OverView
- Flink On K8s Operator 是 Flink 1.15 大版本推出的 Flink On K8s 方案,之前 Flink 社区提供的 Flink Native K8s 方式相对来说使用繁琐并且没有统一的容器管理方案,整体任务管理起来比较复杂。因此社区基于 flink-kubernetes 底层 sdk 开发基于 operator 的 flink k8s 方案,其提供更加成熟的容器管理方案。
核心特点
- 全自动作业生命周期管理
- 运行、挂起和删除应用
- 有状态和无状态的应用程序升级
- 触发和管理 savepoints
- 处理错误,回滚异常的升级
- 支持多版本 flink:v1.13,v1.14,v1.15,v1.16,v1.17
- 多种部署模式支持
- Application Cluster
- Session Cluster
- Session Job
- 支持高可用
- 可扩展的架构
- 更先进的配置管理
- 支持 pod template 增强 pod
- native kubernetes pod 定义
- 分层 (Base/JobManager/TaskManager overrides)
- 作业自动资源分配
- 收集滞后和利用率指标
- 将作业 vertices 缩放到理想的并行度
- 随着负载的变化而上下缩放
Operations
- Operator Mertrics
- 采用 flink 指标系统
- 插件化指标上报器
- 详细资源和 Kubernetes API 访问指标
- 完全自定义 log
- 默认 log 配置
- job 预配置 log
- 基于 Sidecar 的日志转发器
- Flink web ui 和 rest 入口访问
- Helm based installation
- 最新的公共存储库
Quick Start
前置条件
1
2
3
4
5
6
|
# 启动minikube
minikube start --kubernetes-version=v1.24.3
# 安装helm
brew install helm
# 安装k9s,推荐使用k9s来管理k8s pod
brew install k9s
|
- k9s 文档:https://k9scli.io/
部署 operator
1
2
3
4
5
|
# 在Kubernetes集群中安装证书管理器来添加webhook组件(每个Kubernetes集群只需要添加一次):
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
# 添加flink k8s operator helm chart,这里选择1.0.1版本的operator
helm repo add flink-operator-repo160 https://downloads.apache.org/flink/flink-kubernetes-operator-1.6.0/
helm install flink-kubernetes-operator flink-operator-repo160/flink-kubernetes-operator
|
- kubectl get pods查看 flink-kubernetes-operator 是否启动成功
- helm list查看对应 chart 是否安装成功
提交 flink 任务
- 根据官方提供的 yaml 配置提交一个 flink job
1
2
3
4
5
6
7
8
|
# 创建测试flink任务
kubectl create -f https://raw.githubusercontent.com/apache/flink-kubernetes-operator/release-1.6/examples/basic.yaml
# 查看容器日志
kubectl logs -f deploy/basic-example
# 暴露对应任务web port
kubectl port-forward svc/basic-example-rest 8081
# 删除作业
kubectl delete flinkdeployment/basic-example
|
- 通过 localhost:8081 就可以访问 flink web dashboard,basic 文件含义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
apiVersion: flink.apache.org/v1beta1
# 部署类型
kind: FlinkDeployment
metadata:
name: basic-example
spec:
image: flink:1.15
flinkVersion: v1_15
flinkConfiguration:
# flink配置
taskmanager.numberOfTaskSlots: '2'
# flink service用户
serviceAccount: flink
# jm资源配置
jobManager:
resource:
memory: '2048m'
cpu: 1
taskManager:
resource:
memory: '2048m'
cpu: 1
job:
# jar包地址
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
# 并行度
parallelism: 2
upgradeMode: stateless
|
Architecture
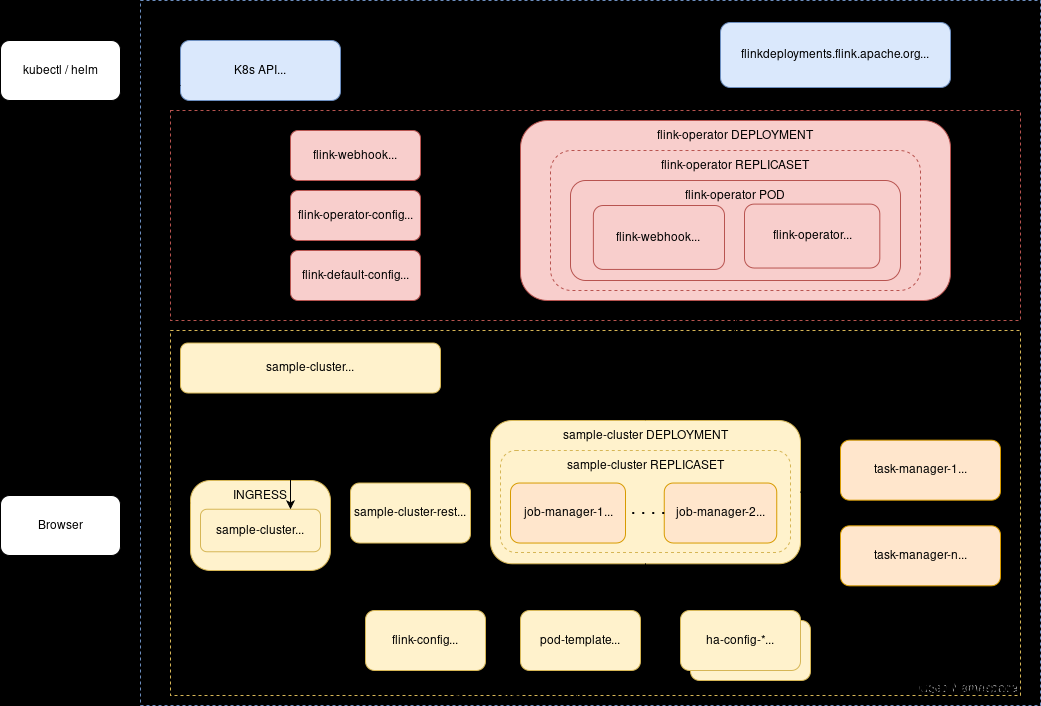 ![[image-20240813133856491.png]]
![[image-20240813133856491.png]]
