2.1.3.1 需要安装 lvm 包
|
|
2.1.3.2 内核要求 RBD
一般发行版的内核都编译有,但你最好确定下:
|
|
可以用以下命令放到开机启动项里
|
|
CephFS
如果你想使用 cephfs,内核最低要求是 4.17。
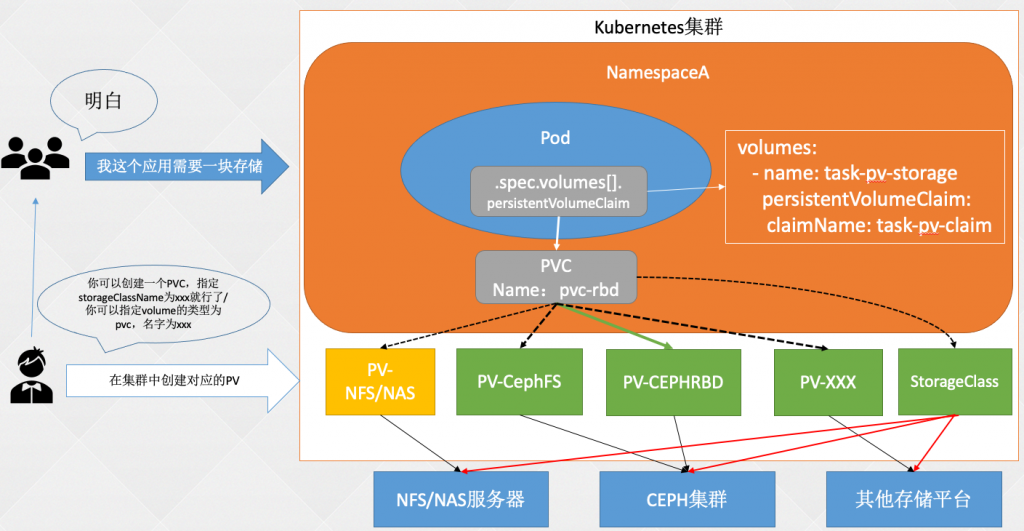
Volume
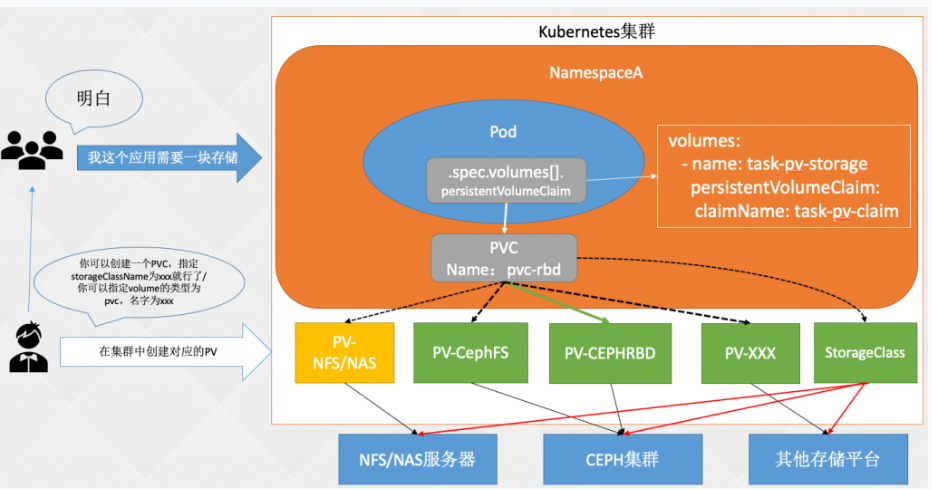
最开始直接将 volume 类型定义在一个 yaml 文件中存储不利于解藕,更适合于 k8s 管理员自己使用
|
|
后来引入了 PV 和 PVC 实现了解藕,之前只提到了静态存储,但是当集群规模变大,手动创建 PV 也是非常复杂的工作,而且不利于 PV 的回收,一旦创建的 PV 非常多,管理和扩容也很麻烦
更简单的持久化存储方式
如何解放管理 volume 的编写了,答案是 storageClass
StorageClass:存储类,由 K8s 管理员创建,用于动态 PV 的管理,可以链接至不同的后端存储,比如 Ceph、GlusterFS 等。之后对存储的请求可以指向 StorageClass,然后 StorageClass 会自动的创建、删除 PV。
实现方式如下:
- in-tree: 内置于K8s 核心代码,对于存储的管理,都需要编写相应的代码。开发人员需要学习合适配各种配置,给开发人员造成较大的压力
