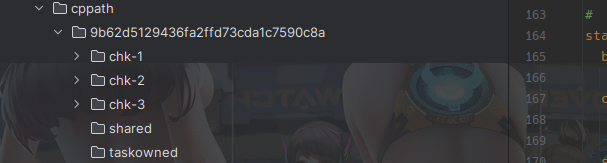
了解 Checkpoint 目录结构,查看state.checkpoints.dir: file:///root/yzhou/flink/flink1172/cppath 目录下, 很容易看到 /root/yzhou/flink/flink1172/cppath/{jobid} 这样的目录结构。结构如下:
|
|
缓一下,若没有阅读过官网对 Checkpoint Path 介绍,可访问
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/ops/state/checkpoints/
So chk-4 命令是 chk-{checkpointId} 模板定义的,且 checkpointId 是递增的,每次触发 Checkpoint 时,checkpointId + 1,然后创建新目录。所以这里引出第三个疑问:
3.在 Flink WEB UI 查看 Job Checkpoint History,存在多个 Checkpoint,可 Checkpoint Path 只存在 chk-4, 并没有 chk-3, chk-2 …., 这又是为啥呢? 如下图所示:
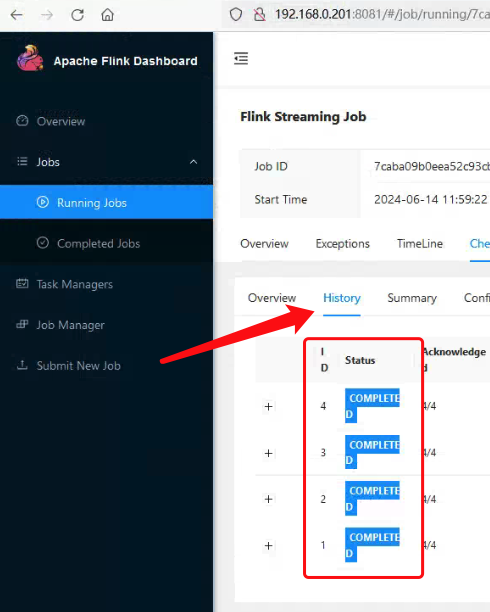 在之前
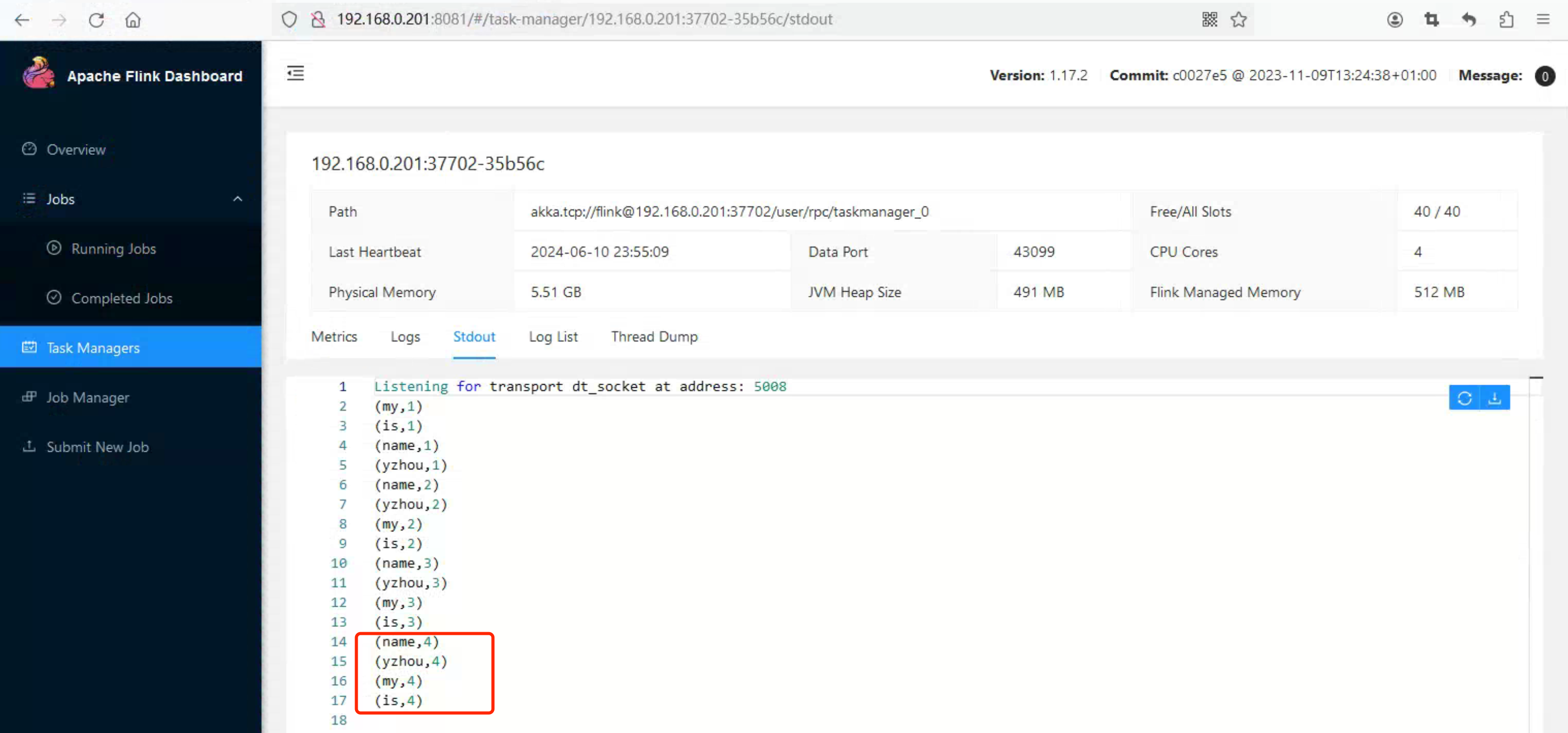
在之前 引言章节介绍 Flink 可以从之前的检查点(Checkpoint)恢复 Job 状态以及存储的数据,那预期的结果是 Checkpoint 会存储 StreamWordCount 的统计结果。