- Flink Kubernetes Operator (Operator)作为一个控制平台,管理 Apache Flink 应用的整个部署生命周期。Operator可以通过Helm安装在Kubernetes集群上。在大多数生产环境中,它通常部署在指定的namespace中,并在一个或多个托管namespace中控制 Flink 的 deployment。

控制流程

- 用户可以使用 Kubernetes 命令行工具 kubectl 与 operator 进行交互。operator 持续跟踪FlinkDeployment/FlinkSessionJob自定义资源相关的集群事件。当 operator 收到新的资源更新时,它将采取行动将 Kubernetes 集群调整到所需的状态,作为和解循环的一部分。初始循环由以下高级步骤组成:
- 用户通过
kubectl提交一个FlinkDeployment/FlinkSessionJob的自定义资源。
- Operator 观察 flink 资源(如果先前部署)的当前状态
- Operator 校验提交资源的改变
- Operator 协调任何需要的更改并执行升级
- 自定义资源能够在任何时间应用于集群中。Operator 不断地根据期望状态进行调整,直到当前状态变为期望状态。在 Operator 中,所有生命周期管理操作都使用这个非常简单的原则来实现。
Flink 资源生命周期
- Operator 管理者 flink 资源的生命周期,Flink 资源的生命周期各个阶段如下图:

- CREATED : The resource was created in Kubernetes but not yet handled by the operator
- SUSPENDED : The (job) resource has been suspended
- UPGRADING : The resource is suspended before upgrading to a new spec
- DEPLOYED : The resource is deployed/submitted to Kubernetes, but it’s not yet considered to be stable and might be rolled back in the future
- STABLE : The resource deployment is considered to be stable and won’t be rolled back
- ROLLING_BACK : The resource is being rolled back to the last stable spec
- ROLLED_BACK : The resource is deployed with the last stable spec
- FAILED : The job terminally failed
Admission Control
- 除了编译的准入插件,一个名为
Flink Kubernetes Operator Webhook (Webhook)的自定义准入插件可以作为扩展启动并作为 Webhook 运行。
- Webhook 遵循 Kubernetes 的原则,特别是动态准入控制。
- 当使用 Helm 将 Operator 安装在 Kubernetes 集群上时,默认会部署它。
- Webhook 默认使用 TLS 协议进行通信。当 keystore 文件发生更改时,它会自动加载/重新加载 keystore 文件,并提供以下端点:
Custom Resource
- Flink Kubernetes 操作员面向用户的核心 API 是 FlinkDeployment 和 FlinkSessionJob 自定义资源(CR)。自定义资源是 k8s api 的扩展和定义一个新的对象类型。FlinkDeployment CR(自定义资源)定义一个 Flink Application 和 Session 集群 deployments。FlinkSessionJob 的 CR 定义一个 session 任务在 Session 集群并且每个 session 集群可以运行多个 FlinkSessionJob。
- 一但 Flink K8s Operator 被安装和运行在 k8s 环境,它将会持续的监听 FlinkDeployment 和 FlinkSessionJob 对象,以检测新的 CR 和对现有 CR 的更改。
- 俩种 CR 类型,FlinkDeployment 和 FlinkSessionJob
- Flink 应用的管理通过 FlinkDeployment
- 由 FlinkDeployment 管理的空 Flink Session+由 FlinkSessionJobs 管理的多个作业。对会话任务的操作是相互独立的。
FlinkDeployment
1
2
3
4
5
6
7
|
apiVersion: flink.apache.org/v1beta1
# 部署类型
kind: FlinkDeployment
metadata:
namespace: namespace-of-my-deployment
name: my-deployment
spec: // Deployment specs of your Flink Session/Application
|
- 查看 FlinkDeployment 具体 yaml 配置
FlinkDeployment spec 描述
- image:Docker 用于运行 Flink 作业和任务管理器进程
- flinkVersion:flink 镜像的版本(v1_13,v1_14,v1_15)
- serviceAccount:flink pod 使用的 k8s 账户
- taskManager,jobManager:job 和 task 管理 pod 资源的描述(cpu、memory 等)
