I never meant to write this blog. I had a whole blog series about Flink SQL lined up…and then I started to write it and realised rapidly that one’s initial exposure to Flink and Flink SQL can be somewhat, shall we say, interesting. Interesting, as in the curse, “may you live in interesting times”. Because as wonderful and as powerful Flink is, it is not a simple beast to run for yourself, even as a humble developer just trying to try out some SQL.
Quite a few of the problems are a subset of the broader challenge of getting the right JAR in the right place at the right time—a topic worth its own blog.
Let’s start off by looking at the JDBC connector. This provides its own catalog, which I explored recently in another post. In that article I trod the happy path; below are the potholes and pitfalls that befell me on the way 🧌.
The JDBC Catalog
You can learn more about the JDBC Catalog, and Flink SQL Catalogs in general, here and here.
We’ll start by provisioning the environment. Using this Docker Compose from the Decodable examples repository we can spin up a Postgres container and a Flink cluster. In the Flink cluster I’ve added the Flink JDBC Connector and the Postgres JDBC driver.
Once the containers are running you can inspect the pre-provisioned Postgres database:
1
2
3
4
5
6
7
8
9
10
|
docker compose exec -it postgres psql -h localhost -d world-db -U worldCopy
world-db-# \d
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+-------
public | city | table | world
public | country | table | world
public | country_flag | table | world
public | country_language | table | world
(4 rows)Copy
|
Now we’ll head into Flink SQL and try to create a JDBC catalog so that we can query these Postgres tables:
1
2
3
4
5
6
7
8
9
10
|
docker compose exec -it jobmanager bash -c "./bin/sql-client.sh"Copy
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'localhost:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentExceptionCopy
|
Uh-oh. We’re not off to a particularly illustrious start. What does Illegal Argument— the argument that we’ve specified for base-url is “Illegal” because it needs the fully qualified JDBC URL prefix. Let’s try again:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'jdbc:postgres://localhost:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Could not find any jdbc dialect factory that can handle url 'jdbc:postgres://localhost:5432' that implements 'org.apache.flink.connector.jdbc.dialect.JdbcDialectFactory' in the classpath.
Available factories are:
org.apache.flink.connector.jdbc.databases.derby.dialect.DerbyDialectFactory
org.apache.flink.connector.jdbc.databases.mysql.dialect.MySqlDialectFactory
org.apache.flink.connector.jdbc.databases.oracle.dialect.OracleDialectFactory
org.apache.flink.connector.jdbc.databases.postgres.dialect.PostgresDialectFactory
org.apache.flink.connector.jdbc.databases.sqlserver.dialect.SqlServerDialectFactory
|
This error is definitely more esoteric than the last one. At the heart of it is this:
-
1
|
Could not find any jdbc dialect factory that can handle url 'jdbc:postgres://localhost:5432'
|
We’ve told the JDBC connector that it’s a JDBC dialect (jdbc:) but it can’t work out what dialect of JDBC it is. It tells us which “factories” it does understand:
1
2
3
4
5
6
7
|
Available factories are:
`[…].jdbc.databases.derby.dialect.DerbyDialectFactory`
`[…].jdbc.databases.mysql.dialect.MySqlDialectFactory`
`[…].jdbc.databases.oracle.dialect.OracleDialectFactory`
`[…].jdbc.databases.postgres.dialect.PostgresDialectFactory`
`[…].jdbc.databases.sqlserver.dialect.SqlServerDialectFactory`
|
So what’s up with this? Well if we look at the Postgres JDBC URL spec we’ll see that it should be jdbc:postgresql (note the ql suffix that we’ve missed above). Let’s try that:
1
2
3
4
5
6
7
8
9
10
11
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'jdbc:postgresql://localhost:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[ERROR] Could not execute SQL statement. Reason:
java.net.ConnectException: Connection refused (Connection refused)
Flink SQL>Copy
|
Hey, another new error! That’s because localhost in the context of the container running sql-client is the Flink job manager container, so there is no Postgres on port 5432 to be found. Instead, we need to reference the Postgres container, conveniently called in our case postgres.
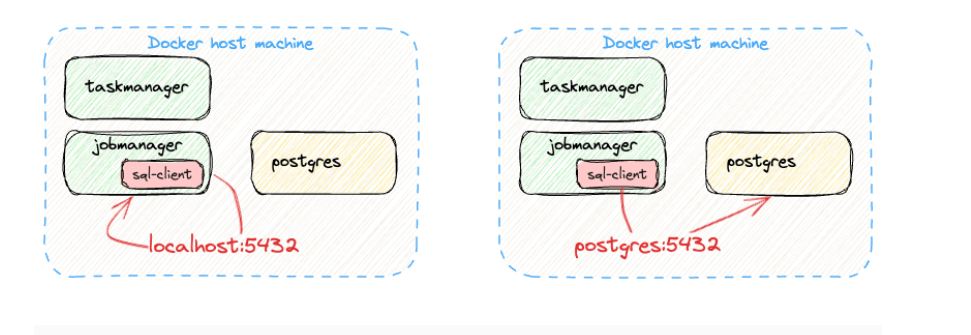
1
2
3
4
5
6
7
8
9
10
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'jdbc:postgresql://postgres:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[INFO] Execute statement succeed.
Flink SQL>Copy
|
Phew! 😅
Whilst we’re here with a Catalog created in Flink SQL, let’s cover off another thing that kept tripping me up. Since we’ve created the catalog, we want to tell Flink SQL to now use it as the current catalog:
1
2
3
|
Flink SQL> USE c_jdbc;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.CatalogException: A database with name [c_jdbc] does not exist in the catalog: [default_catalog].Copy
|
This comes about from an inconsistency (IMHO) in the syntax of Flink SQL here. USE on its own in Flink SQL meansUSE DATABASE. So if you want to actually switch the current catalog, the command isUSE CATALOG.
1
2
|
Flink SQL> USE CATALOG c_jdbc;
[INFO] Execute statement succeed.Copy
|
On the other hand, if you’re getting this error and you actually did mean to switch the current database then the error is what it says - the database you’ve specified doesn’t exist in the current catalog. Check the current catalog withSHOW CURRENT CATALOG.
What’s Running Where? (Fun with Java Versions)
To recount the next incident, I’ll start by describing the environment. This was before the JDBC connector for Flink 1.18 was released, so I was running Flink 1.17.1, and locally on my laptop.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Unpack a fresh Flink 1.17.1 tarball
tar xf flink-1.17.1-bin-scala_2.12.tgz && cd flink-1.17.1
# Install JDBC connector and Postgres JDBC driver
cd lib
curl https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc/3.1.2-1.17/flink-connector-jdbc-3.1.2-1.17.jar -O
curl https://repo.maven.apache.org/maven2/org/postgresql/postgresql/42.7.3/postgresql-42.7.3.jar -O
cd ..
# Launch a Flink cluster and SQL Client
$ ./bin/start-cluster.sh && ./bin/sql-client.sh
Starting cluster.
Starting standalonesession daemon on host asgard08.
Starting taskexecutor daemon on host asgard08.
[… cute ANSI Squirrel pic…]
Flink SQL>Copy
|
I’ve also got the same Postgres Docker image as above running, but just as a standalone container with port 5432 open for connections:
1
2
3
4
|
docker run --rm --detach \
--name postgres \
--publish 5432:5432 \
ghusta/postgres-world-db:2.10
|
Now we’ll do the same as above—create a JDBC catalog. Note that this time the base-url is referencing localhost because Flink is running locally on the machine and I’ve exposed Postgres’ port from its container, so localhost is the right place to access it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'jdbc:postgresql://localhost:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[INFO] Execute statement succeed
Flink SQL> USE `c_jdbc`.`world-db`;
[INFO] Execute statement succeed.
Flink SQL> SHOW TABLES;
+-------------------------+
| table name |
+-------------------------+
| public.city |
| public.country |
| public.country_flag |
| public.country_language |
+-------------------------+
4 rows in setCopy
|
Let’s try querying one of these tables:
1
2
3
|
Flink SQL> SELECT * FROM country_flag LIMIT 5;
[ERROR] Could not execute SQL statement. Reason:
java.lang.reflect.InaccessibleObjectException: Unable to make field private static final int java.lang.Class.ANNOTATION accessible: module java.base does not "opens java.lang" to unnamed module @52bf72b5Copy
|
Huh. After a bit of head scratching I found a reference on StackOverflow to the version of Java, so I checked that. I’m using the excellent SDKMan which makes this kind of thing very straightforward:
1
2
3
|
$ sdk current java
Using java version 17.0.5-temCopy
|
That might be a problem. Support for Java 17 was only added in Flink 1.18 and is considered experimental at this time. I reverted my Java version to 11, and launched the SQL Client again:
1
2
3
4
5
|
$ sdk install java 11.0.21-tem
$ sdk use java 11.0.21-tem
Using java version 11.0.21-tem in this shell.
$ ./bin/sql-client.shCopy
|
I recreated the catalog, switched to the world-db database within it, and tried my SELECT again:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
> 'type' = 'jdbc',
> 'base-url' = 'jdbc:postgresql://localhost:5432',
> 'default-database' = 'world-db',
> 'username' = 'world',
> 'password' = 'world123'
> );
[INFO] Execute statement succeed.
Flink SQL> USE `c_jdbc`.`world-db`;
[INFO] Execute statement succeed.
Flink SQL> SELECT * FROM country_flag LIMIT 5;Copy
|
At this point there’s no error… but no nothing either. After a minute or so I get this:
1
2
|
[ERROR] Could not execute SQL statement. Reason:
java.net.ConnectException: Connection refusedCopy
|
This puzzles me, because Postgres is up—and we can verify the connectivity from SQL Client withSHOW TABLES:
1
2
3
4
5
6
7
8
9
10
|
Flink SQL> SHOW TABLES;
+-------------------------+
| table name |
+-------------------------+
| public.city |
| public.country |
| public.country_flag |
| public.country_language |
+-------------------------+
4 rows in setCopy
|
So where is the Connection that is beingrefused?
Log files are generally a good place to go and look, particularly when one starts troubleshooting things that are beyond the obvious. If we search the Flink log folder for the Connection refused error we get this:
1
2
3
4
5
|
$ grep -r "Connection refused" log
log/flink-rmoff-sql-client-asgard08.log:java.util.concurrent.CompletionException: org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: localhost/127.0.0.1:8081
flink-rmoff-sql-client-asgard08.log:Caused by: org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: localhost/127.0.0.1:8081
flink-rmoff-sql-client-asgard08.log:Caused by: java.net.ConnectException: Connection refused
[…]Copy
|
What’s interesting here is the port number. 8081 is not the Postgres port (5432) but the Flink job manager.

