1.Rook 介绍
Rook 是一个开源的云原生存储编排器,为 Ceph 存储提供平台、框架和支持,使其能够与云原生环境进行本地集成。 Rook 是云原生计算基金会(CNCF)的一个项目,从 2018 年成为孵化项目,并在 2020 年成为毕业项目。
Ceph是一个分布式存储系统,提供文件(file)、块(block)和对象存储(object storage),并在大规模生产集群中部署。
使用 Rook 可以自动部署和管理 Ceph,提供自我管理、自我扩展和自我修复的存储服务。Rook Operator 通过 Kubernetes Resources 来部署(deploy)、配置(configure)、供应(provision)、扩展(scale)、升级(upgrade)和监控(monitor)Ceph。
通过 Rook Operator,在一个 Kubernetes 集群中启动 Ceph 就像执行几个 kubectl 命令一样简单。
为什么使用 rook
为什么要使用 Rook 呢?
让我们先来看一下 Ceph 官方提供的部署工具发展过程。Ceph 官方在部署 Ceph 系统时提供了几个工具,其中包括 ceph-deploy、ceph-ansible 和 cephadm:
- ceph-deploy是 Ceph 早期版本中推荐的部署工具和集群管理工具。它能够简化部署过程,自动配置和安装 Ceph 节点,并提供一些管理操作的便捷功能。当前 ceph-deploy 已经不再被维护,而且它还没有在比 Ceph 14 (Nautilus)更新的 Ceph 版本上进行测试,不支持 RHEL8、CentOS 8 或更新版本的操作系统。
- ceph-ansible是一个基于 Ansible 的 Ceph 部署工具,它提供了一套 Ansible playbook 和 roles,用于自动化配置和部署 Ceph 集群。ceph-ansible 使用 Ansible 的特性,可以根据用户的需求进行高度定制化的部署,同时支持多种操作系统和 Ceph 版本。虽然当前 ceph-ansible 项目还在被维护,但在其项目首页上已经直接给了通知,推荐迁移到 cephadm。
- cephadm是 Ceph 官方从 Ceph 15(Octopus)中引入的部署工具,它是一个基于容器的管理工具,使用 Ceph Orchestrator 模块来管理 Ceph 集群。cephadm 提供了一种更简单和灵活的方式来部署和管理 Ceph 集群,它使用容器技术来隔离和管理 Ceph 组件,可以方便地进行版本升级和配置更改。
从 Ceph 官方部署工具的发展来看,已经从早期和中期的 ceph-deploy 和 ceph-ansible 提供的裸机二进制包部署方案发展到了 cephadm 的容器部署方式。也说明了使用容器来部署和管理 Ceph 集群的方案已经变得成熟。
Rook 虽然也是通过容器来部署和管理 Ceph 集群,但它在构建在 Kubernetes 上,下面是 Rook 相对于 cephadm 的一些优势和特点:
- 简化部署和管理:Rook 提供了一种基于 Kubernetes 的部署模型,利用 Kubernetes 的强大功能来简化存储集群的部署和管理。相比之下,cephadm 需要在主机上安装和配置容器运行时,并使用 cephadm 工具来管理 Ceph 集群。
- 自动化和可伸缩性:Rook 利用 Kubernetes 的自动化和可伸缩性能力,可以轻松地管理和扩展存储集群。它可以自动处理节点故障、动态扩展存储容量,并提供了灵活的存储资源调度和分配策略。
- 多存储后端支持:Rook 不仅支持 Ceph 存储后端,还提供了对其他存储解决方案的支持,如 EdgeFS、NFS、CockroachDB 等。这使得 Rook 成为一个更加多样化和灵活的存储管理工具,可以根据具体需求选择适合的存储后端。
- 基于声明性配置:Rook 使用 Kubernetes 的声明性配置模型,通过 YAML 文件定义存储集群的期望状态。这种模型可以简化管理任务,确保存储集群始终处于所需的状态,并允许跟踪和回滚配置更改。
- 社区支持和生态系统:Rook 拥有一个活跃的开源社区,有大量的文档、示例和社区支持可供参考。此外,Rook 还与 Kubernetes 生态系统紧密集成。
选择使用 cephadm,还是 Rook 取决于具体的使用场景和需求。cephadm 提供了更直接的 Ceph 集群管理方式,而 Rook 在 Kubernetes 环境下提供了更全面的存储解决方案,并与 Kubernetes 紧密集成。
接下来我们将体验安装 Rook 这个云原生存储编排平台,为 Kubernetes 集群提供高可用、持久化的 Ceph 存储。
2.部署
2.1 系统需求和前置准备
本文档使用的 Rook 是 v1.11.8,Ceph(Quincy) 17.2.6。
当前 Rook 支持 Kubernetes v1.21 或更高版本。
Rook 发布包支持的架构包括amd64 / x86_64和arm64。
在部署 Rook 之前,要检查 Kubernetes 集群是否准备好使用 Rook,请查看以下先决条件:
要配置 Ceph 存储集群,至少需要以下其中一种本地存储:
- 原始设备(Raw devices)(无分区或格式化文件系统)
- 原始分区(Raw partitions)(无格式化文件系统)
- LVM 逻辑卷(无格式化文件系统)
- 以块模式(block mode)在存储类(storage class)中提供的持久卷
这里使用的 Kubernetes 集群如下:
1
2
3
4
5
6
|
k-m1 Ready control-plane 461d v1.24.2
k-n1 Ready <none> 461d v1.24.2
k-n2 Ready <none> 461d v1.24.2
k-n3 Ready <none> 461d v1.24.2
k-n4 Ready <none> 352d v1.24.2
k-n5 Ready <none> 352d v1.24.2
|
假设我们要在 node4, node5, node6 这 3 个节点部署 Ceph。为了控制将 Ceph 集群各个组件调度到哪些 Kubernetes 节点上,预先为相关的 K8S 节点打上 Tag, 这里假设我们将 Ceph 的 mon,osd,mrg 等调度到 node4, node5, node6 上,下面给这 3 个节点打上role=ceph的 label,并加上dedicated=ceph:NoSchedule的 taint。
1
2
3
4
5
6
|
kubectl label node k-n1 role=ceph
kubectl label node k-n2 role=ceph
kubectl label node k-n3 role=ceph
kubectl taint nodes k-n1 dedicated=ceph:NoSchedule
kubectl taint nodes k-n2 dedicated=ceph:NoSchedule
kubectl taint nodes k-n3 dedicated=ceph:NoSchedule
|
当前 node4~node6 的磁盘和分区信息如下:
1
2
3
4
5
6
7
8
9
10
11
|
fdisk -l
Disk /dev/vda: 100 GiB, 107374182400 bytes, 209715200 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x53af6437
Device Boot Start End Sectors Size Id Type
/dev/vda1 2048 4194303 4192256 2G e W95 FAT16 (LBA)
/dev/vda2 4194304 83886079 79691776 38G 83 Linux
|
根据输出中的信息,磁盘 /dev/vda 的总容量为 100 GiB,其中已经使用了 40 GiB(38 GiB + 2 GiB)。因此,根据这些信息,还有剩余的 60GiB 空间可供使用。我们这里的情况适用于前面三种类型的本地存储中的原始分区(Raw partitions)(无格式化文件系统).
分别在 node4~node6 三个节点上,创建新的分区/dev/vda3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