假设,StreamWordCount 在 12:00 之前处理了 4 条my name is yzhou, 那统计结果是(查看 Flink WEB UI 的 Task Manager 的 Stdout Log ):
|
|
 在 12:00 自动触发 Checkpoint,12:00 之后,并无新数据发送,我在 12:01 通过 Flink WEB UI 触发 Cancel Job,此时再观察 Checkpoint Path,
在 12:00 自动触发 Checkpoint,12:00 之后,并无新数据发送,我在 12:01 通过 Flink WEB UI 触发 Cancel Job,此时再观察 Checkpoint Path,chk-4 目录竟然没了, What !!!
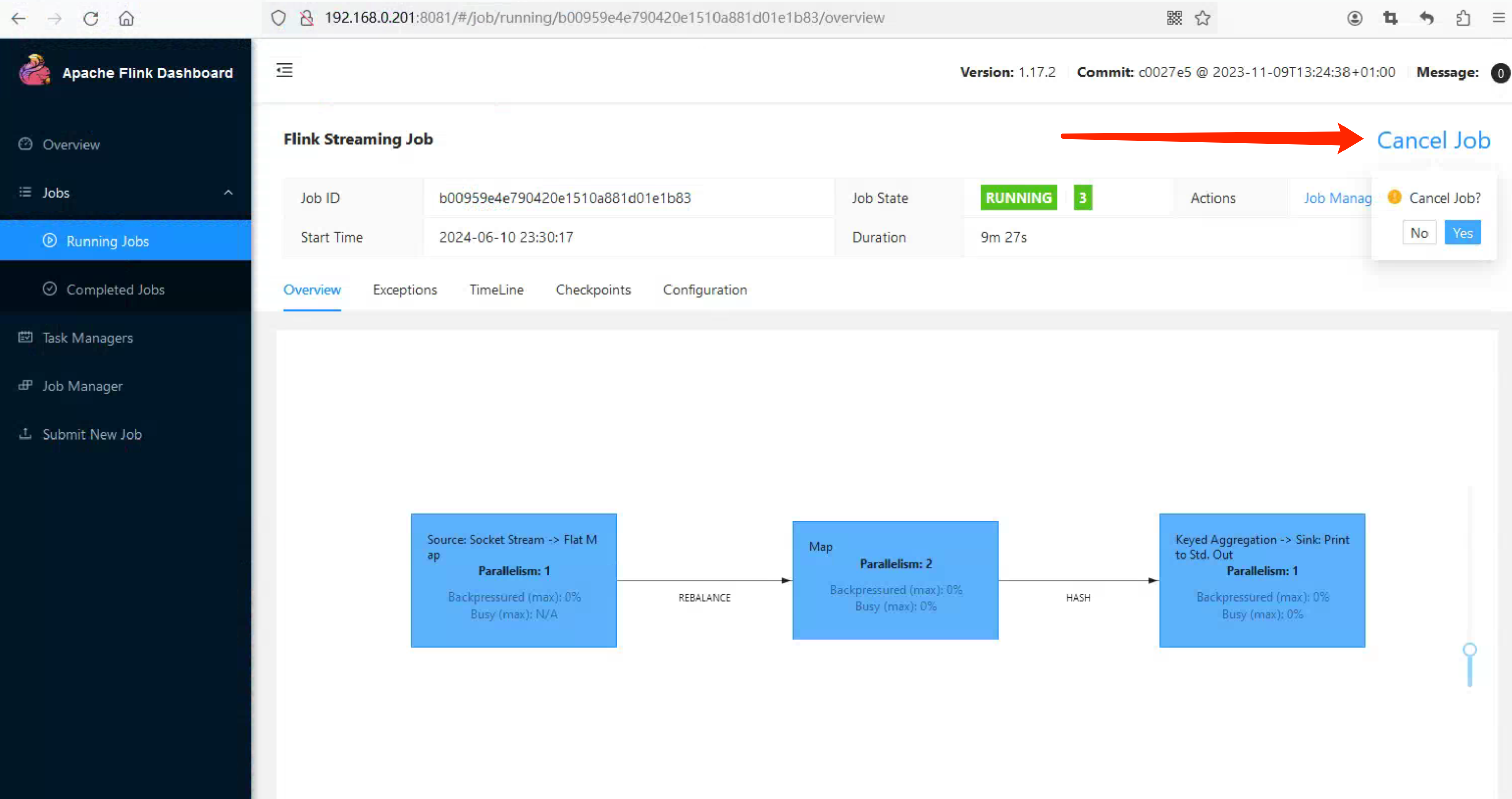 所以这里引出第四个疑问:
所以这里引出第四个疑问:
4.Cancel Job后,chk-4 目录没了,可其他目录,shared、taskowned 是空目录,那拿什么来恢复我的 StreamWordCount Job。
注意:chk-4 仅代表 Job 最新的一次 checkpoint,并不是专属,所以,你可能是 chk-5,chk-1,So 无需对比。
接下来,先解决第三个和第四个疑问;
添加 Checkout 保留策略和个数配置
针对第三个疑问和第四个疑问,是 Flink Checkpoint 的缺省值配置造成的,在实际使用过程中,下面参数大多数都需提前定义好,避免无法从 Checkpoint 恢复 Job。