So whilst the SQL Client itself is making the request to Postgres for a SHOW TABLES request, a SELECT gets run as a Flink job—which the SQL Client will send to the job manager in order for it to execute it on an available task manager node.
The outstanding question though is why the job manager isn’t available. We launched it already above when we did./bin/start-cluster.sh. Or did we? Let’s check the running Java process list:
1
2
3
|
$ jps
23795 Jps
3990 SqlClientCopy
|
So neither the job manager nor task manager processes are running. Were they ever?
1
2
3
4
5
6
|
$ head log/flink-rmoff-standalonesession-1-asgard08.log
2024-04-05 14:01:48,837 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Shutting StandaloneSessionClusterEntrypoint down with application status FAILED. Diagnostics java.lang.IllegalAccessError: class org.apache.flink.util.NetUtils (in unnamed module @0x5b8dfcc1) cannot access class sun.net.util.IPAddressUtil (in module java.base) because module java.base does not export sun.net.util to unnamed module @0x5b8dfcc1
[…]
$ head log/flink-rmoff-taskexecutor-2-asgard08.log
2024-04-05 14:02:11,255 ERROR org.apache.flink.runtime.taskexecutor.TaskManagerRunner [] - Terminating TaskManagerRunner with exit code 1.
java.lang.IllegalAccessError: class org.apache.flink.util.NetUtils (in unnamed module @0x1a482e36) cannot access class sun.net.util.IPAddressUtil (in module java.base) because module java.base does not export sun.net.util to unnamed module @0x1a482e36Copy
|
My guess is that the Java version caused these fatal errors. Regardless, in effect what I had running locally was this:
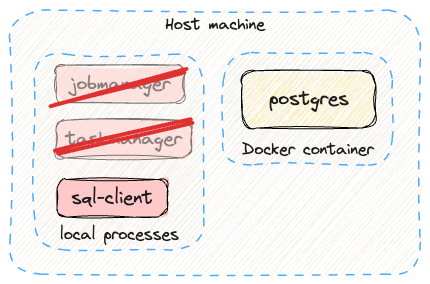
No wonder things didn’t work! Realising the problem I’d had with SQL Client and the Java version, it was a fair guess that the same issue was true for the Flink cluster components.
Let’s try again, with Java 11, and use jps to verify that things are starting up correctly:
1
2
3
4
5
6
7
8
|
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host asgard08.
Starting taskexecutor daemon on host asgard08.
$ jps
28774 StandaloneSessionClusterEntrypoint
29064 Jps
29049 TaskManagerRunnerCopy
|
Better! Now we’ll launch SQL Client and see if things are now working as they should:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
Flink SQL> CREATE CATALOG c_jdbc WITH (
'type' = 'jdbc',
'base-url' = 'jdbc:postgresql://localhost:5432',
'default-database' = 'world-db',
'username' = 'world',
'password' = 'world123'
);
[INFO] Execute statement succeed.
Flink SQL> USE `c_jdbc`.`world-db`;
[INFO] Execute statement succeed.
Flink SQL> SELECT * FROM country_flag LIMIT 5;
+----+---------+-----------+--------------------+
| op | code2 | emoji | unicode |
+----+---------+-----------+--------------------+
| +I | AD | 🇦🇩 | U+1F1E6 U+1F1E9 |
| +I | AE | 🇦🇪 | U+1F1E6 U+1F1EA |
| +I | AF | 🇦🇫 | U+1F1E6 U+1F1EB |
| +I | AG | 🇦🇬 | U+1F1E6 U+1F1EC |
| +I | AI | 🇦🇮 | U+1F1E6 U+1F1EE |
+----+---------+-----------+--------------------+
Received a total of 5 rowsCopy
|
🎉 that’s more like it!
What’s Running Where? (Fun with JAR dependencies)
I wrote a whole article about JAR files because they are so central to the successful operation of Flink. Let’s look at an example of the kind of “fun” you can get with them. Moving around the Flink versions, this incident was with 1.18.1. Let’s start with a clean slate and a fresh Flink install:
1
2
|
# Unpack a fresh Flink 1.18.1 tarball
tar xf flink-1.18.1-bin-scala_2.12.tgz && cd flink-1.18.1Copy
|
I was exploring the Filesystem connector and wanted to see if I could write a file in Parquet format.
1
2
3
4
5
6
7
8
9
10
11
|
Flink SQL> CREATE TABLE t_foo (c1 varchar, c2 int)
WITH (
'connector' = 'filesystem',
'path' = 'file:///tmp/t_foo',
'format' = 'parquet'
);
[INFO] Execute statement succeed.
Flink SQL> INSERT INTO t_foo VALUES ('bar',42);
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Could not find any format factory for identifier 'parquet' in the classpath.Copy
|
This error (Could not find any factory for identifier) usually means that there’s a JAR missing. From the Maven repository I grabbed flink-sql-parquet-1.18.1.jar
1
2
|
cd ./lib
curl https://repo1.maven.org/maven2/org/apache/flink/flink-sql-parquet/1.18.1/flink-sql-parquet-1.18.1.jar -OCopy
|
After restarting the SQL Client I got a different error:
1
2
3
|
Flink SQL> INSERT INTO t_foo VALUES ('bar',42);
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.conf.ConfigurationCopy
|
This one I’d come across before - I needed the Hadoop JARs (discussed in more detail here). I downloaded Hadoop (words I never thought I’d write in 2024 😉) and set the environment variable:
1
|
export HADOOP_CLASSPATH=$(~/hadoop/hadoop-3.3.4/bin/hadoop classpath)Copy
|
I then restarted the SQL Client (with a small detour via this PR for a SqlClientException: Could not read from command line error):
1
2
3
4
5
6
7
8
9
10
11
12
|
Flink SQL> CREATE TABLE t_foo (c1 varchar, c2 int)
WITH (
'connector' = 'filesystem',
'path' = 'file:///tmp/t_foo',
'format' = 'parquet'
);
[INFO] Execute statement succeed.
Flink SQL> INSERT INTO t_foo VALUES ('bar',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: c49df5c96e013007d6224b06e218533cCopy
|
Success! Or so I thought…
1
2
3
|
Flink SQL> SELECT * FROM t_foo;
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.flink.formats.parquet.ParquetColumnarRowInputFormatCopy
|
Kinda confusing, since we only just installed the Parquet JAR (which this error seems to be referencing).