fdisk /dev/vda
# 省略分区过程...
fdisk -l
Disk /dev/vda: 100 GiB, 107374182400 bytes, 209715200 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x53af6437
Device Boot Start End Sectors Size Id Type
/dev/vda1 2048 4194303 4192256 2G e W95 FAT16 (LBA)
/dev/vda2 4194304 83886079 79691776 38G 83 Linux
/dev/vda3 83886080 209715199 125829120 60G 83 Linux
|
关于容器运行时的配置,这里的 Kubernetes 集群的容器运行时是 Containerd。当前 Containerd 官方的 systemd 配置模板https://raw.githubusercontent.com/containerd/containerd/main/containerd.service中的LimitNOFILE=infinity,如果是使用这个containerd.service,后边在使用rook启动Ceph集群时,Mon组件会有问题,会出现ms_dispatch进程的cpu一直是100%,Rook社区有两个ISSUES ISSUE 11253和ISSUE 10110讨论了这个问题,需要将LimitNOFILE设置一个合适的值,我这里设置的是1048576。
2.2 部署 Rook Operator
注: 这里只有 node4~node6 这 3 个节点, Ceph 集群的各个组件混部在这 3 个节点上,对于更多节点的生产级别配置,可以对 label 做更精细化的配置,例如node-role.kubernetes.io/ceph-mon=ceph-mon等等。
我们将通过使用Rook Helm Chart来部署 rook ceph operator。
Rook 目前将 Ceph Operator 的构建版本发布到发布(release)和主要(master)通道。发布通道是 Rook 的最新稳定版本。
1
2
|
helm repo add rook-release https://charts.rook.io/release
helm install --create-namespace --namespace rook-ceph rook-ceph rook-release/rook-ceph -f values.yaml
|
关于 values.yaml 中配置的内容,可以根据文档https://github.com/rook/rook/blob/master/deploy/charts/rook-ceph-cluster/values.yaml中的内容按需定制。
以下是当前我所定制的内容,主要配置了在部署 Rook Operator 和 Ceph 时使用私有的镜像仓库地址,以及调度相关的配置。
https://github.com/rook/rook/blob/master/deploy/examples/images.txt这个地址里面有部署Rook Operator 和 Ceph 所需的所有容器镜像,可以根据需要预先同步到我们的私有镜像仓库中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
image:
pullPolicy: IfNotPresent
repository: registry.frognew.com/library/rook/ceph
tag: v1.11.8
imagePullSecrets:
- name: regsecret
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
provisionerNodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
provisionerTolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
pluginNodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
pluginTolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
csi:
cephcsi:
# -- Ceph CSI image
# @default -- `quay.io/cephcsi/cephcsi:v3.8.0`
image: registry.frognew.com/gcr/quay.io/cephcsi/cephcsi:v3.8.0
registrar:
# -- Kubernetes CSI registrar image
# @default -- `registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.7.0`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.7.0
provisioner:
# -- Kubernetes CSI provisioner image
# @default -- `registry.k8s.io/sig-storage/csi-provisioner:v3.4.0`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-provisioner:v3.4.0
snapshotter:
# -- Kubernetes CSI snapshotter image
# @default -- `registry.k8s.io/sig-storage/csi-snapshotter:v6.2.1`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-snapshotter:v6.2.1
attacher:
# -- Kubernetes CSI Attacher image
# @default -- `registry.k8s.io/sig-storage/csi-attacher:v4.1.0`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-attacher:v4.1.0
resizer:
# -- Kubernetes CSI resizer image
# @default -- `registry.k8s.io/sig-storage/csi-resizer:v1.7.0`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-resizer:v1.7.0
|
部署完成后,确认 rook-ceph-operator 的正常启动:
1
2
3
|
kubectl get pods -n rook-ceph -l "app=rook-ceph-operator"
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-8f4d9cd47-vk2wn 1/1 Running 0 4m9s
|
2.3 集群环境
Rook 文档侧重于在各种环境中启动 Rook。在创建 Ceph 集群时,可以考虑在以下的示例集群清单基础上做定制:
有关更多详细信息,请参阅Ceph 的示例配置。
Rook Ceph Operator 已经部署完成并正常运行,我们可以创建 Ceph 集群了,这里选择的是cluster.yaml。
2.4 创建集群
基于cluster.yaml创建并定制我们自己的 cluster.yaml,以下是只包含我对这个 cluster.yaml 的修改内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
...
spec:
cephVersion:
image: registry.frognew.com/gcr/quay.io/ceph/ceph:v17.2.6
...
dashboard:
enabled: true
ssl: false
...
