etcd 部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
docker run \
-d \
--name etcd \
-p 2379:2379 \
-p 2380:2380 \
--volume=/var/etcd:/etcd-data \
quay.io/coreos/etcd:v3.4.13 \
/usr/local/bin/etcd \
--name my-etcd-1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster my-etcd-1=http://0.0.0.0:2380 \
--initial-cluster-token my-etcd-token \
--initial-cluster-state new \
--auto-compaction-retention 1 \
--auto-compaction-mode periodic
|
启动后进入 docker,备份命令如下
1
2
3
4
5
6
7
8
9
|
etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.1.61:2379" snapshot save snapshot.db
# etcdctl snapshot save snapshot.db
{"level":"info","ts":1698376972.3008873,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"snapshot.db.part"}
{"level":"info","ts":"2023-10-27T03:22:52.317Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1698376972.3222704,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2023-10-27T03:22:59.237Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1698376981.0142808,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"130 MB","took":8.712725359}
{"level":"info","ts":1698376981.0144396,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"snapshot.db"}
Snapshot saved at snapshot.db
|
查看 snapshot 的内容
1
2
3
4
5
6
|
# etcdctl --endpoints localhost:2379 snapshot status snapshot.db --write-out=table
+---------+-----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+---------+-----------+------------+------------+
| 62d1abe | 119498428 | 3669 | 130 MB |
+---------+-----------+------------+------------+
|
数据恢复
1
2
3
4
|
etcdctl snapshot restore snapshot.db --name my-etcd-1 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster my-etcd-1=http://0.0.0.0:2380 \
--initial-cluster-token my-etcd-token
|
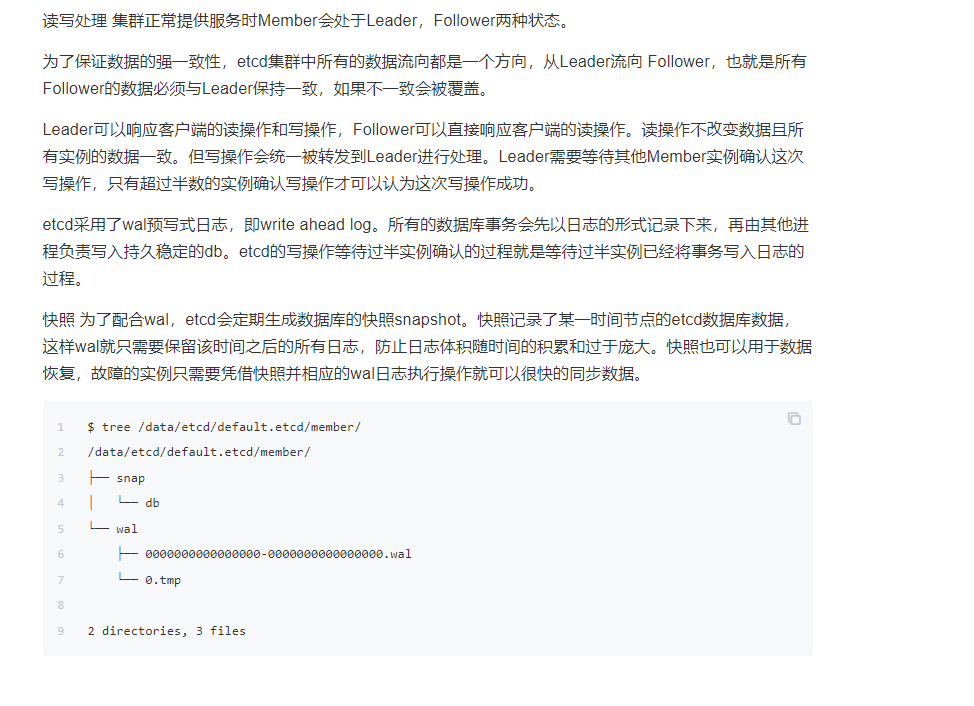
恢复的目录如下为 my-etcd-1.etcd,查看恢复的目录
1
2
3
4
5
6
7
8
9
10
|
[root@k01 default.etcd]# tree ./member/
./member/
├── snap
│ ├── 0000000000000001-0000000000000003.snap
│ └── db
└── wal
├── 0000000000000000-0000000000000000.wal
└── 0.tmp
2 directories, 4 files
|
恢复完目录后,要用的新的目录来启动 etcd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
docker run \
-d \
--name etcd \
-p 2379:2379 \
-p 2380:2380 \
--volume=/var/etcd:/etcd-data \
quay.io/coreos/etcd:v3.4.13 \
/usr/local/bin/etcd \
--name my-etcd-1 \
--data-dir /my-etcd-1.etcd \ #修改这个即可
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster my-etcd-1=http://0.0.0.0:2380 \
--initial-cluster-token my-etcd-token \
--initial-cluster-state new \
--auto-compaction-retention 1 \
--auto-compaction-mode periodic
|
重启后看看数据大小
1
2
3
4
5
6
|
# etcdctl endpoint status --write-out=table
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 127.0.0.1:2379 | 1baabbaa70b63cdf | 3.4.13 | 130 MB | true | false | 2 | 8 | 8 | |