Let’s go back to our log files and look at what’s going on here. I’ll search for the error:
1
2
3
4
|
$ grep -r -l "java.lang.ClassNotFoundException" ./log
./log/flink-rmoff-taskexecutor-0-asgard08.log
./log/flink-rmoff-sql-client-asgard08.log
./log/flink-rmoff-standalonesession-0-asgard08.logCopy
|
So it’s being logged back the SQL Client (which we saw), but also taskexecutor (the Task Manager) and standalonesession (the Job Manager). Opening up the files and looking closely at the timestamps shows us that the SQL Client is surfacing the above error from a call to the job manager (Could not start the JobMaster):
1
2
3
4
5
6
|
ERROR org.apache.flink.table.gateway.service.operation.OperationManager [] - Failed to execute the operation 072fdeef-76bc-4813-a2af-5444b7806737.
org.apache.flink.table.api.TableException: Failed to execute sql
Caused by: org.apache.flink.util.FlinkException: Failed to execute job 'collect'.
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
[…]
Caused by: java.lang.ClassNotFoundException: org.apache.flink.formats.parquet.ParquetColumnarRowInputFormatCopy
|
In fact, if we open up the rather useful Flink Dashboard UI we can see a whole lotta red:

Not only has the collect job (theSELECT ) failed—but also theINSERT. Above, I saw this:
1
2
3
4
|
Flink SQL> INSERT INTO t_foo VALUES ('bar',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: c49df5c96e013007d6224b06e218533cCopy
|
and somewhat rashly assumed that successfully submitted meant that it had run successfully. Oh, foolish and naïve one am I! This is an asynchronous job submission. The only success was that the job was submitted to the job manager to execute. If we dig into the job in the UI (or indeed the log files for the taskexecutor process and standalonesession process and scroll up from the other error), we’ll see why the INSERT failed—for a similar reason as theSELECT:

1
|
java.lang.ClassNotFoundException: org.apache.flink.formats.parquet.ParquetWriterFactoryCopy
|
So what is happening here? Well we’ve happily made the Parquet JAR available to the SQL Client… yet the actual business of writing and reading data is not done by the client, but the Flink task manager—and we didn’t put the JAR there. Or rather we did (since we’re running on the same local installation as our SQL Client is started from), but we didn’t restart the cluster components. We also need to remember to make sure that the HADOOP_CLASSPATH is in the environment variables when we do:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$ ./bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 62910) on host asgard08.
Stopping standalonesession daemon (pid: 62630) on host asgard08.
# Make the Hadoop JARs available
$ export HADOOP_CLASSPATH=$(~/hadoop/hadoop-3.3.4/bin/hadoop classpath)
# Check that the Parquet JAR is there
$ ls -l ./lib/*parquet*
-rw-r--r--@ 1 rmoff staff 6740707 5 Apr 17:06 ./lib/flink-sql-parquet-1.18.1.jar
# Start the cluster
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host asgard08.
Starting taskexecutor daemon on host asgard08.Copy
|
Now when we run the INSERT and SELECT from the SQL Client, things work as they should:
1
2
3
4
5
6
7
8
9
10
11
12
|
Flink SQL> INSERT INTO t_foo VALUES ('bar',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 850b4771b79845790e48d57c7172f203
Flink SQL> SELECT * FROM t_foo;
+----+--------------------------------+-------------+
| op | c1 | c2 |
+----+--------------------------------+-------------+
| +I | bar | 42 |
+----+--------------------------------+-------------+
Received a total of 1 rowCopy
|
The Flink Dashboard shows that things are healthy too:

And we can also double check from within the SQL Client itself that the INSERT job ran successfully:
1
2
3
4
5
6
7
|
Flink SQL> SHOW JOBS;
+----------------------------------+----------------------------------------------------+----------+-------------------------+
| job id | job name | status | start time |
+----------------------------------+----------------------------------------------------+----------+-------------------------+
| 850b4771b79845790e48d57c7172f203 | insert-into_default_catalog.default_database.t_foo | FINISHED | 2024-04-05T17:02:38.143 |
+----------------------------------+----------------------------------------------------+----------+-------------------------+
1 row in setCopy
|
A JAR full of Trouble
Most of the problems that I’ve encountered seem bewildering at first, but once solved can be understood and reverse-engineered to see how I could, in theory, have avoided the problem from better comprehension of the documentation or concepts. This one though defies that. I fixed the error, but I still have no idea what causes it. Explanations welcome!
My original starting point was this Docker Compose file, which provides a Flink stack with support for writing to Apache Iceberg on S3-compatible MinIO. I used it as the basis for exploring catalogs provided by the Iceberg Flink connector, including using JDBC as a backing store for the catalog. I added a Postgres container to the setup, as well as adapting the base Flink container to include the necessary Postgres driver.
The Iceberg JDBC catalog (org.apache.iceberg.jdbc.JdbcCatalog) uses a JDBC database for storing the metadata of the catalog, similar to what the Hive metastore would. When we create a Flink SQL catalog and objects (tables, etc) within it we’ll get rows written to Postgres, and when we run DML to interact with the Flink SQL table we’d expect to have queries run against Postgres to fetch the metadata for the table.