- flinkConfiguration:flink 配置的字典,例如 ck 和 ha 配置
- job:任务相关描述
Application Deployments
- jarURI:任务 jar 包路径
- parallelism: 任务并行度
- upgradeMode: 作业的更新模式(stateless/savepoint/last-state)
- state:任务的描述状态(运行/挂起)
创建一个新的 namespace 和 serviceaccount
1
2
3
4
5
6
7
8
|
# 创建namespace
kubectl create namespace flink-operator
# 创建serviceaccount
kubectl create serviceaccount flink -n flink-operator
# 赋予权限
kubectl create clusterrolebinding flink-role-binding-flink-operator_flink \
--clusterrole=edit --serviceaccount=flink-operator:flink
clusterrolebinding.rbac.authorization.k8s.io/flink-role-binding-flink-operator_flink created
|
FlinkDeployment 模式 flink job yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink-operator
name: flink-deployment-test
spec:
image: flink:1.15
flinkVersion: v1_15
flinkConfiguration:
taskmanager.numberOfTaskSlots: '2'
serviceAccount: flink
jobManager:
resource:
memory: '2048m'
cpu: 1
taskManager:
resource:
memory: '2048m'
cpu: 1
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
upgradeMode: stateless
state: running
|
启动对应 flink 任务
1
2
3
4
5
6
7
8
9
10
|
kubectl apply -f your-deployment.yaml
# 转发端口
kubectl port-forward svc/flink-deployment-test-rest 8081 -n flink-operator
## 如果遇到以下错误标识端口占用
Unable to listen on port 8081: Listeners failed to create with the following errors: [unable to create listener: Error listen tcp4 127.0.0.1:8081: bind: address already in use unable to create listener: Error listen tcp6 [::1]:8081: bind: address already in use]
error: unable to listen on any of the requested ports: [{8081 8081}]
## 通过lsof kill对应应用
lsof -i :8080
kill -9 pid
|
- port-forward 作用:https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/port-forward-access-application-cluster/
FlinkSessionJob
- 整体的 yaml 文件的结构类似于 FlinkDeployment
1
2
3
4
5
6
7
8
9
10
|
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: basic-session-job-example
spec:
deploymentName: basic-session-cluster
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.15.1/flink-examples-streaming_2.12-1.15.1-TopSpeedWindowing.jar
parallelism: 4
upgradeMode: stateless
|
FlinkSessionJob spec 描述
- flink session 的 jar 可以来着远程的资源,可以从不同的系统获取任务 jar,例如支持从 hadoop 文件系统拉取 jar 需要改造原始 flink operator 打包新的镜像,如下:
1
2
3
|
FROM apache/flink-kubernetes-operator
ENV FLINK_PLUGINS_DIR=/opt/flink/plugins
COPY flink-hadoop-fs-1.15-SNAPSHOT.jar $FLINK_PLUGINS_DIR/hadoop-fs/
|
限制
- FlinkSessionJob 目前还不支持
LastState的升级模式
FlinkSessionJob Quick Start
启动一个 Session Cluster
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: basic-session-deployment-only-example