+----------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
|
查看所有 key
1
2
3
|
etcdctl --endpoints=${ETCD_ENDPOINTS} get / --prefix --keys-only
etcdctl get / --prefix --keys-only
#可以输出很多目录
|
监听 etcd 服务的
1
2
3
4
5
6
7
8
9
|
$ curl -L http://localhost:2379/metrics
# HELP etcd_debugging_mvcc_keys_total Total number of keys.
# TYPE etcd_debugging_mvcc_keys_total gauge
etcd_debugging_mvcc_keys_total 0
# HELP etcd_debugging_mvcc_pending_events_total Total number of pending events to be sent.
# TYPE etcd_debugging_mvcc_pending_events_total gauge
etcd_debugging_mvcc_pending_events_total 0
...
|
1.1. 空间配额
在 etcd 中空间配额确保集群以可靠方式运作。没有空间配额, etcd 可能会收到低性能的困扰,如果键空间增长的过度的巨大,或者可能简单的超过存储空间,导致不可预测的集群行为。如果键空间的任何成员的后端数据库超过了空间配额, etcd 发起集群范围的警告,让集群进入维护模式,仅接收键的读取和删除。在键空间释放足够的空间之后,警告可以被解除,而集群将恢复正常运作。
默认,etcd 设置适合大多数应用的保守的空间配额,但是它可以在命令行中设置,单位为字节:
1
2
|
# 设置非常小的 16MB 配额
$ etcd --quota-backend-bytes=16777216
|
空间配额可以用循环触发:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 消耗空间
$ while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | etcdctl put key || break; done
...
Error: rpc error: code = 8 desc = etcdserver: mvcc: database space exceeded
# 确认配额空间被超过
$ etcdctl --write-out=table endpoint status
+----------------+------------------+-----------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------+------------------+-----------+---------+-----------+-----------+------------+
| 127.0.0.1:2379 | bf9071f4639c75cc | 2.3.0+git | 18 MB | true | 2 | 3332 |
+----------------+------------------+-----------+---------+-----------+-----------+------------+
# 确认警告已发起
$ etcdctl alarm list
memberID:13803658152347727308 alarm:NOSPACE
|
删除多读的键空间将把集群带回配额限制,因此警告能被接触:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 获取当前修订版本
$ etcdctl --endpoints=:2379 endpoint status
[{"Endpoint":"127.0.0.1:2379","Status":{"header":{"cluster_id":8925027824743593106,"member_id":13803658152347727308,"revision":1516,"raft_term":2},"version":"2.3.0+git","dbSize":17973248,"leader":13803658152347727308,"raftIndex":6359,"raftTerm":2}}]
# 压缩所有旧有修订版本
$ etdctl compact 1516
compacted revision 1516
# 反碎片化过度空间
$ etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]
# 解除警告
$ etcdctl alarm disarm
memberID:13803658152347727308 alarm:NOSPACE
# 测试put被再度容许
$ etdctl put newkey 123
OK
|
1.2. 存储告警
如果出现了相关的磁盘报警,也说明磁盘空间不够用了,此时要么调整参数,要么进行碎片整理,一般这种错误为日志中出现 etcdserver: mvcc: database space exceeded 这种日志,同时进行 alarm 查看的时候,有 NOSPACE.