配置 execution.checkpointing.externalized-checkpoint-retention 参数
将 execution.checkpointing.externalized-checkpoint-retention 参数修改为 RETAIN_ON_CANCELLATION, 它的默认值是NO_EXTERNALIZED_CHECKPOINTS。 其目的是为了解决在 Flink WEB UI 触发 Cancel Job的时候,默认情况下不保留 Checkpoint 的目录。 参数解释如下:
|
|
配置 state.checkpoints.num-retained 参数
将 state.checkpoints.num-retained 参数修改大一些,例如 100,它的默认值是 1。 在触发 Checkpoint 后,Flink 会检查 Job 的 Checkpoint 保留个数,若是默认值 1,则只会保留最新的 Checkpoint, 这显然无法满足测试和生产的使用情况,保留多个检查点可以增加恢复作业时的灵活性,可以选择从多个历史检查点中进行恢复。但同时也会占用更多的存储空间。
关于 Checkpoint 参数的默认值,可查看源码中
CheckpointingOptions.java。也可访问文档https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/config/#checkpointing
修改完,记得重启 Standalone 集群。
重新提交 StreamWordCount Job,过一段时间后,查看 Checkpoint Path,会存在多个 chk-{checkpointid} 目录。
|
|
到目前为止,在 conf/flink-conf.yaml 新增的配置为:
|
|
那么 疑问 3 和疑问 4 已解决了。接下来,回到疑问 2。
从 Checkpoint 恢复 StreamWordCount Job
从 Checkpoint(chk-4) 恢复 StreamWordCount Job, 在 Submit New Job 添加 Savepoint path 参数为 /root/yzhou/flink/flink1172/cppath/b00959e4e790420e1510a881d01e1b83/chk-4, 该 path 指向的是某个 chk-checkpointid 的具体路径。
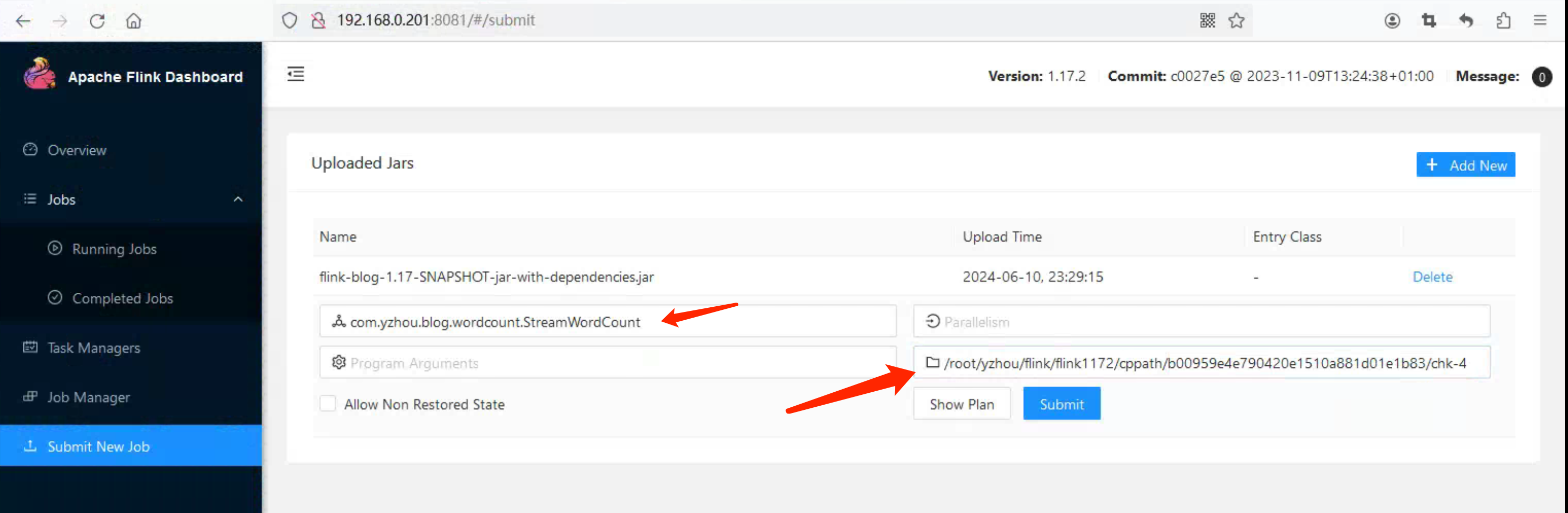
注意,该操作与 下面的 CLI 操作是等同的,内容如下:
|
|
Job 启动成功后,执行 nc -lk 7777 发送 my name is yzhou, 结果如下:
|
|
这显然符合 Checkpoint 的预期。
我想这里,可以根据现象得到一个结论,chk-4/_metadata 是存放了统计结果,可能你会想 StreamWordCount Job 是运行在 Standalone 集群,Job 多次执行 Start,Cancel,而 Standalone 集群一直是可用的,那会不会存在 统计结果也在 Standalone 内存中存储一份?其实,你可以重启 Flink Standalone 集群再做一次从 Checkpoint 恢复 StreamWordCount Job,同样能得到上面的结果。
为了防止疑问 2 的内容太久脱离上下文,这里我也贴一份:
2.