spec:
image: flink:1.15
flinkVersion: v1_15
flinkConfiguration:
taskmanager.numberOfTaskSlots: '2'
serviceAccount: flink
jobManager:
resource:
memory: '2048m'
cpu: 1
taskManager:
resource:
memory: '2048m'
cpu: 1
|
1
|
kubectl apply -f basic-session-deployment-only-example.yaml
|
添加任务至 basic-session-deployment-only-example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: basic-session-job-only-example
spec:
# 部署的deployment名称
deploymentName: basic-session-deployment-only-example
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.15.0/flink-examples-streaming_2.12-1.15.0-TopSpeedWindowing.jar
parallelism: 4
upgradeMode: stateless
|
1
|
kubectl apply -f basic-session-job-only-example.yaml
|
任务管理
Flink 生命周期管理
- flink operator 的核心特性是如何去管理一个 Flink 应用程序的完整生命周期。
- 运行、挂起和删除应用
- 有状态和无状态的应用更新方式
- 触发和管理 savepoint
- 处理错误,回滚损坏的升级
- 以上特点都可以通过 JobSpec 来控制
启动、挂起和删除应用
1
|
kubectl delete flinkdeployment/flinksessionjob my-deployment
|
有状态和无状态应用升级
- operator 可以停止当前正在运行的作业(除非已经挂起或者 redeploy),并使用上次运行有状态应用程序时保留的最新 spec 和状态重新部署它。
- 通过 JobSpec 的
upgradeMode进行设置,支持以下值
- stateless: 可以通过空状态来升级无状态应用
- savepoint: 使用 savepoint 来升级。
- **last-state: **在任何应用程序状态下(即使作业失败)进行快速升级,都不需要健康的作业,因为它总是使用最后检查点信息。当 HA 元数据丢失时,可能需要手动恢复。
|
Stateless |
Last State |
Savepoint |
| 必需配置 |
无 |
Checkpointing & Kubernetes HA Enabled |
Checkpoint/Savepoint directory defined |
| Job 状态要求 |
无 |
HA 元数据可用 |
Job 运行状态 |
| 暂停机制 |
Cancel / Delete |
Delete Flink deployment (keep HA metadata) |
通过 Savepoint 取消任务 |
| 恢复机制 |
从空状态部署 |
使用 HA 元数据恢复最新 ck |
Restore From savepoint |
| 生产使用 |
不推荐 |
推荐 |
推荐 |
last-state yaml 配置
- last-state模式仅支持
FlinkDeployment类型作业
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: basic-checkpoint-ha-example
spec:
image: flink:1.15
flinkVersion: v1_15
flinkConfiguration:
taskmanager.numberOfTaskSlots: '2'
state.savepoints.dir: file:///flink-data/savepoints
state.checkpoints.dir: file:///flink-data/checkpoints
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: file:///flink-data/ha
serviceAccount: flink
jobManager:
resource:
memory: '2048m'
cpu: 1
taskManager:
resource:
memory: '2048m'
cpu: 1
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /flink-data
name: flink-volume
volumes:
- name: flink-volume
hostPath:
# directory location on host
path: /tmp/flink
# this field is optional
type: Directory
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
upgradeMode: last-state
state: running
|
应用重启没有 spec 变化
- 在某些情况下,用户只是希望重启 Flink 部署来处理一些临时问题。可以通过 restartNonce 来配置重启次数
1
2
3
|
spec:
...