I created an Iceberg catalog with JDBC metastore and a table within it:
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE CATALOG jdbc_catalog WITH (
'type' = 'iceberg',
'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO',
'client.assume-role.region' = 'us-east-1',
'warehouse' = 's3://warehouse',
's3.endpoint' = 'http://storage:9000',
's3.path-style-access' = 'true',
'catalog-impl' = 'org.apache.iceberg.jdbc.JdbcCatalog',
'uri' ='jdbc:postgresql://postgres:5432/world-db?user=world&password=world123');
USE `jdbc_catalog`.`default`;
CREATE TABLE t_foo (c1 varchar, c2 int);Copy
|
Then I added a row of data, and tried to read it back:
1
2
3
4
5
6
7
8
|
Flink SQL> INSERT INTO t_foo VALUES ('a',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 21803e3a205877e801536214c9f2d560
Flink SQL> SELECT * FROM t_foo;
[ERROR] Could not execute SQL statement. Reason:
java.sql.SQLException: No suitable driver found for jdbc:postgresql://postgres:5432/world-db?user=world&password=world123Copy
|
As I’d learnt the hard way previously, an INSERT in Flink SQL is run asynchronously, so I now knew better than to think that it had succeeded—the SELECT was just to see what would happen.
Looking at the task manager log we can see that the INSERT failed with the same error as theSELECT:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
2024-04-09 16:15:13,773 WARN org.apache.flink.runtime.taskmanager.Task
[] - IcebergFilesCommitter -> Sink: IcebergSink jdbc_catalog.default.t_foo (1/1) #0 (fa6353abff898aa3e4005455ff93a5cb_90bea66de1c231edf33913ecd54406c1_0_0)
switched from INITIALIZING to FAILED with failure cause: org.apache.iceberg.jdbc.UncheckedSQLException: Failed to connect: jdbc:postgresql://postgres:5432/world-db?user=world&password=world123
at org.apache.iceberg.jdbc.JdbcClientPool.newClient(JdbcClientPool.java:57)
at org.apache.iceberg.jdbc.JdbcClientPool.newClient(JdbcClientPool.java:30)
at org.apache.iceberg.ClientPoolImpl.get(ClientPoolImpl.java:125)
at org.apache.iceberg.ClientPoolImpl.run(ClientPoolImpl.java:56)
at org.apache.iceberg.ClientPoolImpl.run(ClientPoolImpl.java:51)
at org.apache.iceberg.jdbc.JdbcCatalog.initializeCatalogTables(JdbcCatalog.java:146)[…]
Caused by: java.sql.SQLException: No suitable driver found for jdbc:postgresql://postgres:5432/world-db?user=world&password=world123
at java.sql/java.sql.DriverManager.getConnection(Unknown Source)
at java.sql/java.sql.DriverManager.getConnection(Unknown Source)
at org.apache.iceberg.jdbc.JdbcClientPool.newClient(JdbcClientPool.java:55)
... 22 moreCopy
|
The stack trace confirms that this error is when the connection to the Postgres database is attempted as part of the catalog access (org.apache.iceberg.jdbc.JdbcCatalog.initializeCatalogTables), and that the root cause is that the Postgres JDBC driver can’t be found.
What was puzzling was that the JDBC driver was present on the Flink task manager container, as well as the SQL client container. In fact, even more puzzling was that the catalog and table creation had worked—so the connection to Postgres for those statements must have been ok.
To save you some of the pain of debugging this, I’ll point out that the Docker Compose used a different image for SQL Client than the Flink task manager and job manager:

I confirmed, re-confirmed, and then confirmed again once more that the Postgres JDBC driver was present on the Flink task manager
1
2
|
root@a3a8182bd227:/opt/flink# ls -l /opt/flink/lib/postgresql-42.7.1.jar
-rw-r--r-- 1 root root 1084174 Jan 23 17:36 /opt/flink/lib/postgresql-42.7.1.jarCopy
|
I also checked that it was present in the Classpath too by looking at the startup messages in the log file:
1
2
3
|
[…]
org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Classpath: /opt/flink/lib/bundle-2.20.18.jar:/opt/flink/lib/flink-cep-1.16.1.jar:/opt/flink/lib/flink-connector-files-1.16.1.jar:/opt/flink/lib/flink-csv-1.16.1.jar:/opt/flink/lib/flink-json-1.16.1.jar:/opt/flink/lib/flink-scala_2.12-1.16.1.jar:/opt/flink/lib/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar:/opt/flink/lib/flink-shaded-zookeeper-3.5.9.jar:/opt/flink/lib/flink-sql-connector-hive-2.3.9_2.12-1.16.1.jar:/opt/flink/lib/flink-table-api-java-uber-1.16.1.jar:/opt/flink/lib/flink-table-planner-loader-1.16.1.jar:/opt/flink/lib/flink-table-runtime-1.16.1.jar:/opt/flink/lib/hadoop-common-2.8.3.jar:/opt/flink/lib/iceberg-flink-runtime-1.16-1.3.1.jar:/opt/flink/lib/log4j-1.2-api-2.17.1.jar:/opt/flink/lib/log4j-api-2.17.1.jar:/opt/flink/lib/log4j-core-2.17.1.jar:/opt/flink/lib/log4j-slf4j-impl-2.17.1.jar:/opt/flink/lib/postgresql-42.7.1.jar:/opt/flink/lib/flink-dist-1.16.1.jar::::
[…]Copy
|
One thing that did stand out was the version of Flink - 1.16.1. No reason why this should be an issue (and in the end it wasn’t), but I decided to try and rebuild the environment using my own Docker Compose from scratch with Flink 1.18.1. You can find this on GitHub here. As well as bumping the Flink version, I switched to my previous deployment model of a single Flink image, and running the SQL Client within one of the containers:

All the JARs I kept the same as in the initial deployment, except pulling in the correct version for Flink 1.18.1 where needed:
- bundle-2.20.18.jar
- flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
- hadoop-common-2.8.3.jar
- iceberg-flink-runtime-1.18-1.5.0.jar
- postgresql-42.7.1.jar
This time I got the same error, but at a different time—as soon as I tried to create the catalog:
1
2
3
4
5
6
7
8
9
10
11
|
Flink SQL> CREATE CATALOG jdbc_catalog WITH (
'type' = 'iceberg',
'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO',
'client.assume-role.region' = 'us-east-1',
'warehouse' = 's3://warehouse',
's3.endpoint' = 'http://minio:9000',
's3.path-style-access' = 'true',
'catalog-impl' = 'org.apache.iceberg.jdbc.JdbcCatalog',
'uri' ='jdbc:postgresql://postgres:5432/world-db?user=world&password=world123');
[ERROR] Could not execute SQL statement. Reason:
java.sql.SQLException: No suitable driver found for jdbc:postgresql://postgres:5432/world-db?user=world&password=world123Copy
|
This makes sense when we realise that the SQL Client is running using the same image as the Flink cluster—where we saw the error above. So if there’s a problem with this environment, then it’s going to manifest itself in SQL Client too.
This then prompted me to look at the difference between the original SQL Client image, and the Flink taskmanager. I knew that I’d added the Postgres JDBC driver to them, but I’d not looked more closely at their base configuration.
It turned out that the Flink Hive connector (flink-sql-connector-hive-2.3.9_2.12-1.16.1.jar) was present on the taskmanager image, but not the SQL Client.
Back on my 1.18.1 environment, I removed this JAR, rebuilt the Docker image and retried the experiment. Things looked better straight away:
1
2
3
4
5
6
7
8
9
10
|
Flink SQL> CREATE CATALOG jdbc_catalog WITH (
> 'type' = 'iceberg',
> 'io-impl' = 'org.apache.iceberg.aws.s3.S3FileIO',
> 'client.assume-role.region' = 'us-east-1',
> 'warehouse' = 's3://warehouse',
> 's3.endpoint' = 'http://minio:9000',
> 's3.path-style-access' = 'true',
> 'catalog-impl' = 'org.apache.iceberg.jdbc.JdbcCatalog',
> 'uri' ='jdbc:postgresql://postgres:5432/world-db?user=world&password=world123');
[INFO] Execute statement succeed.Copy
|
I successfully created a table:
1
2
3
4
5
6
7
8
|
Flink SQL> create database `jdbc_catalog`.`db01`;
[INFO] Execute statement succeed.
Flink SQL> use `jdbc_catalog`.`db01`;
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE t_foo (c1 varchar, c2 int);
[INFO] Execute statement succeed.Copy
|
Over in Postgres I could see the catalog entries:
1
2
3
4
5
6
7
8
9
10
11
|
world-db=# select * from iceberg_namespace_properties ;
catalog_name | namespace | property_key | property_value
--------------+-----------+--------------+----------------
jdbc_catalog | db01 | exists | true
(1 row)
world-db=# select * from iceberg_tables;
catalog_name | table_namespace | table_name | metadata_location | previous_metadata_location
--------------+-----------------+------------+---------------------------------------------------------------------------------------------+----------------------------
jdbc_catalog | db01 | t_foo | s3://warehouse/db01/t_foo/metadata/00000-5073e16c-36c7-493e-8653-30122a9460e5.metadata.json |
(1 row)Copy
|
Now for the crunch moment… writing data:
1
2
3
4
5
6
7
8
9
10
11
12
|
Flink SQL> INSERT INTO t_foo VALUES ('a',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 33d09054f65555ec08a96e1f9817f77d
Flink SQL> SHOW JOBS ;
+----------------------------------+-------------------------------------+----------+-------------------------+
| job id | job name | status | start time |
+----------------------------------+-------------------------------------+----------+-------------------------+
| 33d09054f65555ec08a96e1f9817f77d | insert-into_jdbc_catalog.db01.t_foo | FINISHED | 2024-04-10T10:20:53.283 |
+----------------------------------+-------------------------------------+----------+-------------------------+
1 row in setCopy
|
It’s looking promising (the job showsFINISHED)…
1
2
3
4
5
6
7
|
Flink SQL> SELECT * FROM t_foo;
+----+--------------------------------+-------------+
| op | c1 | c2 |
+----+--------------------------------+-------------+
| +I | a | 42 |
+----+--------------------------------+-------------+
Received a total of 1 rowCopy
|
Success! But what is going on?
With the Flink Hive Connector JAR (flink-sql-connector-hive-2.3.9_2.12-1.18.1.jar ) present, Flink can’t find the Postgres JDBC Driver:
1
|
java.sql.SQLException: No suitable driver found for jdbc:postgresql://postgres:5432/world-db?user=world&password=world123Copy
|
If I remove the Hive connector JAR, then Flink finds the Postgres JDBC driver and things are just fine.