StreamWordCount#main()没有调用State相关 API,那每隔 60s 触发一次 Checkpoint 存储的是什么呢?
读取 chk-/_metadata 的 State 数据
从 Checkpoint 恢复 StreamWordCount Job章节可知,StreamWordCount Job 的统计结果确实恢复了,现在直接读取 chk-{checkpointid}/_metadata 打印出 StreamWordCount 的统计结果。
在还没开始之前,推荐大家了解下 State Processor API(https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/libs/state_processor_api/), Flink 给我们提供了 flink-state-processor-api jar 来读取 Checkpoint 数据;因为 chk-{checkpointid}/_metadata 是一个二进制文件,使用编辑打开后,会出现不可读的符号和一些明文数据,这显然部分数据序列化了。
chk-{checkpointid}/_metadata 文件内容
 下面是
下面是 flink-state-processor-api jar 读取 _metadata 的 State 数据的代码:
ReadCheckpointData.java
|
|
ReaderFunction.java
|
|
完整的示例 demo,可参考 https://github.com/xinzhuxiansheng/flink/tree/yzhou/release-1.17/flink-examples/flink-blog
看ReadCheckpointData#main()的 API 调用方式与 Flink DataStream API 如出一辙,具体为什么这么写,官网已经给了大部分代码的教程,访问https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/libs/state_processor_api/#keyed-state了解更多。
但针对 StreamWordCount Job State,需要调整的是 ReaderFunction, 不过这里有个痛点, 就是 ReaderFunction#open()方法中的 ValueStateDescriptor 定义,因为从StreamWordCount#main()的处理逻辑中,并没有显式调用 State 的地方,那 ValueStateDescriptor state 的 name,class 又如何知晓呢?
接下来,让我来揭晓。 :)
是StreamGroupedReduceOperator.java, 在之前的 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”的 4)translator 转换 transform 为 StreamNode & StreamEdge 过程 章节中介绍了每个 transformation 都需要一个 Translator 才能转换 StreamNode 或者 StreamEdge,那么接下来,我们看 .sum() 它的 Translator 是 ReduceTransformationTranslator, 在ReduceTransformationTranslator#translateForStreamingInternal()会创建 StreamGroupedReduceOperator对象。
So StreamGroupedReduceOperator 内部包含一个 ValueStateDescriptor stateId 对象,StreamWordCount 会被记录在该 State 中, 那之前的疑问也就明了了, .sum() 内部的 State 记录了统计结果,并且它是 Keyed State 中的一个,可参考文档(https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/state/#using-keyed-state)
ValueState 介绍
ValueState: This keeps a value that can be updated and retrieved (scoped to key of the input element as mentioned above, so there will possibly be one value for each key that the operation sees). The value can be set using update(T) and retrieved using T value().