restartNonce: 123
|
savepoint 管理
手动 savepoint 触发
- 通过
savepointTriggerNonce来手动控制 savepoint 触发,改变savepointTriggerNonce的值将会触发一个新的 savepoint
1
2
3
|
job:
...
savepointTriggerNonce: 123
|
定期 savepoint 触发
1
2
3
|
flinkConfiguration:
...
kubernetes.operator.periodic.savepoint.interval: 6h
|
- 不能保证定期保存点的及时执行,因为不健康的作业状态或其他干扰用户操作可能会延迟它们的执行。
savepoint history
- operator 可以动态跟踪由升级或手动保存点操作触发的保存点历史。
1
2
3
4
|
flinkConfiguration:
...
kubernetes.operator.savepoint.history.max.age: 24 h
kubernetes.operator.savepoint.history.max.count: 5
|
kubernetes.operator.savepoint.cleanup.enabled: false可以关闭 savepoint 清理能力
Recovery of missing job deployments
- 当启用 Kubernetes HA 时,operator 可以在用户或某些外部进程意外删除 Flink 集群部署的情况下恢复它。可以通过设置
kubernetes.operator.jm-deployment-recovery.enabled在配置中关闭部署恢复。启用为 false,但是建议保持该设置为默认的 true 值。
不健康 job deployment 的重启
- 当开启 HA 时,当 Flink 集群部署被认为不健康时,operator 可以重新启动它。通过设置
kubernetes.operator.cluster.health-check为 true 启用不健康的部署重启(默认为 false)。要使此功能发挥作用,必须启用kubernetes.operator.jm-deployment-recovery.enabled。
- 目前以下俩种情况被认为是不健康的 job:
- Flink job 在
kubernetes.operator.cluster.health-check.restart的时间窗口内。窗口(默认:2 分钟)重启次数超过kubernetes.operator.cluster.health-check.restarts.threshold配置,默认 64。
cluster.health-check.checkpoint-progress设置为 true,并且 Flink 的成功检查点计数在kubernetes.operator.cluster.health-check.checkpoint-progress的时间窗口内没有变化。窗口(默认为 5 分钟)。
重新启动失败的 job deployment
- operator 可以重新启动失败的 Flink 作业,当作业主任务能够重新配置作业以处理这些故障时,当
kubernetes.operator.job.restart.faile设置为 true 时,当作业状态设置为FAILED时,kubernetes opeartor 将删除当前作业,并使用最新成功的检查点重新部署作业。
手动恢复
- 手动恢复作业步骤:
- 在配置 ck/sp 的路径找到最新的 ck/sp
- 删除
FlinkDeployment资源应用
- 校验是否存在需要恢复的 savepoint,确认
FlinkDeployment应用是否完全删除
- 修改
FlinkDeploymentyaml 配置中的 jobSpec,指定initialSavepointPath位置为需要恢复的 savepoint 路径
- 重新创建
FlinkDeployment
Pod Template
- operator 的 CRD 提供
flinkConfiguration和podTemplate配置,pod template 允许自定义 Flink 作业和任务管理器 pod,例如指定卷安装,临时存储,sidecar 容器等。
- operator 会合并 job manager 和 task manger 的通用和特定模板,以下为 pod template demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: default
name: pod-template-example
spec:
image: flink:1.17
flinkVersion: v1_17
flinkConfiguration:
taskmanager.numberOfTaskSlots: '2'
serviceAccount: flink
podTemplate:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
containers:
# Do not change the main container name
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/log
name: flink-logs
# Sample sidecar container
- name: fluentbit
image: fluent/fluent-bit:1.8.12-debug
command:
[
'sh',
'-c',
'/fluent-bit/bin/fluent-bit -i tail -p path=/flink-logs/*.log -p multiline.parser=java -o stdout'
]
volumeMounts:
- mountPath: /flink-logs
name: flink-logs
volumes:
- name: flink-logs
emptyDir: {}
jobManager:
resource:
memory: '2048m'
cpu: 1
taskManager:
resource:
memory: '2048m'
cpu: 1
podTemplate:
apiVersion: v1
kind: Pod
metadata:
name: task-manager-pod-template
spec:
initContainers:
# Sample sidecar container
- name: busybox
image: busybox:1.35.0
command: ['sh', '-c', 'echo hello from task manager']
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
|
Autoscaler
- 作业自动扩缩容功能可以收集 Flink 作业的各种指标,并自动缩放单个作业 vertexes(chained operator groups),以消除反压力,满足用户设定的利用率目标。通过调整作业 vertexes 级别的并行度(与作业并行度相反),我们可以有效地自动扩展复杂和异构的流应用程序。
- 关键特性如下:
- 更好的集群资源利用率和更低的运维成本
- 自动并行调优,甚至复杂的流管道
- 自动适应不断变化的负载模式
- 用于性能调试的详细利用率指标
概览
- 自动扩缩容依赖于 Flink 度量系统为单个任务提供的度量,指标直接从 Flink 作业查询,收集的度量指标如下:
- 每个 source 的 backlog 信息
- source 数据的传入数据速率(例如:records/sec 写入 kafka 的速度)
- 每个 job 的 vertex 每秒处理的记录数
- 每个 job 的 vertex 每秒的繁忙时间(目前的利用率)
- 该算法从 source 开始,递归地计算 pipeline 中每个 operator 所需的处理能力(目标数据率)。在 source vertices,目标数据速率等于传入数据速率(来自 Kafka 主题)。
- 对于下游算子,计算目标数据速率为输入(上游)算子沿着处理图中给定边缘的输出数据速率的总和。

- 用户可以配置管道中 operator 的目标利用率,例如将所有 operators 的繁忙度保持在 60% - 80%之间。然后,autoscaler 找到一个并行配置,使所有操作的输出速率与其所有下游操作的输入速率在目标利用率上匹配。
- 如下图所示,可以看出来 autoscaler 如何影响 pipeline:

- 类似地,当负载减少时,autoscaler 会调整单个 opeartor 的并行度水平,以匹配当前随时间变化的速率。

autoscaler 配置
Flink 1.18 和 autoscaler 支持
- 即将发布的 Flink 1.18 版本通过新的资源需求 rest 端点对扩展操作的速度进行了非常显著的改进。这允许 autoscaler 在不执行完整作业升级周期的情况下就地缩放顶点。
- 要尝试此实验性功能,请使用当前可用的 Flink 1.18 快照基础映像来构建应用程序 docker 映像。此外,确保在
FlinkDeployment yaml 中将Flink version设置为v1_18,并启用该特性所需的自适应调度器。
1
|
jobmanager.scheduler: adaptive
|
Job 的要求和限制
要求
- Autoscaler 目前只适用于 Flink 1.17 和更高版本的 Flink 镜像,或者在将以下修复程序反向移植到 1.15/1.16 Flink image 后:
限制
- 默认情况下,Autoscaler 可用于处理图中的所有 job vertices。
- source scaling 要求 source 符合一下特性:
- 在当前状态下,Autoscaler 与 Kafka source 最适配,因为 kafka source 暴露了所有标准化的指标。当使用 Kafka 时,还带来了一些额外的好处,比如自动检测和限制源最大并行度与 Kafka 分区的数量。
配置指南
- 关键配置
- 作业和每个算子的最大并行度
- 稳定性和指标收集间隔
- 目标利用率和灵活的边界