When looking at the Hive connector JAR on Maven and peering at the digit-salad that is the JAR file naming style I did notice that 2.3.9 is not the latest Hive version:

So, in the interest of hacking around to learn stuff, I gave the most recent version (3.1.3) of the JAR (flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar) a try. Same 1.18.1 environment as above when things didn’t work, except with flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar in the place of flink-sql-connector-hive-2.3.9_2.12-1.18.1.jar and…it works.
So ultimately it seems that something to do with flink-sql-connector-hive-2.3.9_2.12-1.18.1.jar stops Flink from being able to find the Postgres JDBC Driver. I have no idea why. But at least I know now how to fix it 🙂
Writing to S3 from Flink
Unlike the previous problem, this one makes sense once you get it working and look back over what was needed. Nonetheless, it took me a lot of iterating (a.k.a. changing random things) to get it to work.
Follow along as I relive the journey…
I’ve got Flink 1.18 and a standalone Hive Metastore container, as well as a MinIO container. MinIO is a S3-compatible object store that you can run locally, making it perfect for this kind of playground.
The stack is running under Docker Compose (you’ll find this on GitHub if you want to try it).

The first step is creating the catalog (I’m using Hive) and table:
1
2
3
4
5
6
7
8
|
Flink SQL> CREATE CATALOG c_hive WITH (
'type' = 'hive',
'hive-conf-dir' = './conf/');
[INFO] Execute statement succeed.
Flink SQL> USE `c_hive`.`default`;
[INFO] Execute statement succeed.Copy
|
Next up we define a table using the filesystem connector and an S3 path.
1
2
3
4
5
6
7
|
Flink SQL> CREATE TABLE t_foo_fs (c1 varchar, c2 int)
WITH (
'connector' = 'filesystem',
'path' = 's3://warehouse/t_foo_fs/',
'format' = 'csv'
);
[INFO] Execute statement succeed.Copy
|
And then we try to add some data, which doesn’t work (the job ends with FAILED status):
1
2
3
4
5
6
7
8
9
10
11
|
Flink SQL> INSERT INTO t_foo_fs VALUES ('a',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 76dd5a9044c437a2e576f29df86a3df4
Flink SQL> SHOW JOBS;
+----------------------------------+-------------------------------------+--------+-------------------------+
| job id | job name | status | start time |
+----------------------------------+-------------------------------------+--------+-------------------------+
| 76dd5a9044c437a2e576f29df86a3df4 | insert-into_c_hive.default.t_foo_fs | FAILED | 2024-04-10T14:42:12.597 |
+----------------------------------+-------------------------------------+--------+-------------------------+Copy
|
Over to the cluster log files to see what the problem is. The jobmanager log shows us this:
1
2
3
4
5
6
7
8
9
10
11
|
2024-04-10 14:35:58,809 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] -
Source: Values[1] -> StreamingFileWriter -> Sink: end (1/1) (2c1d784ada116b60a9bcd63a9439410a_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from INITIALIZING to FAILED on 192.168.97.6:41975-23ccd7 @ 03-hive-parquet-taskmanager-1.zaphod (dataPort=40685).
org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 's3'.
The scheme is directly supported by Flink through the following plugin(s): flink-s3-fs-hadoop, flink-s3-fs-presto.
Please ensure that each plugin resides within its own subfolder within the plugins directory.
See https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/filesystems/plugins/ for more information.
If you want to use a Hadoop file system for that scheme, please add the scheme to the configuration fs.allowed-fallback-filesystems.
For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
[…]
2024-04-10 14:35:58,836 INFO org.apache.flink.runtime.resourcemanager.slotmanager.FineGrainedSlotManager [] - Clearing resource requirements of job a67f542ab426485698c9db3face73c36
2024-04-10 14:35:58,845 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job insert-into_c_hive.default.t_foo_fs (a67f542ab426485698c9db3face73c36) switched from state RUNNING to FAILING.Copy
|
This is one of my favourite kinds of error message: descriptive, and overly helpful. (My colleague Gunnar Morling also has some more words of wisdom to share on this subject).
The S3 plugin actually ships as part of the Flink distribution; we just need to make it available at runtime by putting it in the plugins folder:
1
2
|
mkdir ./plugins/s3-fs-hadoop && \
cp ./opt/flink-s3-fs-hadoop-1.18.1.jar ./plugins/s3-fs-hadoop/Copy
|
After bouncing the Flink cluster I got a different error from jobmanager when trying the INSERT:
1
2
3
4
5
|
Job insert-into_c_hive.default.t_foo_fs (f1532244c3a97d3308d42c41ab79e092) switched from state FAILING to FAILED.
[…]
java.nio.file.AccessDeniedException: t_foo_fs/part-c4075636-891e-4233-8224-e09064c7c7eb-0-0: org.apache.hadoop.fs.s3a.auth.NoAuthWithAWSException: No AWS Credentials provided by DynamicTemporaryAWSCredentialsProvider TemporaryAWSCredentialsProvider SimpleAWSCredentialsProvider EnvironmentVariable
[…]
com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY))Copy
|
This makes sense—we’re trying to use S3 (well, MinIO) but we’ve not provided any S3 credentials (NoAuthWithAWSException: No AWS Credentials provided). The docs for S3 offer one option—adding them to flink-conf.yaml. We can pass this as a runtime option by setting it in the FLINK_PROPERTIES environment variable as part of the Docker Compose:
1
2
3
4
5
6
7
8
|
jobmanager:
[…]
environment:
- |
FLINK_PROPERTIES=
s3.access.key: admin
s3.secret.key: password
[…]Copy
|
Now the error evolves…
1
2
|
Caused by: java.nio.file.AccessDeniedException: t_foo_fs/part-ddd5011f-9863-432c-9988-50dc1d2628b3-0-0: initiate MultiPartUpload on t_foo_fs/part-ddd5011f-9863-432c-9988-50dc1d2628b3-0-0:
com.amazonaws.services.s3.model.AmazonS3Exception: The AWS Access Key Id you provided does not exist in our records. (Service: Amazon S3; Status Code: 403; Error Code: InvalidAccessKeyId; Request ID: P6ZZ5SJAVR9C38AA; S3 Extended Request ID: 7Nxqk2li47vlMAzllA57vfRmiePcFYFrv9/vHn6Aknv5+V5gwYyLzk9KIwGC9fE/biNzCWTzozI=; Proxy: null), S3 Extended Request ID: 7Nxqk2li47vlMAzllA57vfRmiePcFYFrv9/vHn6Aknv5+V5gwYyLzk9KIwGC9fE/biNzCWTzozI=:InvalidAccessKeyIdCopy
|