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
podAffinity:
podAntiAffinity:
topologySpreadConstraints:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
...
|
1
|
kubectl create -f cluster.yaml
|
通过查看rook-ceph命名空间中的 pod,验证集群是否正在运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-ccx2t 2/2 Running 0 70m
csi-cephfsplugin-provisioner-5975dbc847-9fmjz 5/5 Running 0 70m
csi-cephfsplugin-provisioner-5975dbc847-p5rsp 5/5 Running 0 70m
csi-cephfsplugin-qsdh7 2/2 Running 0 13m
csi-cephfsplugin-trqtz 2/2 Running 0 13m
csi-rbdplugin-b296t 2/2 Running 0 13m
csi-rbdplugin-provisioner-5866f96769-7mspx 5/5 Running 0 70m
csi-rbdplugin-provisioner-5866f96769-jtjqz 5/5 Running 0 70m
csi-rbdplugin-sqwtr 2/2 Running 0 13m
csi-rbdplugin-vzb8h 2/2 Running 0 70m
rook-ceph-crashcollector-node4-7d8c99bb7b-thcb8 1/1 Running 0 70m
rook-ceph-crashcollector-node5-54f44699cf-2qd56 1/1 Running 0 14m
rook-ceph-crashcollector-node6-79c7bfc46-g7rmc 1/1 Running 0 14m
rook-ceph-mgr-a-6b84cf75f4-4vsw7 3/3 Running 0 71m
rook-ceph-mgr-b-76f7ffb4f-sqglf 3/3 Running 0 70m
rook-ceph-mon-a-7f6c678998-b9gsg 1/2 Running 0 72m
rook-ceph-mon-b-798544c8c6-g4jml 1/2 Running 0 71m
rook-ceph-mon-c-5f769c966c-66zmj 2/2 Running 0 71m
rook-ceph-operator-75bc9447c6-hfqhl 1/1 Running 0 15m
rook-ceph-osd-0-55ffc5446b-xlz68 2/2 Running 0 26m
rook-ceph-osd-1-57688f847-pvm8l 2/2 Running 0 14m
rook-ceph-osd-2-7dc6686bfb-jps57 2/2 Running 0 14m
rook-ceph-osd-prepare-node4-dxg8d 0/1 Completed 0 15m
rook-ceph-osd-prepare-node5-xnvbv 0/1 Completed 0 15m
rook-ceph-osd-prepare-node6-5xvdz 0/1 Completed 0 14m
|
osd pod 的数量取决于集群中的节点数量和配置的设备数量。对于上述默认的 cluster.yaml,将为每个节点上找到的每个可用设备创建一个 OSD。
创建过程如果遇到问题可以查看rook-ceph-operator的 Pod 的日志。
如需重新运行rook-ceph-osd-prepare-<nodename> Job,扫描可用本地存储添加 OSD,可以执行以下命令:
1
2
3
4
|
# 删除旧的job
kubectl get job -n rook-ceph | awk '{system("kubectl delete job "$1" -n rook-ceph")}'
# 重启operator
kubectl rollout restart deploy rook-ceph-operator -n rook-ceph
|
每个节点上的 osd 能否添加成功,要注意查看rook-ceph-osd-prepare-<nodename> Job 对应 Pod 的日志。
2.5 验证集群状态
为了验证集群处于健康状态, 需要Rook 工具箱。
1
2
3
4
|
kubectl apply -f https://raw.githubusercontent.com/rook/rook/release-1.11/deploy/examples/toolbox.yaml
kubectl get po -n rook-ceph | grep rook-ceph-tools
rook-ceph-tools-68b98695bb-gh76t 1/1 Running 0 23s
|
连接到工具箱,并运行ceph status 命令:
1
|
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash
|
以下是健康状态的验证要点:
- 所有的 monitor (mon) 节点应该处于 quorum(一致性)状态。
- 一个管理器 (mgr) 节点应该处于活动状态。
- 至少有三个 OSD 节点应该处于上线并可用状态。
如果健康状态不是 HEALTH_OK,则应该调查警告或错误的原因。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
ceph status
cluster:
id: 919b1901-4943-4a88-88cc-d7bbb134a5f1
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 116s)
mgr: a(active, since 41s), standbys: b
osd: 3 osds: 3 up (since 2m), 3 in (since 5m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 62 MiB used, 180 GiB / 180 GiB avail
pgs: 1 active+clean
|
从输出可以看出集群状态一切正常,集群中部署了 3 个 mon, 2 个 mgr, 3 个 osd。
查看一下当前集群中的存储池:
1
2
|
ceph osd lspools
1 .mgr
|
可以看到当前集群中只有一个名称为.mgr的存储池。这表示在这个 Ceph 集群中只创建了默认的管理池(mgr pool),这是一个特殊的池,用于存储管理和监控相关的数据。
3.使用存储
Ceph 提供三种类型的存储接口: 块存储(Block)、共享文件系统(Shared Filesystem)、对象存储(Object)。
下面演示对于使用 Rook 部署和管理的 Ceph 集群,如何使用这三种存储。
通过 Rook 使用 Ceph 提供的三种存储类型以及它们的用途如下:
- 块存储(Block)适用于为单个 Pod 提供读写一致性(RWO)的存储
- CephFS 共享文件系统(Shared Filesystem)适用于多个 Pod 之间共享读写(RWX)的存储
- 对象存储(Object)提供了一个可通过内部或外部的 Kubernetes 集群的 S3 端点访问的存储
3.1 块存储(Block)
块存储允许单个 Pod 挂载存储。本指南介绍了如何使用 Rook 启用的持久卷,在 Kubernetes 上创建一个简单的多层 Web 应用程序。
3.1.1 RBD 存储供给
在 Rook 可以提供存储之前,需要创建 StorageClass 和 CephBlockPool CR。这将使 Kubernetes 在提供持久卷时与 Rook 进行交互操作。
这个示例需要每个节点至少有 1 个 OSD,并且每个 OSD 需要位于 3 个不同的节点上。每个 OSD 必须位于不同的节点上,因为 failureDomain 被设置为 host,并且 replicated.size 被设置为 3。
创建下面的storageclass.yaml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
# clusterID is the namespace where the rook cluster is running
clusterID: rook-ceph
# Ceph pool into which the RBD image shall be created
pool: replicapool
# (optional) mapOptions is a comma-separated list of map options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# mapOptions: lock_on_read,queue_depth=1024