- 目标追赶持续时间和重新启动时间
自动缩放器还支持被动/仅指标模式,它只收集和评估与缩放相关的性能指标,但不会触发任何作业升级。这可以用来获得对模块的信任,而不会对正在运行的应用程序产生任何影响。
要禁用 autoscaler 操作,设置:kubernetes.operator.job.autoscaler.scaling.enabled: “false”
作业和每个 operator 的最大并行度
- 在计算缩放的并行度时,autoscaler 总是考虑每个 job vertex 的最大并行度设置,以确保它不会引入不必要的数据倾斜。计算的并行度将始终是最大并行度数的除数。
- 因此,为了确保灵活的缩放,建议选择具有许多除数的最大并行度设置,而不是依赖于 Flink 提供的默认值。通过
pipeline.max-parallelism配置设置作业的最大并行度
- 最大并行度的一些好数字是:120、180、240、360、720 等。也可以在每个 opeartor 级别上设置 maxParallelism,如果我们想要避免缩放某些 sources/sinks 超过一定数量,会很有作用。
稳定和指标收集间隔
- autoscaler 通过查看由
kubernetes.operator.job.autoscaler.metrics.window定义的收集时间窗口中的平均指标。此窗口的大小决定了小的波动将如何影响自动缩放器。窗口越大,我们得到的平滑和稳定性就越好,但我们对突然的负载变化的反应可能会更慢。我们建议您尝试将其设置在3-60分钟之间。
- 为了允许作业在恢复后稳定,用户可以通过设置
kubernetes.operator.job.autoscaler.stabilization.interval来配置一个稳定窗口。在此期间,不会收集任何指标,也不会采取任何缩放操作。
目标利用率和灵活边界
-
为了提供稳定的作业性能和对负载波动的一些缓冲,autoscaler 允许用户为作业设置目标利用率级别(kubernetes.operator.job.autoscaler.target.utilization)。0.6 的目标意味着 job vertex 的利用率/负载为 60%。
-
一般来说,不建议将目标利用率设置为接近 100%,因为在大多数实际系统中,当我们达到容量限制时,性能通常会下降。
除了利用率目标之外,我们还可以设置一个利用率边界,作为额外的缓冲区,以避免在负载波动时立即进行扩展。设置kubernetes.operator.job.autoscaler.target.utilization.boundary为 0.2 表示允许在触发缩放操作之前与目标利用率有 20%的偏差。
目标追赶持续时间和重启时间
- 在做出扩展决策时,opeartor 需要考虑到在扩展操作期间创建的积压所需的额外容量。额外容量的大小由以下 2 个配置自动确定:
kubernetes.operator.job.autoscaler.restart.time:通常重启应用程序所需的时间kubernetes.operator.job.autoscaler.catch-up.duration:预计到作业的时间将在扩展后赶上
- 未来,autoscaler 可能能够自动确定重新启动时间,但目标追赶持续时间取决于用户的 SLO。通过降低追赶持续时间,自动缩放器将不得不为缩放操作保留更多的额外容量。我们建议根据你的实际目标来设定,比如 10 分钟、30 分钟、60 分钟等等。
基础配置案例
1
2
3
4
5
6
7
8
9
10
11
12
|
---
flinkVersion: v1_17
flinkConfiguration:
kubernetes.operator.job.autoscaler.enabled: 'true'
kubernetes.operator.job.autoscaler.stabilization.interval: 1m
kubernetes.operator.job.autoscaler.metrics.window: 5m
kubernetes.operator.job.autoscaler.target.utilization: '0.6'
kubernetes.operator.job.autoscaler.target.utilization.boundary: '0.2'
kubernetes.operator.job.autoscaler.restart.time: 2m
kubernetes.operator.job.autoscaler.catch-up.duration: 5m
pipeline.max-parallelism: '720'
|
高级配置参数
Metrics
- opeartor 上报有关已评估的 Flink 作业指标的详细作业顶点级别指标,这些指标被收集并用于 autoscaler 决策。
- 利用率、输入率、目标率指标
- 扩展阈值
- 并行度和最大并行度随时间变化
- 这些指标在 Kubernetes 操作员资源指标组下报告:
1
|
[resource_prefix].Autoscaler.[jobVertexID].[ScalingMetric].Current/Average
|