This is because we’re trying to use the credentials that we’ve configured for MinIO (the super-secret admin/password 😉) against AWS S3 itself. Because we’re using MinIO we need to tell Flink where to direct its S3 call, and we do this with s3.endpoint:
1
2
3
4
5
6
7
8
9
|
jobmanager:
[…]
environment:
- |
FLINK_PROPERTIES=
s3.access.key: admin
s3.secret.key: password
s3.endpoint: http://minio:9000
[…]Copy
|
At this point things slow down, because the INSERT job runs… and runs…
After two minutes there’s an INFO in the log:
1
|
org.apache.hadoop.fs.s3a.WriteOperationHelper [] - initiate MultiPartUpload on t_foo_fs/part-29594611-b313-4ff6-a0a0-86087ec6f262-0-0: Retried 0: org.apache.hadoop.fs.s3a.AWSClientIOException: initiate MultiPartUpload on t_foo_fs/part-29594611-b313-4ff6-a0a0-86087ec6f262-0-0: com.amazonaws.SdkClientException: Unable to execute HTTP request: warehouse.minio: Unable to execute HTTP request: warehouse.minioCopy
|
and five minutes after submitting the INSERT there’s thisERROR:
1
2
3
4
|
org.apache.hadoop.fs.s3a.WriteOperationHelper [] - initiate MultiPartUpload on t_foo_fs/part-29594611-b313-4ff6-a0a0-86087ec6f262-0-0: Retried 1:
org.apache.hadoop.fs.s3a.AWSClientIOException: initiate MultiPartUpload on t_foo_fs/part-29594611-b313-4ff6-a0a0-86087ec6f262-0-0:
com.amazonaws.SdkClientException: Unable to execute HTTP request: warehouse.minio: Name or service not known:
Unable to execute HTTP request: warehouse.minio: Name or service not knownCopy
|
The problem here looks like some kind of hostname issue. Previously we saw how referencing localhost from a Docker container can be a misconfiguration, but this is something different. warehouse comes from the CREATE TABLE configuration’path’ = ‘s3://warehouse/t_foo_fs/’, whilst minio is the s3.endpoint we just set.
So the S3 endpoint is being picked up, but somehow mangled together with the path of the table. Something I’ve learnt from working with MinIO before is that using path style access can be important. I added this to theFLINK_PROPERTIES:
1
2
3
4
5
6
|
[…]
FLINK_PROPERTIES=
s3.access.key: admin
s3.secret.key: password
s3.endpoint: http://minio:9000
s3.path.style.access: trueCopy
|
and then got yet another different error from the INSERT job:
1
2
3
4
5
6
7
8
9
10
11
12
|
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Stream closed.
at java.base/java.util.concurrent.FutureTask.report(Unknown Source)
at java.base/java.util.concurrent.FutureTask.get(Unknown Source)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.completeProcessing(SourceStreamTask.java:368)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:340)
Caused by: java.io.IOException: Stream closed.
at org.apache.flink.core.fs.RefCountedFileWithStream.requireOpened(RefCountedFileWithStream.java:72)
at org.apache.flink.core.fs.RefCountedFileWithStream.write(RefCountedFileWithStream.java:52)
at org.apache.flink.core.fs.RefCountedBufferingFileStream.flush(RefCountedBufferingFileStream.java:104)
at org.apache.flink.fs.s3.common.writer.S3RecoverableFsDataOutputStream.closeAndUploadPart(S3RecoverableFsDataOutputStream.java:209)
at org.apache.flink.fs.s3.common.writer.S3RecoverableFsDataOutputStream.closeForCommit(S3RecoverableFsDataOutputStream.java:177)
at org.apache.flink.streaming.api.functions.sink.filesystem.OutputStreamBasedPartFileWriter.closeForCommit(OutputStreamBasedPartFileWriter.java:75)Copy
|
This looks like FLINK-33536, and so using the convenience afforded by just writing a blog and not needing to use CSV as the format (which seems to be at the root of the issue) I sidestepped the issue and switched the table to Parquet. I also added the necessary JAR for Parquet in Flink and restarted the Flink cluster before changing the table:
1
2
3
4
5
6
|
CREATE TABLE t_foo_fs (c1 varchar, c2 int)
WITH (
'connector' = 'filesystem',
'path' = 's3://warehouse/t_foo_fs/',
'format' = 'parquet'
);Copy
|
After which …wait… what is this? Behold!
1
2
3
4
5
6
7
|
Flink SQL> SHOW JOBS;
+----------------------------------+-------------------------------------+----------+-------------------------+
| job id | job name | status | start time |
+----------------------------------+-------------------------------------+----------+-------------------------+
| a8ca5cd4c59060ac4d4f0996e426af17 | insert-into_c_hive.default.t_foo_fs | FINISHED | 2024-04-11T09:51:16.904 |
+----------------------------------+-------------------------------------+----------+-------------------------+
1 row in setCopy
|
Success! 🥳
Querying the table proves it…
1
2
3
4
5
6
7
|
Flink SQL> SELECT * FROM t_foo_fs;
+----+--------------------------------+-------------+
| op | c1 | c2 |
+----+--------------------------------+-------------+
| +I | a | 42 |
+----+--------------------------------+-------------+
Received a total of 1 rowCopy
|
To recap then, what was needed to write to S3 (MinIO) from Flink SQL was this:
- Add the S3 plugin to the Flink ./plugins folder:
1
2
|
mkdir ./plugins/s3-fs-hadoop && \
cp ./opt/flink-s3-fs-hadoop-1.18.1.jar ./plugins/s3-fs-hadoop/Copy
|
- Add S3 credentials to Flink configuration. This can be done as environment variables, or added to flink-conf.yaml either directly or by adding to the FLINK_PROPERTIES environment variable, which is what I did
- For MinIO, set the S3 endpoint and enable path-style access. As with the credentials, I set this as part of FLINK_PROPERTIES, which ended up as this:
1
2
3
4
5
6
7
8
9
10
11
|
services:
jobmanager:
[…]
environment:
- |
FLINK_PROPERTIES=
s3.access.key: admin
s3.secret.key: password
s3.endpoint: http://minio:9000
s3.path.style.access: true
[…]Copy
|
Oh - and the CSV bug that I hit is FLINK-33536 and I worked around it by just not using CSV :)
If this blog so far has been some gnarly but reasonable challenges, I’d like to round off with the big end-of-level boss. This brings together JARs, Flink configuration—and the importance of understanding what is running where.
To set the scene: I was doing the same as the above section—I was setting up Flink 1.18 writing files to MinIO (S3 compatible storage), using Hive Metastore for catalog persistence. But instead of Parquet or CSV format, I was writing Iceberg files. Now, that may seem insignificant, but the impact was crucial.