# (optional) unmapOptions is a comma-separated list of unmap options.
# For krbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd/#kernel-rbd-krbd-options
# For nbd options refer
# https://docs.ceph.com/docs/master/man/8/rbd-nbd/#options
# unmapOptions: force
# RBD image format. Defaults to "2".
imageFormat: "2"
# RBD image features
# Available for imageFormat: "2". Older releases of CSI RBD
# support only the `layering` feature. The Linux kernel (KRBD) supports the
# full complement of features as of 5.4
# `layering` alone corresponds to Ceph's bitfield value of "2" ;
# `layering` + `fast-diff` + `object-map` + `deep-flatten` + `exclusive-lock` together
# correspond to Ceph's OR'd bitfield value of "63". Here we use
# a symbolic, comma-separated format:
# For 5.4 or later kernels:
#imageFeatures: layering,fast-diff,object-map,deep-flatten,exclusive-lock
# For 5.3 or earlier kernels:
imageFeatures: layering
# The secrets contain Ceph admin credentials.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
# Specify the filesystem type of the volume. If not specified, csi-provisioner
# will set default as `ext4`. Note that `xfs` is not recommended due to potential deadlock
# in hyperconverged settings where the volume is mounted on the same node as the osds.
csi.storage.k8s.io/fstype: ext4
# Delete the rbd volume when a PVC is deleted
reclaimPolicy: Delete
# Optional, if you want to add dynamic resize for PVC.
# For now only ext3, ext4, xfs resize support provided, like in Kubernetes itself.
allowVolumeExpansion: true
|
这个 storageclass.yaml 文件中包含了 StorageClass rook-ceph-block和 CephBlockPool replicapool的定义。
如果你在一个名为"rook-ceph"以外的命名空间中部署了 Rook Operator,请将该文件中的provisioner中的前缀更改为与你使用的命名空间匹配。例如,如果 Rook Operator 在命名空间"my-namespace"中运行,则 provisioner 的值应为my-namespace.rbd.csi.ceph.com。
接下来创建这个 StorageClass 和 CephBlockPool:
1
2
3
|
kubectl create -f storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created
|
根据 Kubernetes 的规定,在使用"Retain"回收策略时,任何由 PersistentVolume 支持的 Ceph RBD 镜像将在 PersistentVolume 被删除后继续存在。这些 Ceph RBD 镜像需要使用rbd rm命令手动清理。
上面在创建名称为replicapool的 CephBlockPool 资源时,会自动在 Ceph 集群中创建名称为replicapool的存储池。这个操作是由 Ceph Operator 完成的,如果查看发现没有创建这个存储池,可以通过查看 Ceph Operator 的日志进行问题定位。
1
2
3
|
ceph osd lspools
1 .mgr
2 replicapool
|
上面命令的输出说明已经创建了存储池replicapool。
3.1.2 使用存储: WordPress 示例
我们创建了一个示例应用程序,使用经由 Rook 提供的块存储,其中包括经由 Rook 提供的的 WordPress 和 MySQL 应用程序。这些应用程序都将使用 Rook 提供的块存储卷(block volumes)。
从 rook 源码的deploy/examples文件夹启动 MySQL 和 WordPress,因为这里部署的 Ceph 集群总容量只有 180GB, 所以这里将mysql.yaml和wordpress.yaml中 PVC 中配置的容量都调整为 5Gi 后再执行下面的命令:
1
2
|
kubectl create -f mysql.yaml
kubectl create -f wordpress.yaml
|
这两个应用程序都会创建一个块存储卷并将其挂载到各自的 Pod 上。通过运行以下命令来查看 Kubernetes 的 PVC(卷声明):
1
2
3
4
|
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-ae507859-6367-447b-b8e0-cf9316780938 5Gi RWO rook-ceph-block 7s
wp-pv-claim Bound pvc-32801000-6399-4422-bf49-11d22d0481da 5Gi RWO
|
查看一下创建的持久卷:
1
2
3
4
|
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-32801000-6399-4422-bf49-11d22d0481da 5Gi RWO Delete Bound default/wp-pv-claim rook-ceph-block 7m53s
pvc-ae507859-6367-447b-b8e0-cf9316780938 5Gi RWO Delete Bound default/mysql-pv-claim rook-ceph-block 7m54s