1
2
|
$ etcdctl alarm list
memberID:13803658152347727308 alarm:NOSPACE
|
数据清理完成后可以清楚告警
-
清除告警信息
1
2
|
$ ETCDCTL_API=3 etcdctl alarm disarm
memberID:13803658152347727308 alarm:NOSPACE
|
1.3. 碎片数据统计
具体的空洞文件的大小,可以根据相关的 metric 计算出来,一旦达到了一定阈值,就可以做一次碎片整理。具体计算方式为:
1
2
3
|
curl -s http://localhost:2379/metrics |grep -iE "^etcd_mvcc_db_total_size_in_bytes|^etcd_mvcc_db_total_size_in_use_in_bytes"
etcd_mvcc_db_total_size_in_bytes 20480
etcd_mvcc_db_total_size_in_use_in_bytes 16384
|
- etcd_mvcc_db_total_size_in_bytes: etcd 的磁盘存储总共占用的空间
- etcd_mvcc_db_total_size_in_use_in_bytes: 实际用于数据存储占用的空间
- etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes: 通过碎片整理可以释放出来的空间
1.4. 历史压缩
因为 etcd 保持它的键空间的确切历史,这个历史应该定期压缩来避免性能下降和最终的存储空间枯竭。压缩键空间历史删除所有关于被废弃的在给定键空间修订版本之前的键的信息。这些 key 使用的空间随机变得可用来继续写入键空间。
键空间可以使用 etcd 的时间窗口历史保持策略自动压缩,或者使用 etcdctl 手工压缩。 etcdctl 方法在压缩过程上提供细粒度的控制,反之自动压缩适合仅仅需要一定时间长度的键历史的应用。
etcd 可以使用带有小时时间单位的 --auto-compaction 选项来设置为自动压缩键空间:
1
2
|
# 保持一个小时的历史
$ etcd --auto-compaction-retention=1
|
根据实践发现只配置 auto-compaction-retention 只会做碎片整理,不会实际减少空间大小; 如果需要减少大小还是需要使用 etcdctl compact 和 etcdctl defrag 清理空间
etcdctl 如下发起压缩工作:
1
|
$ rev=$(ETCDCTL_API=3 etcdctl --endpoints=:2379 endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*')
|
-
进行一次压缩,释放掉老的版本
1
2
|
$ ETCDCTL_API=3 etcdctl compact $rev
compacted revision 1516
|
在压缩修订版本之前的修订版本变得无法访问:
1
2
|
$ etcdctl get --rev=2 somekey
Error: rpc error: code = 11 desc = etcdserver: mvcc: required revision has been compacted
|
1.5. 反碎片化
在压缩键空间之后,后端数据库可能出现内部。内部碎片是指可以被后端使用但是依然消耗存储空间的空间。反碎片化过程释放这个存储空间到文件系统。反碎片化在每个成员上发起,因此集群范围的延迟尖峰(latency spike)可能可以避免。
需要注意的是,在整个碎片整理过程中,整个 member 将处于不可用状态,因此针对多点部署的 etcd,在执行碎片整理的时候,要逐台进行整理,并且在整理过程中保证其他节点能够满足 quorum 需求。
通过留下间隔在后端数据库,压缩旧有修订版本会内部碎片化 etcd 。碎片化的空间可以被 etcd 使用,但是对于主机文件系统不可用。
为了反碎片化 etcd 成员, 使用 etcdctl defrag 命令:
1
2
|
$ etcdctl defrag
Finished defragmenting etcd member[127.0.0.1:2379]
|
1
2
|
$ ETCDCTL_API=3 etcdctl put newkey 123
OK
|
1.6. 参考
数据存储空间

参考文档:
https://docs.daocloud.io/kpanda/best-practice/etcd-backup/#_5
ETCD 是用于共享配置和服务发现的分布式、一致性的 KV 存储系统。它是 Kubernetes 集群中极为重要的一部分,存储了集群所有的数据信息。如果发生灾难或者 etcd 的数据丢失,都会影响集群数据的恢复。下面是备份和恢复 ETCD 数据的步骤:
备份 ETCD 数据
-
命令行备份(在 k8s-master1 机器上执行):
1
|
$ ETCDCTL_API=3 etcdctl --cacert=/opt/kubernetes/ssl/ca.pem --cert=/opt/kubernetes/ssl/server.pem --key=/opt/kubernetes/ssl/server-key.pem --endpoints=https://192.168.1.36:2379 snapshot save /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db
|
这将在指定目录下保存一个 ETCD 快照文件,备份保留 30 天。
-
备份脚本(同样在 k8s-master1 机器上执行):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#!/usr/bin/env bash
date
CACERT="/opt/kubernetes/ssl/ca.pem"
CERT="/opt/kubernetes/ssl/server.pem"
EKY="/opt/kubernetes/ssl/server-key.pem"
ENDPOINTS="192.168.1.36:2379"
ETCDCTL_API=3 etcdctl \
--cacert="${CACERT}" --cert="${CERT}" --key="${EKY}" \
--endpoints=${ENDPOINTS} \
snapshot save /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db
# 备份保留30天
find /data/etcd_backup_dir/ -name *.db -mtime +30 -exec rm -f {} \;
|
恢复 ETCD 数据
-
准备工作:
-
拷贝 ETCD 备份快照(从 k8s-master1 机器上拷贝到其他节点):
1
2
|
$ scp /data/etcd_backup_dir/etcd-snapshot-20191222.db root@k8s-master2:/data/etcd_backup_dir/
$ scp /data/etcd_backup_dir/etcd-snapshot-20191222.db root@k8s-master3:/data/etcd_backup_dir/
|
-
恢复数据:
- 使用
etcdctl snapshot restore命令创建新的 ETCD 数据目录,所有成员应该使用相同的快照恢复。
- 恢复覆盖某些快照元数据(特别是成员 ID 和集群 ID)。