My environment was setup with Docker Compose as before (and available on GitHub):
To my base Flink image I’d added Parquet, S3, Hadoop, Hive, and Iceberg dependencies. Building on my lessons learnt from above, I’ve also added S3 configuration to the FLINK_PROPERTIES environment variable for the Flink cluster containers:
1
2
3
4
5
6
7
8
9
10
11
|
services:
jobmanager:
[…]
environment:
- |
FLINK_PROPERTIES=
s3.access.key: admin
s3.secret.key: password
s3.endpoint: http://minio:9000
s3.path.style.access: true
[…]Copy
|
After bringing the stack up, we’ll start by creating the Iceberg catalog. We use s3a rather than s3 per the Iceberg docs (since this is all done through the Iceberg Flink support)
1
2
3
4
5
|
CREATE CATALOG c_iceberg_hive WITH (
'type' = 'iceberg',
'warehouse' = 's3a://warehouse',
'catalog-type'='hive',
'uri'='thrift://localhost:9083');Copy
|
Now let’s see if there’s a default database provided by the catalog:
1
2
3
4
5
6
|
Flink SQL> USE CATALOG c_iceberg_hive;
[INFO] Execute statement succeed.
Flink SQL> SHOW DATABASES;
[ERROR] Could not execute SQL statement. Reason:
java.net.ConnectException: Connection refused (Connection refused)Copy
|
The Connection refused here is coming from the fact that the SQL Client is trying to reach the Hive MetaStore (HMS) usingthrift://localhost:9083 —but localhost won’t work as that’s local to the SQL Client container.

Instead we need to use the hostname of the HMS in the uri configuration:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
Flink SQL> DROP CATALOG c_iceberg_hive;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.CatalogException: Cannot drop a catalog which is currently in use.
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| c_iceberg_hive |
| default_catalog |
+-----------------+
2 rows in set
Flink SQL> use catalog default_catalog;
[INFO] Execute statement succeed.
Flink SQL> DROP CATALOG c_iceberg_hive;
[INFO] Execute statement succeed.
Flink SQL> CREATE CATALOG c_iceberg_hive WITH (
'type' = 'iceberg',
'warehouse' = 's3a://warehouse',
'catalog-type'='hive',
'uri'='thrift://hms:9083');
[INFO] Execute statement succeed.Copy
|
Now we can see that there is one database, calleddefault:
1
2
3
4
5
6
7
8
9
10
|
Flink SQL> USE CATALOG c_iceberg_hive;
[INFO] Execute statement succeed.
Flink SQL> SHOW DATABASES;
+---------------+
| database name |
+---------------+
| default |
+---------------+
1 row in setCopy
|
Let’s create a new one:
1
2
3
|
Flink SQL> CREATE DATABASE `c_iceberg_hive`.`db01`;
[ERROR] Could not execute SQL statement. Reason:
MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.s3a.S3AFileSystem not found)Copy
|
Fear not! We’ve seen this before, right? Based on my exploration of Flink SQL and JARs previously I thought I’d be well-equipped to deal with this one.ClassNotFound? Piece of cake. Right?

All we need to do is make sure that the Hadoop AWS JAR—that provides the S3AFileSystem class—is present. But if we head over to our Flink containers, it looks like it already is:
1
2
3
4
5
6
7
8
9
10
11
|
flink@jobmanager:~$ tree /opt/flink/lib
/opt/flink/lib
├── aws
│ ├── aws-java-sdk-bundle-1.12.648.jar
│ └── hadoop-aws-3.3.4.jar
[…]
├── hive
│ └── flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar
├── iceberg
│ └── iceberg-flink-runtime-1.18-1.5.0.jar
[…]Copy
|
Using jinfo we can see that the Classpath for the SQL Client shows that the hadoop-aws JAR is present:

We can even double-check that this is indeed the JAR that we want by searching its contents for the class:
1
2
|
$ jar -tf /opt/flink/lib/aws/hadoop-aws-3.3.4.jar|grep S3AFileSystem.class
org/apache/hadoop/fs/s3a/S3AFileSystem.classCopy
|
So what next? Honestly, a looooot of hacking about. Various suggestions from colleagues, Slack groups, Stack Overflow, chatGPT—and of course Google, which included:
- Check Java version
- Check Hadoop dependency version
- RTFM 📖
- Try different JAR version
- Install full Hadoop and set HADOOP_CLASSPATH
- Try a different version of Flink
- RTFM some more 📚
- Turn it off and on again 🤞
- Add iceberg-aws-bundle-1.5.0.jar
- Stand on one leg whilst singing La Marseillaise wearing a silver cross and holding a clove of garlic 🤪
All of these ended up with the same (or different) errors. Whatever I did, Flink just didn’t seem to be able to find the S3 class.
And then…the clouds parted. The sun shone, the angels sang, and one of them named Aleksandr Pilipenko stepped forth on the Apache Flink Slack group and did thus proclaim:
Could this actually originate from hive side? ThriftHiveMetastore seems to me like something outside of Flink Caused by: MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.s3a.S3AFileSystem not found) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$create_database_result$create_database_resultStandardScheme.read(ThriftHiveMetastore.java:39343)
Reader, this fixed it.
Or rather, it put me on the right lines. Because what was happening was that the Hive MetaStore was throwing the error. SQL Client was simply surfacing the error.
When you create a database in Iceberg, not only is there metadata written to the metastore (Hive, in this case), but also the warehouse on S3.
When we created the catalog we told Iceberg where to find the Hive Metastore:‘uri’=‘thrift://hms:9083’. The Hive Metastore then writes additional Iceberg metadata to’warehouse’ = ‘s3a://warehouse’.

You can actually see this if you look at the Hive Metastore log. First there’s the request from Flink’s Iceberg implementation to create the database (note the storage specified ats3a://warehouse/db01.db):
1
|
source:172.24.0.4 create_database: Database(name:db01, description:null, locationUri:s3a://warehouse/db01.db, parameters:{}, ownerName:flink, ownerType:USER, catalogName:hive)Copy
|
followed shortly after by
1
2
3
4
|
ERROR [pool-6-thread-1] metastore.RetryingHMSHandler: MetaException(message:java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.s3a.S3AFileSystem not found)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newMetaException(HiveMetaStore.java:6937)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.create_database(HiveMetaStore.java:1338)
[…]Copy
|
The fix? Add the Hadoop AWS JAR (which includes S3 support) to Hive Metastore (this is not the same as the Flink deployment, which also needs these JARs):
1
2
|
cd /opt/hive-metastore/lib && \
curl https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.3.4/hadoop-aws-3.3.4.jar -OCopy
|
This alone doesn’t quite get us over the hill:
1
2
3
|
Flink SQL> CREATE DATABASE `c_iceberg_hive`.`db01`;
[ERROR] Could not execute SQL statement. Reason:
org.apache.thrift.transport.TTransportExceptionCopy
|
At least this error isn’t such a red-herring; we can see it’s a thrift error, and so nursing the fresh wounds of our S3 JAR escapades above we go straight to check the Hive Metastore log:
1
2
|
WARN [pool-6-thread-1] metastore.ObjectStore: Failed to get database hive.db01, returning NoSuchObjectException
ERROR [pool-6-thread-1] metastore.RetryingHMSHandler: java.lang.NoClassDefFoundError: com/amazonaws/auth/AWSCredentialsProviderCopy
|
AWSCredentialsProvider is included with aws-java-sdk-bundle and after adding that we’re very nearly there:
1
2
3
|
Flink SQL> CREATE DATABASE `c_iceberg_hive`.`db01`;
[ERROR] Could not execute SQL statement. Reason:
MetaException(message:Got exception: java.nio.file.AccessDeniedException s3a://warehouse/db01.db: org.apache.hadoop.fs.s3a.auth.NoAuthWithAWSException: No AWS Credentials provided by TemporaryAWSCredentialsProvider SimpleAWSCredentialsProvider EnvironmentVariableCredentialsProvider IAMInstanceCredentialsProvider : com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY)))Copy
|
Building on what we learnt about S3 access from Flink we know that now we just need to add the S3 credentials and additional configuration needed for MinIO to Hive Metastore. We do this by adding it to the ./conf/hive-site.xml file on the Hive Metastore:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<property>
<name>fs.s3a.access.key</name>
<value>admin</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>password</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://minio:9000</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property> Copy
|
And with that…success.
1
2
3
4
5
6
7
8
9
|
Flink SQL> CREATE CATALOG c_iceberg_hive WITH (
> 'type' = 'iceberg',
> 'warehouse' = 's3a://warehouse',
> 'catalog-type'='hive',
> 'uri'='thrift://hms:9083');
[INFO] Execute statement succeed.
Flink SQL> CREATE DATABASE `c_iceberg_hive`.`db01`;
[INFO] Execute statement succeed.Copy
|
In MinIO we’ve got a object created for the database:
1
2
|
$ mc ls -r minio/warehouse/
[2024-04-11 16:59:06 UTC] 0B STANDARD db01.db/Copy
|
If we create a table within this Iceberg catalog and add some data:
1
2
3
4
|
Flink SQL> CREATE TABLE t_foo_fs (c1 varchar, c2 int);
[ERROR] Could not execute SQL statement. Reason:
com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY))Copy
|
What?! Surely not again. Well not quite. This time the error is coming from the SQL Client itself, as the log (under./log ) shows:
1
2
3
4
5
|
Caused by: org.apache.flink.table.api.TableException: Could not execute CreateTable in path `c_iceberg_hive`.`db01`.`t_foo_fs`
at org.apache.flink.table.catalog.CatalogManager.execute(CatalogManager.java:1296)
at org.apache.flink.table.catalog.CatalogManager.createTable(CatalogManager.java:946)
[…]
Caused by: org.apache.iceberg.exceptions.RuntimeIOException: Failed to create file: s3a://warehouse/db01.db/t_foo_fs/metadata/00000-cec79e1d-1039-45a6-be3a-00a29528ff72.metadata.jsonCopy
|
We’re pretty much on the home straight now. In this case, the SQL Client itself is writing some of the metadata for the table to S3 (MinIO). Other metadata still goes to the Hive Metastore. I have dug into this in more detail in another article.