|
查看其中一个持久化卷的具体信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
kubectl describe pv pvc-32801000-6399-4422-bf49-11d22d0481da
Name: pvc-32801000-6399-4422-bf49-11d22d0481da
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: rook-ceph.rbd.csi.ceph.com
volume.kubernetes.io/provisioner-deletion-secret-name: rook-csi-rbd-provisioner
volume.kubernetes.io/provisioner-deletion-secret-namespace: rook-ceph
Finalizers: [kubernetes.io/pv-protection]
StorageClass: rook-ceph-block
Status: Bound
Claim: default/wp-pv-claim
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 5Gi
Node Affinity: <none>
Message:
Source:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: rook-ceph.rbd.csi.ceph.com
FSType: ext4
VolumeHandle: 0001-0009-rook-ceph-0000000000000002-f9915a86-312c-469a-835c-f03484c444dc
ReadOnly: false
VolumeAttributes: clusterID=rook-ceph
imageFeatures=layering
imageFormat=2
imageName=csi-vol-f9915a86-312c-469a-835c-f03484c444dc
journalPool=replicapool
pool=replicapool
storage.kubernetes.io/csiProvisionerIdentity=1687233028841-8081-rook-ceph.rbd.csi.ceph.com
Events: <none>
|
查看一下存储池 replicapool 中的 rbd 镜像:
1
2
3
|
rbd ls -p replicapool
csi-vol-23a9cc04-abf1-4a64-a022-ba613c978b11
csi-vol-f9915a86-312c-469a-835c-f03484c444dc
|
3.2 CephFS 共享文件系统
CephFS 文件系统存储(也称为共享文件系统)可以从多个 Pod 中以读/写权限挂载。这对于可以使用共享文件系统进行集群化的应用程序可能非常有用。
Ceph 从自 Pacific 版本(Ceph 16)开始,支持多个文件系统。
3.2.1 创建 CephFilesystem
通过在CephFilesystem CRD 中指定元数据池(metadata pool)、数据池(data pools)和元数据服务(metadata server)的所需设置来创建文件系统。在这里,我们创建的是 3 个副本的元数据池和 3 个副本的单个数据池。有关更多选项,请参阅创建共享文件系统的文档。
创建下面的 filesystem.yaml 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
dataPools:
- name: replicated
replicated:
size: 3
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
|
Rook Ceph Operator 将创建启动服务所需的所有池和其他资源。这可能需要一些时间来完成。
1
|
kubectl create -f filesystem.yaml
|
要确认文件系统已配置完成,请等待 mds Pod 启动:
1
2
3
4
|
kubectl -n rook-ceph get pod -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-b8c7dc4dd-72spj 2/2 Running 0 9m27s
rook-ceph-mds-myfs-b-6f487b5c7c-m9sf2 2/2 Running 0 9m23s
|
要查看文件系统的详细状态,进入 Rook toolbox 中,使用ceph status查看, 确认输出中包含 MDS 服务的状态。在这个示例中,有一个处于活动状态的 MDS 实例,并且还有一个处于备用 MDS 实例,以防发生故障切换。
1
2
3
4
5
6
7
8
|
ceph -s
cluster:
id: 919b1901-4943-4a88-88cc-d7bbb134a5f1
health: HEALTH_OK
services:
...
mds: 1/1 daemons up, 1 hot standby
...
|
使用ceph osd lspools查看,确认创建了myfs-metadata和myfs-replicated的存储池。
1
2
3
4
5
|
ceph osd lspools
1 .mgr
2 replicapool
3 myfs-metadata
4 myfs-replicated
|
3.2.2 CephFS 存储供给
在 Rook 开始提供 CephFS 存储之前,需要基于文件系统创建一个 StorageClass。这对于 Kubernetes 与 CSI 驱动程序进行交互以创建持久卷是必需的。
将以下存储类定义保存为 storageclass.yaml 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.cephfs.csi.ceph.com
parameters:
# clusterID is the namespace where the rook cluster is running
# If you change this namespace, also change the namespace below where the secret namespaces are defined
clusterID: rook-ceph
# CephFS filesystem name into which the volume shall be created
fsName: myfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: myfs-replicated
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
reclaimPolicy: Delete
|