|
|
在StreamGroupedReduceOperator#StreamGroupedReduceOperator()构造方法打上断点
|
|
- 启动 JobManager 远程调试
- 在 Flink WEB UI 在
Submit New Job触发 StreamWordCount 的Show Plan
所以,可以得到下面的结果:
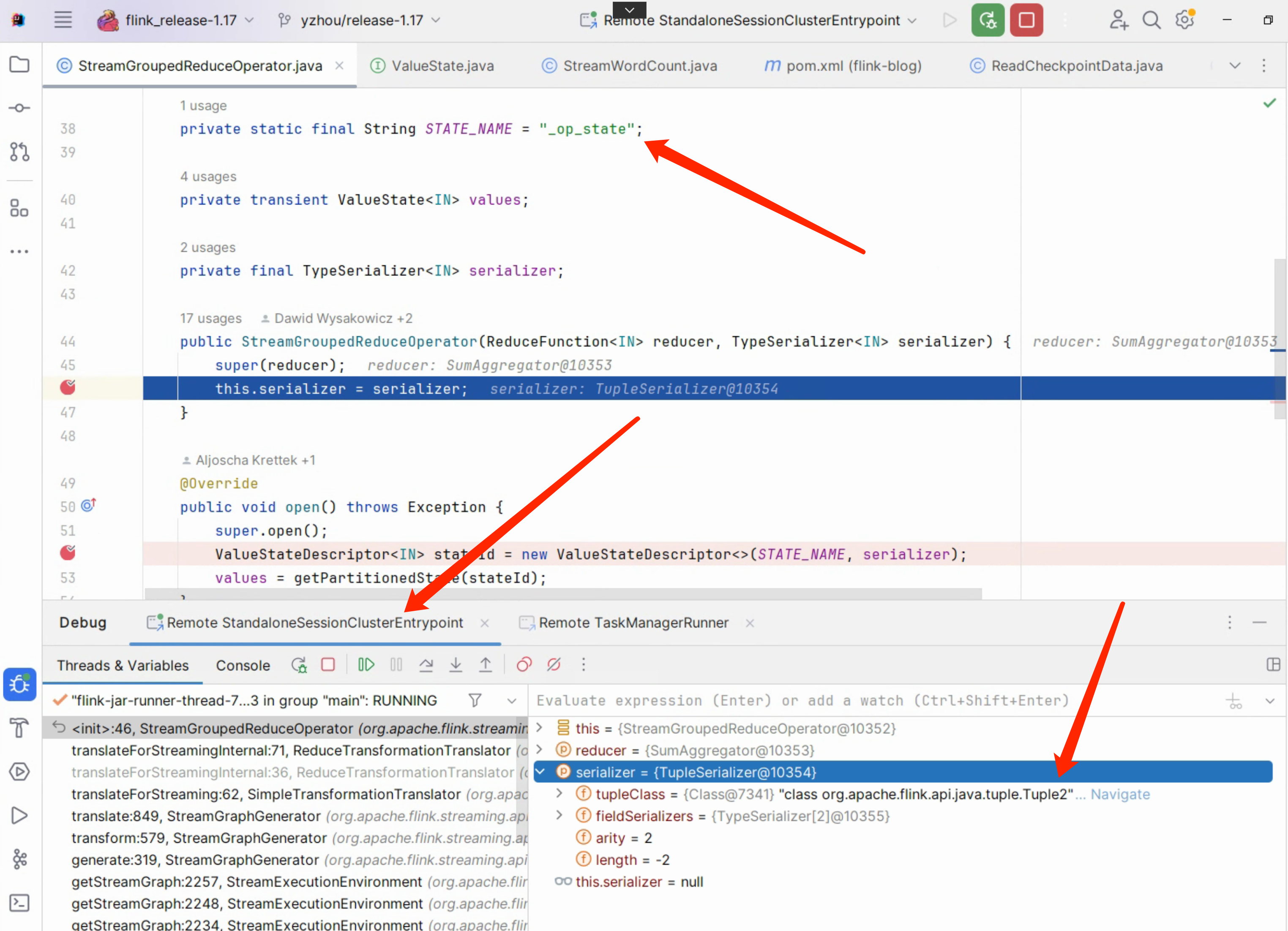 So
So ReaderFunction#open() State 的 name,class 就可以得到。
|
|
其实,这块也可以通过PartitioningResultKeyGroupReader#readMappingsInKeyGroup()方法来查看,因为ReadCheckpointData#main() 将 chk-{checkpointid} 作为数据源,去解析 _metadata。
|
|
下面,展示 从 _metadata 读出的 State 数据:
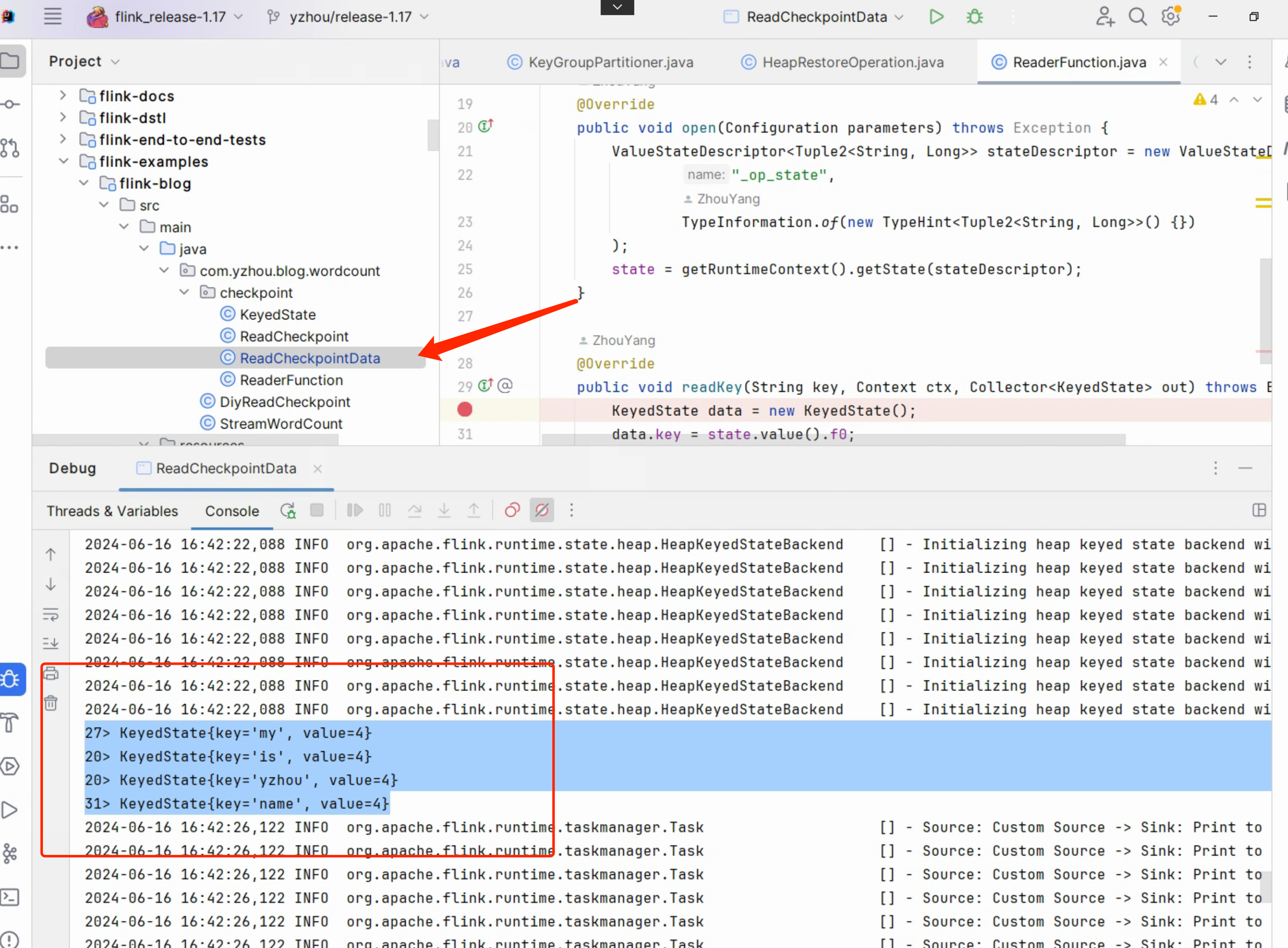

|
|
探索 Checkpoint 写入逻辑环境准备
StreamWordCount Job 通过 conf/flink-conf.yaml 配置 Checkpoint 触发的间隔时间为 60s,若在 调试过程中,60s 间隔太短或者期待能手动触发 Checkpoint,所以调整 Checkpoint 触发策略为自动触发的时间间隔为 86400000 毫秒(24小时)