Whilst we’ve set the S3 configuration for the jobmanager process as part of the FLINK_PROPERTIES (which gets written to flink-conf.yaml at runtime), this configuration doesn’t seem to be used by the SQL Client.
To simplify things, I’m going to move the S3 config away from FLINK_PROPERTIES and specify it in just one place, the ./conf/hive-site.xml on the Flink containers, where it should get used by both the jobmanager, taskmanager—and SQL Client. It’s the same as I added to the Hive Metastore above:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>admin</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>password</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://minio:9000</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
</configuration>Copy
|
For this to be picked up I also needed to add hive-conf-dir as part of the Iceberg catalog configuration:
1
2
3
4
5
6
|
CREATE CATALOG c_iceberg_hive WITH (
'type' = 'iceberg',
'warehouse' = 's3a://warehouse',
'catalog-type'='hive',
'uri'='thrift://hms:9083',
'hive-conf-dir' = './conf');Copy
|
And with that—we’re done:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Flink SQL> CREATE TABLE t_foo_fs (c1 varchar, c2 int);
[INFO] Execute statement succeed.
Flink SQL> INSERT INTO t_foo_fs VALUES ('a',42);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: da7c9c4fc427a0796729a7cf10d05b2b
Flink SQL> SELECT * FROM t_foo_fs;
+----+--------------------------------+-------------+
| op | c1 | c2 |
+----+--------------------------------+-------------+
| +I | a | 42 |
+----+--------------------------------+-------------+
Received a total of 1 rowCopy
|
We’ll wrap up with one more little wrinkle to iron out that’s worth documenting as part of this. As I was testing this, I experimented with a different way of defining an Iceberg table. Instead of creating an Iceberg catalog, and then within that a table, you can define a table and specify it to use the Iceberg connector. It looks like this:
1
2
3
4
5
6
7
8
|
CREATE TABLE iceberg_test WITH (
'connector' = 'iceberg',
'catalog-type'='hive',
'catalog-name'='dev',
'warehouse' = 's3a://warehouse',
'uri'='thrift://hms:9083',
'hive-conf-dir' = './conf')
AS SELECT * FROM (VALUES ('Never Gonna','Give You','Up'));Copy
|
This works great:
1
2
3
4
5
6
7
|
Flink SQL> SELECT * FROM iceberg_test;
+----+--------------------------------+--------------------------------+--------------------------------+
| op | EXPR$0 | EXPR$1 | EXPR$2 |
+----+--------------------------------+--------------------------------+--------------------------------+
| +I | Never Gonna | Give You | Up |
+----+--------------------------------+--------------------------------+--------------------------------+
Received a total of 1 rowCopy
|
But—to get to this point I had to get past this:
1
2
3
4
5
6
7
8
9
|
Flink SQL> CREATE TABLE iceberg_test WITH (
'connector' = 'iceberg',
'catalog-type'='hive',
'catalog-name'='dev',
'warehouse' = 's3a://warehouse',
'hive-conf-dir' = './conf')
AS SELECT * FROM (VALUES ('Never Gonna','Give You','Up'));
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.datanucleus.NucleusContextCopy
|
A ClassNotFoundException which is something we’ve dealt with before. But why wouldn’t this work, if in the same environment things work fine if I create the catalog first and then a table within it?
The answer comes down to how Flink is picking up the Hive configuration. Whilst we’ve defined in the table where to find the hive-site.xml configuration (‘hive-conf-dir’ = ‘./conf’ ), in that file itself it only has the S3 configuration. What it doesn’t have is a value forhive.metastore.uris. The hive docs tell us that if hive.metastore.uris is not set then Flink assumes the metastore is local. For us that means local to the Flink container, which it’s not—and is where the JAR problem comes in.
This didn’t happen when we created the table as part of the catalog because the CREATE CATALOG included ‘uri’=‘thrift://hms:9083’ and thus could find the Hive Metastore. So the lesson here is that the uri must be specified somewhere—either in the DDL (the successful CREATE TABLE iceberg_test above does this), or by adding it to thehive-site.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hms:9083</name>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>admin</value>
</property>
[…]Copy
|
With this added, the CREATE TABLE without a uri configuration also works:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Flink SQL> CREATE TABLE iceberg_test WITH (
'connector' = 'iceberg',
'catalog-type'='hive',
'catalog-name'='dev',
'warehouse' = 's3a://warehouse',
'hive-conf-dir' = './conf')
AS SELECT * FROM (VALUES ('Never Gonna','Give You','Up'));
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: b5588a1e34375f9c4d4d13a6e6f34d99
Flink SQL> SELECT * FROM iceberg_test;
+----+--------------------------------+--------------------------------+--------------------------------+
| op | EXPR$0 | EXPR$1 | EXPR$2 |
+----+--------------------------------+--------------------------------+--------------------------------+
| +I | Never Gonna | Give You | Up |
+----+--------------------------------+--------------------------------+--------------------------------+
Received a total of 1 rowCopy
|
Coming back to theCREATE CATALOG, it can also omit the uri if we’ve specified it in thehive-site.xml, which slims it down to this:
1
2
3
4
5
|
CREATE CATALOG c_iceberg_hive WITH (
'type' = 'iceberg',
'warehouse' = 's3a://warehouse',
'catalog-type'='hive',
'hive-conf-dir' = './conf');
|
😲 Gosh. That’s all rather confusing and down-in-the-weeds, isn’t it?
Well, yes. That is the joy of running a complex distributed system—and one with a venerable history dating back to the Apache Hadoop ecosystem—for yourself.
If you want to spend your time solving your business problems instead of debugging infrastructure, check our Decodable. Our fully-managed platform gives you access to Flink SQL and connectors (including Iceberg) and does all the gnarly stuff for you. Not a JAR or Catalog to worry about in sight! (Of course, you can bring your own Flink JAR jobs if you want to run a custom pipeline, but that’s a point for a different blog post on a different day).
Decodable has a free trial that doesn’t require a credit card to use—so give it a try today.
原文地址:
https://www.decodable.co/blog/flink-sql-misconfiguration-misunderstanding-and-mishaps