如果你将 Rook Operator 部署在了一个与"rook-ceph"不同的命名空间中,请修改 provisioner 中的前缀以匹配你使用的命名空间。例如,如果 Rook Operator 运行在"rook-op"命名空间中,那么 provisioner 的值应该是rook-op.rbd.csi.ceph.com。
创建存储类:
1
|
kubectl create -f storageclass.yaml
|
3.2.3 关于配额
CephFS CSI 驱动程序使用配额来强制执行所请求的 PVC 大小。只有较新的 Linux 内核支持 CephFS 配额,至少是 4.17 版本的内核。
3.2.4 使用存储: 多个 Pod 挂载
创建下面的 busybox.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: busybox-data-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
storageClassName: rook-cephfs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
replicas: 2
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox-container
image: busybox:stable-glibc
command: ["sleep", "3600"]
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: busybox-data-pvc
|
创建这个 busybox 的 deployment 和 pvc:
1
2
3
|
kubectl apply -f busybox.yaml
persistentvolumeclaim/busybox-data-pvc created
deployment.apps/busybox created
|
查看创建的 PVC 和自动供给的 PV:
1
2
3
4
5
6
7
|
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
busybox-data-pvc Bound pvc-d212bea0-6c7f-45e6-979c-20108ba67b9e 2Gi RWX rook-cephfs 77s
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-d212bea0-6c7f-45e6-979c-20108ba67b9e 2Gi RWX Delete Bound default/busybox-data-pvc rook-cephfs 96s
|
查看 PV 的的具体信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
kubectl describe pv pvc-d212bea0-6c7f-45e6-979c-20108ba67b9e
Name: pvc-d212bea0-6c7f-45e6-979c-20108ba67b9e
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: rook-ceph.cephfs.csi.ceph.com
volume.kubernetes.io/provisioner-deletion-secret-name: rook-csi-cephfs-provisioner
volume.kubernetes.io/provisioner-deletion-secret-namespace: rook-ceph
Finalizers: [kubernetes.io/pv-protection]
StorageClass: rook-cephfs
Status: Bound
Claim: default/busybox-data-pvc
Reclaim Policy: Delete
Access Modes: RWX
VolumeMode: Filesystem
Capacity: 2Gi
Node Affinity: <none>
Message:
Source:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: rook-ceph.cephfs.csi.ceph.com
FSType:
VolumeHandle: 0001-0009-rook-ceph-0000000000000001-7ab26692-0138-4894-b7e1-17ec1a109466
ReadOnly: false
VolumeAttributes: clusterID=rook-ceph
fsName=myfs
pool=myfs-replicated
storage.kubernetes.io/csiProvisionerIdentity=1687233030423-8081-rook-ceph.cephfs.csi.ceph.com
subvolumeName=csi-vol-7ab26692-0138-4894-b7e1-17ec1a109466
subvolumePath=/volumes/csi/csi-vol-7ab26692-0138-4894-b7e1-17ec1a109466/74db7b35-9936-4cf9-b223-4c1f669c2009
Events: <none>
|
可以看到持久化卷挂载是 CephFS 实例 myfs 中的/volumes/csi/csi-vol-7ab26692-0138-4894-b7e1-17ec1a109466/74db7b35-9936-4cf9-b223-4c1f669c2009。
3.3 对象存储
对象存储为应用程序提供了一个使用 S3 API 存储和获取数据的接口。
3.3.1 配置一个 Object Store
Rook 具有在 Kubernetes 中部署对象存储或连接到外部 RGW 服务的能力。通常情况下,对象存储将由 Rook 在本地进行配置。或者,如果你有一个现有的带有 Rados Gateways 的 Ceph 集群,请参阅external section 文档以从 Rook 中使用它。
创建本地的 Object Store
以下示例将创建一个 CephObjectStore,该对象存储在集群中启动 RGW 服务,并提供 S3 API。
注意: 这个示例至少需要 3 个 bluestore OSD,每个 OSD 位于不同的节点上。OSDs 必须位于不同的节点上,因为failureDomain设置为 host,并且erasureCoded块设置要求至少有 3 个不同的 OSD(2 个dataChunks + 1 个codingChunks)。
请参阅对象存储 CRD 文档,以获取有关 CephObjectStore 可用设置的更多详细信息。
创建如下的 object.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
apiVersion: ceph.rook.io/v1
kind: CephObjectStore
metadata:
name: my-store
namespace: rook-ceph
spec:
metadataPool:
failureDomain: host
replicated:
size: 3
dataPool:
failureDomain: host
erasureCoded:
dataChunks: 2
codingChunks: 1
preservePoolsOnDelete: true
gateway:
sslCertificateRef:
port: 80
# securePort: 443
instances: 1
|
创建这个 CephObjectStore:
1
2
|
kubectl create -f object.yaml
cephobjectstore.ceph.rook.io/my-store created
|
创建 CephObjectStore 后,Rook Ceph Operator 将创建所有必要的池和其他资源以启动服务。这可能需要几分钟来完成。
Rook Ceph Operator 会在 Ceph 集群中创建名称为my-store.rgw.*的多个存储池。
1
2
3
4
5
6
7
8
9
10
11
|
ceph osd lspools
1 .mgr
2 replicapool
3 myfs-metadata
4 myfs-replicated
5 my-store.rgw.control
6 my-store.rgw.meta
7 my-store.rgw.log
8 my-store.rgw.buckets.index
9 my-store.rgw.buckets.non-ec
10 my-store.rgw.otp
|
要确认对象存储已配置完成,请等待 RGW pod 启动:
1
2
3
|
kubectl -n rook-ceph get pod -l app=rook-ceph-rgw
NAME READY STATUS RESTARTS AGE
rook-ceph-rgw-my-store-a-547dc8d7cb-lkbsd 2/2 Running 0 2m17s
|
最后再查看一下 ceph 集群的状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
ceph -s
cluster:
id: 919b1901-4943-4a88-88cc-d7bbb134a5f1
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 3h)
mgr: a(active, since 3h), standbys: b
mds: 1/1 daemons up, 1 hot standby
osd: 3 osds: 3 up (since 3h), 3 in (since 3h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 12 pools, 178 pgs
objects: 242 objects, 506 KiB
usage: 123 MiB used, 180 GiB / 180 GiB avail
pgs: 178 active+clean
io:
client: 639 B/s rd, 1 op/s rd, 0 op/s wr
progress:
|
3.3.2 创建一个 Bucket
现在对象存储已经配置好了,接下来我们需要创建一个存储桶,以便客户端可以读取和写入对象。可以通过定义存储类来创建存储桶,类似于块和文件存储的模式。首先,定义一个存储类,允许对象客户端创建存储桶。存储类定义了对象存储系统、存储桶保留策略和其他管理员所需的属性。将以下内容保存为storageclass-bucket-delete.yaml(由于采用了 DELETE 的回收策略,示例被命名为 storageclass-bucket-delete.yaml)。
1
2
3
4
5
6
7
8
9
10
|
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-bucket
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: rook-ceph.ceph.rook.io/bucket
reclaimPolicy: Delete
parameters:
objectStoreName: my-store
objectStoreNamespace: rook-ceph
|
如果 Rook Operator 部署在rook-ceph之外的命名空间中,需要更改 provisioner 中的前缀以匹配使用的命名空间。例如,如果 Rook Operator 在my-namespace命名空间中运行,则 provisioner 的值应为my-namespace.ceph.rook.io/bucket。
1
2
|
kubectl create -f storageclass-bucket-delete.yaml
storageclass.storage.k8s.io/rook-ceph-bucket created
|
根据这个存储类,现在可以通过创建对象存储桶声明 Object Bucket Claim(OBC)来请求一个存储桶。当创建 OBC 时,Rook bucket provisioner 将创建一个新的存储桶。请注意,OBC 引用了上面创建的存储类。将以下内容保存为object-bucket-claim-delete.yaml(示例命名为 delete,因为使用了 Delete 的回收策略):
1
2
3
4
5
6
7
|
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ceph-bucket
spec:
generateBucketName: ceph-bkt
storageClassName: rook-ceph-bucket
|
创建这个 OBC:
1
|
kubectl create -f object-bucket-claim-delete.yaml
|
OBC 创建成功后,Rook Ceph Operator 将创建存储桶,并生成其他文件以实现对存储桶的访问。将以与 OBC 相同的名称和在相同的命名空间中创建一个密钥和 ConfigMap。密钥包含应用程序 Pod 用于访问存储桶的凭据。ConfigMap 包含存储桶端点信息,也会被 Pod 使用。有关 CephObjectBucketClaims 的更多详细信息,请参阅对象存储桶声明文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
kubectl get cm
NAME DATA AGE
ceph-bucket 5 105s
kubectl get cm ceph-bucket -o yaml
apiVersion: v1
data:
BUCKET_HOST: rook-ceph-rgw-my-store.rook-ceph.svc
BUCKET_NAME: ceph-bkt-2752d0dc-7eee-4f6e-b133-b1b4acfa7109
BUCKET_PORT: "80"
BUCKET_REGION: ""
BUCKET_SUBREGION: ""
kind: ConfigMap
metadata:
name: ceph-bucket