请注意,这里只需要备份一个 ETCD 节点,恢复时使用同一份备份数据即可。123
docker-compose 启动 etcd 集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
version: "3.6"
services:
node1:
image: quay.io/coreos/etcd:v3.4.0
volumes:
- node1-data:/etcd-data
expose:
- 2379
- 2380
networks:
cluster_net:
ipv4_address: 172.16.238.100
environment:
- ETCDCTL_API=3
command:
- /usr/local/bin/etcd
- --data-dir=/etcd-data
- --name
- node1
- --initial-advertise-peer-urls
- http://172.16.238.100:2380
- --listen-peer-urls
- http://0.0.0.0:2380
- --advertise-client-urls
- http://172.16.238.100:2379
- --listen-client-urls
- http://0.0.0.0:2379
- --initial-cluster
- node1=http://172.16.238.100:2380,node2=http://172.16.238.101:2380,node3=http://172.16.238.102:2380
- --initial-cluster-state
- new
- --initial-cluster-token
- docker-etcd
node2:
image: quay.io/coreos/etcd:v3.4.0
volumes:
- node2-data:/etcd-data
networks:
cluster_net:
ipv4_address: 172.16.238.101
environment:
- ETCDCTL_API=3
expose:
- 2379
- 2380
command:
- /usr/local/bin/etcd
- --data-dir=/etcd-data
- --name
- node2
- --initial-advertise-peer-urls
- http://172.16.238.101:2380
- --listen-peer-urls
- http://0.0.0.0:2380
- --advertise-client-urls
- http://172.16.238.101:2379
- --listen-client-urls
- http://0.0.0.0:2379
- --initial-cluster
- node1=http://172.16.238.100:2380,node2=http://172.16.238.101:2380,node3=http://172.16.238.102:2380
- --initial-cluster-state
- new
- --initial-cluster-token
- docker-etcd
node3:
image: quay.io/coreos/etcd:v3.4.0
volumes:
- node3-data:/etcd-data
networks:
cluster_net:
ipv4_address: 172.16.238.102
environment:
- ETCDCTL_API=3
expose:
- 2379
- 2380
command:
- /usr/local/bin/etcd
- --data-dir=/etcd-data
- --name
- node3
- --initial-advertise-peer-urls
- http://172.16.238.102:2380
- --listen-peer-urls
- http://0.0.0.0:2380
- --advertise-client-urls
- http://172.16.238.102:2379
- --listen-client-urls
- http://0.0.0.0:2379
- --initial-cluster
- node1=http://172.16.238.100:2380,node2=http://172.16.238.101:2380,node3=http://172.16.238.102:2380
- --initial-cluster-state
- new
- --initial-cluster-token
- docker-etcd
volumes:
node1-data:
node2-data:
node3-data:
networks:
cluster_net:
driver: bridge
ipam:
driver: default
config:
-
subnet: 172.16.238.0/24
|
使用 docker-compose up 启动集群之后使用 docker exec 命令登录到任一节点测试 etcd 集群。
1
2
3
4
|
/ # etcdctl member list
daf3fd52e3583ff, started, node3, http://172.16.238.102:2380, http://172.16.238.102:2379
422a74f03b622fef, started, node1, http://172.16.238.100:2380, http://172.16.238.100:2379
ed635d2a2dbef43d, started, node2, http://172.16.238.101:2380, http://172.16.238.101:2379
|
参考文档:
https://yeasy.gitbook.io/docker_practice/etcd/cluster
archlinux on wsl2 看不到 lsmod
在 WSL 2 中运行 Arch Linux 时,lsmod命令通常无法显示已加载的内核模块信息,因为 WSL 2 共享 Windows 主机的内核,不提供直接的内核模块管理功能。在 WSL 2 中,内核模块的加载和管理通常受到限制,因此lsmod命令将不会显示已加载的模块。
如果你需要查看有关内核模块的信息,例如在 Arch Linux 中,你可以考虑使用以下方法:
-
查看 /proc/modules 文件:在 WSL 2 的 Arch Linux 分发版中,你可以查看 /proc/modules 文件以获取已加载模块的列表。使用cat命令查看该文件的内容,例如:
这将显示已加载模块的列表。
-
使用 dmesg 命令:你可以使用 dmesg 命令来查看有关内核的日志信息,其中包括有关已加载模块的信息。运行以下命令:
1
|
dmesg | grep "module_name"
|
用实际模块的名称替换 "module_name" 来查找特定模块的信息。
-
查看 /sys 文件系统:你还可以查看 /sys 文件系统来获取内核信息,包括有关已加载模块的信息。使用ls和cat等命令来查看文件系统中的信息。
请注意,WSL 2 的内核是由 Windows 提供的,因此其模块管理方式与传统的 Linux 发行版有所不同。如果你需要在 WSL 2 中使用特定的内核模块,可能需要更深入地了解 WSL 2 的内核和模块管理机制,或者考虑在独立的 Linux 发行版中进行相关操作。