配置 Checkpoint 自动触发的时间间隔为 86400000 毫秒
Standalone 集群的 execution.checkpointing.interval 参数进行修改,调整为 86400000 毫秒(24 小时)执行一次。
vim conf/flink-conf.yaml
|
|
修改后,重启 Standalone 集群 & 重新提交 StreamWordCount Job。
Http 方式,手动触发 Job Checkpoint
手动触发的 REST API URL: http://<jobmanager>:8081/jobs/<job_id>/checkpoints
|
|
此时,观察 StreamWordCount Job 的 Checkpoints 的 History 页面,列表中的Trigger Time 并不是规律的,这显然是手动触发的效果。
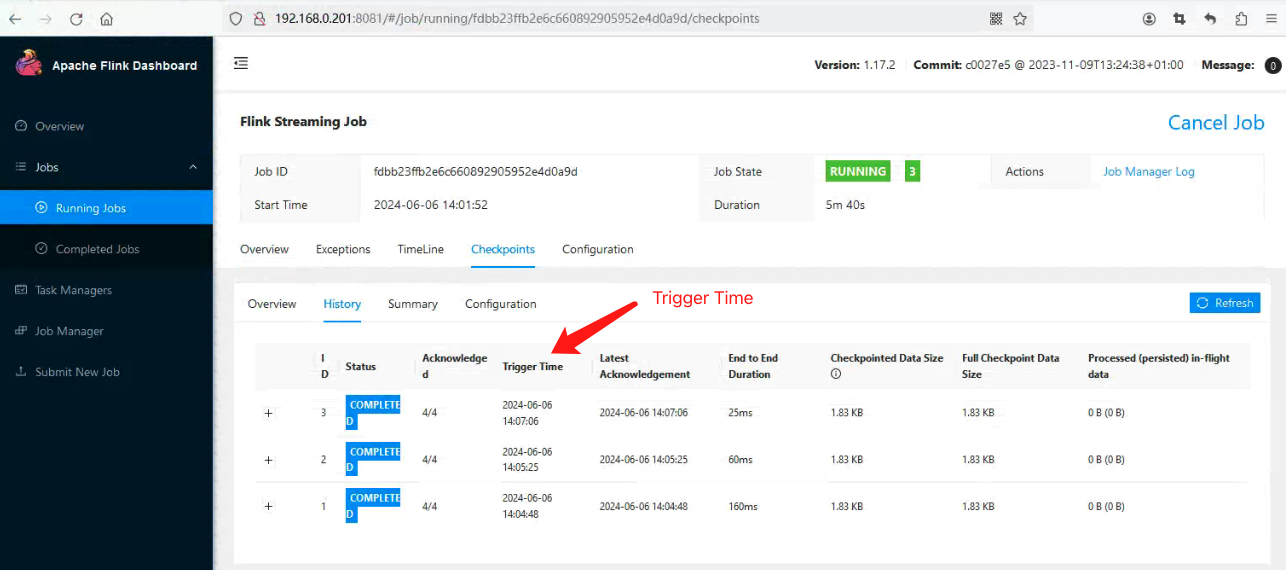 现在有了手动触发,那接下来也就方便我们远程调试了,再加上自动触发 Checkpoint 的时间间隔调整到 24 小时,所以在这段时间里面,并不会打扰调试的过程。
现在有了手动触发,那接下来也就方便我们远程调试了,再加上自动触发 Checkpoint 的时间间隔调整到 24 小时,所以在这段时间里面,并不会打扰调试的过程。
根据手动触发 Checkpoint URL 找到 对应的 Netty Handler
在之前的 Blog “Flink 源码 - Standalone - 探索 Flink Stream Job Show Plan 实现过程 - 构建 StreamGraph”中的 “Flink WEB UI 远程调试”章节介绍过 Flink WEB UI 是由 Netty 提供的 Server 服务 以及它的 Handler 查找思路,在这里就不过多介绍,若还有疑问,可翻篇之前的 Blog。
CheckpointTriggerHandler 是 URL:http://:8081/jobs/<job_id>/checkpoints 的处理 Handler。
总结
State & Checkpoint 是优秀的,但如何保证其高效、可靠 该篇 Blog 并未介绍。 后续我会阐述…
其实该篇没有介绍 CheckpointMetadata.java, 它是 chk-{checkpointid}/_metadata 对应实体,在_metadata 文件写入流中使用的字节位写入,这些对 Checkpoint 构造都是至关重要的。 涉及到点太多,会在后续补上。
I need time!!!
refer
1.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/concepts/stateful-stream-processing/
2.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/ops/state/checkpoints/
3.https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/libs/state_processor_api/