namespace: default
kubectl get secret
NAME TYPE DATA AGE
ceph-bucket Opaque 2 118s
kubectl get secret ceph-bucket -o yaml
apiVersion: v1
data:
AWS_ACCESS_KEY_ID: OTc3NFo2QzBaVEFVM0xYTUQ0OFU=
AWS_SECRET_ACCESS_KEY: RVRlTDVORGE2RHRKdUxMYnh0YUlGUFBCbG5EclZodGhtbDZDVUhVNg==
kind: Secret
metadata:
name: ceph-bucket
namespace: default
type: Opaque
|
3.3.3 客户端连接
以下命令从 Secret 和 ConfigMap 中提取关键信息:
1
2
3
4
5
6
7
8
9
10
11
12
|
#config-map, secret, OBC will part of default if no specific name space mentioned
export AWS_HOST=$(kubectl -n default get cm ceph-bucket -o jsonpath='{.data.BUCKET_HOST}')
export PORT=$(kubectl -n default get cm ceph-bucket -o jsonpath='{.data.BUCKET_PORT}')
export BUCKET_NAME=$(kubectl -n default get cm ceph-bucket -o jsonpath='{.data.BUCKET_NAME}')
export AWS_ACCESS_KEY_ID=$(kubectl -n default get secret ceph-bucket -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 --decode)
export AWS_SECRET_ACCESS_KEY=$(kubectl -n default get secret ceph-bucket -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 --decode)
echo $AWS_HOST
echo $PORT
echo $BUCKET_NAME
echo $AWS_ACCESS_KEY_ID
echo $AWS_SECRET_ACCESS_KEY
|
3.3.4 使用 s5cmd 工具访问对象存储
Rook 的文档中提到了在工具箱(toolbox)Pod 中使用 s5cmd 工具测试 CephObjectStore,但当前的 toolbox 中并不包含 s5cmd,s5cmd 不可用,在 github 上已经有一个ISSUE 12227提出了这个问题。
因为这里的 k8s 集群使用的 calico 网络,可以直接在 Node 节点上使用 svc ip,这里简单起见直接在 K8S 集群的控制节点上安装 s5cmd 命令行工具。
接下来配置 s5cmd 工具访问对象存储凭据:
1
2
3
4
5
6
7
8
9
|
1export AWS_ACCESS_KEY_ID=$(kubectl -n default get secret ceph-bucket -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 --decode)
2export AWS_SECRET_ACCESS_KEY=$(kubectl -n default get secret ceph-bucket -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 --decode)
3
4mkdir ~/.aws
5cat > ~/.aws/credentials << EOF
6[default]
7aws_access_key_id = ${AWS_ACCESS_KEY_ID}
8aws_secret_access_key = ${AWS_SECRET_ACCESS_KEY}
9EOF
|
查看 rook-ceph-rgw-my-store 这个 Service 的 IP:
1
2
3
|
1k get svc rook-ceph-rgw-my-store -n rook-ceph
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3rook-ceph-rgw-my-store ClusterIP 10.98.136.218 <none> 80/TCP 54m
|
使用 s5cmd 访问存储桶,列出当前凭据可以访问的所有桶:
1
2
|
1s5cmd --endpoint-url http://10.98.136.218 ls
2s3://ceph-bkt-2752d0dc-7eee-4f6e-b133-b1b4acfa7109
|
上传下载文件:
1
2
3
4
5
|
1echo "Hello Rook" > /tmp/rookObj
2s5cmd --endpoint-url http://10.98.136.218 cp /tmp/rookObj s3://ceph-bkt-2752d0dc-7eee-4f6e-b133-b1b4acfa7109
3
4s5cmd --endpoint-url http://10.98.136.218 cp s3://ceph-bkt-2752d0dc-7eee-4f6e-b133-b1b4acfa7109/rookObj /tmp/rookObj-download
5cat /tmp/rookObj-download
|
注这里使用 Service IP 访问 rook-ceph-rgw-my-store 只是为了测试。生产环境中如果从 K8S 集群内访问的话,使用 Service 的 DNS 名称,如果从集群外部访问推荐使用 Ingress 将其暴露到集群外部。
4.Ceph Dashboard
通过使用 Ceph Dashboard 可以查看集群的状态。使用 Rook 部署的 Ceph 集群已经默认启用了 Ceph Dashboard。
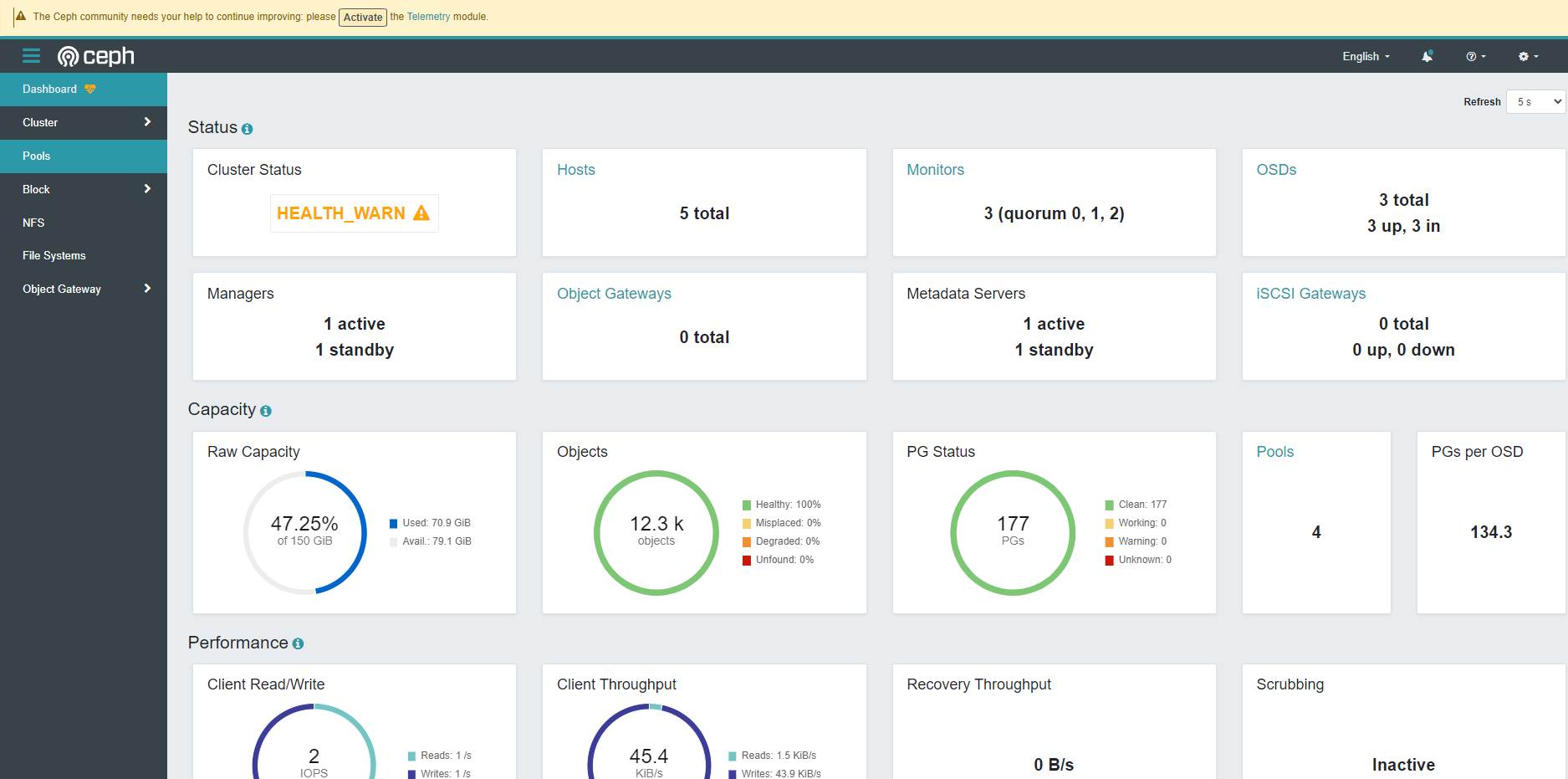
rook-ceph-mgr-dashboard 是其在 Kubernetes 集群中的 Service:
1
2
3
|
kubectl get svc rook-ceph-mgr-dashboard -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 10.96.238.32 <none> 7000/TCP 8h
|
可通过 Ingress 或创建一个 NodePort 的 Service dashboard-external-http将其暴露的 Kubernetes 集群外部。
Ceph Dashboard admin 用户的命名可以通过下面的命令查看:
1
|
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
|
参考