- out-of-tree:让存储厂商适配 k8s 逻辑或接口,由存储厂商提供一个驱动(CSI或 Flex Volume),安装到 K8s 集群,然后StorageClass 只需要配置该驱动即可,驱动器会代替 StorageClass 管理存储,SCI 符合未来发展趋势。(类似于容器厂商兼容 k8s 的过程,k8s 独自开发 CRI(Container runtime interface)接口,各容器厂商开发兼容 K8S 兼容 k8s 接口,让 k8s 可以有更多的容器厂商选择)
StorageClass官方文档:https://kubernetes.io/docs/concepts/storage/storage-classes/
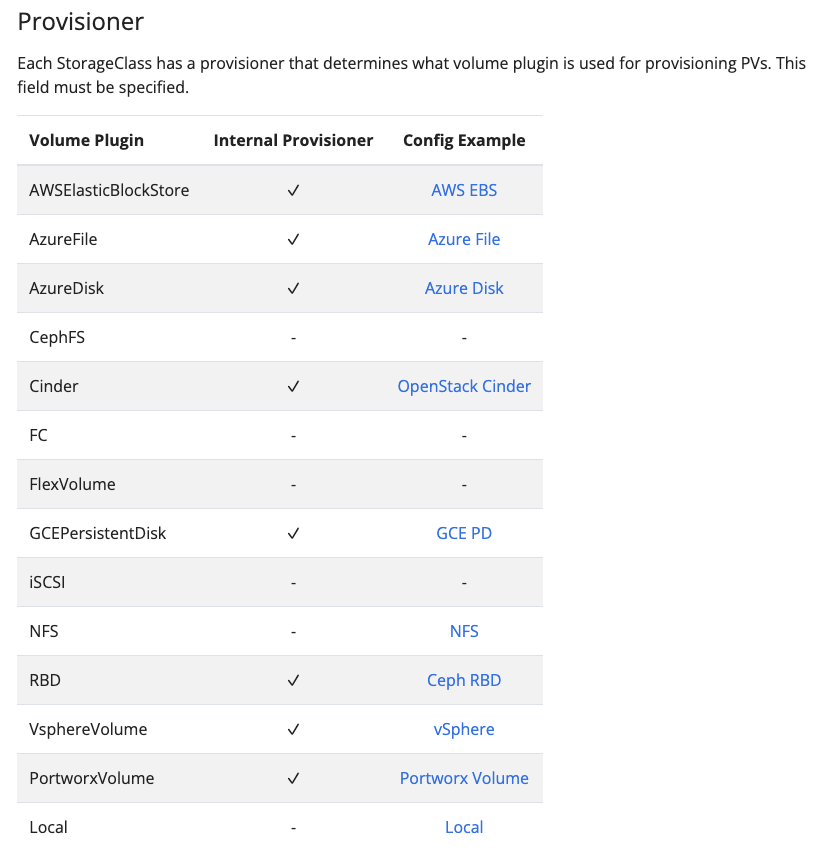
k8s 官方已经内置到代码中的 StorageClass(in-tree 模式,未来趋势向 CSI 方向迁移)
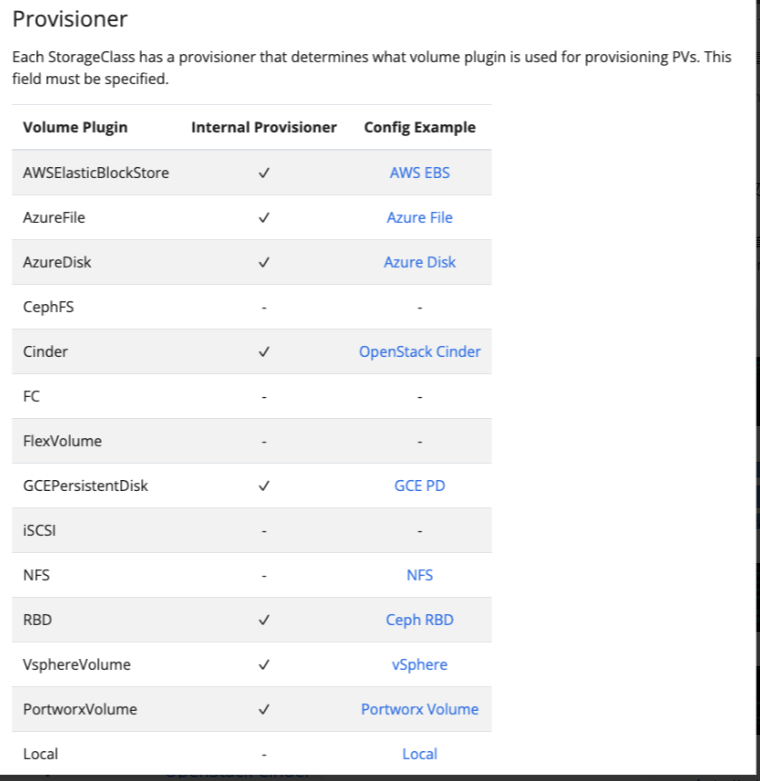
下面是 k8s 适配是 AWS 厂商支持的一段参数(parameters 之后适配):
|
|
下面是 k8s 适配 NFS 参数配置:
|
|
下面是适配 Ceph RBD 的参数配置:
|
|
云原生存储 Rook(存储和 k8s 的桥梁)
介绍
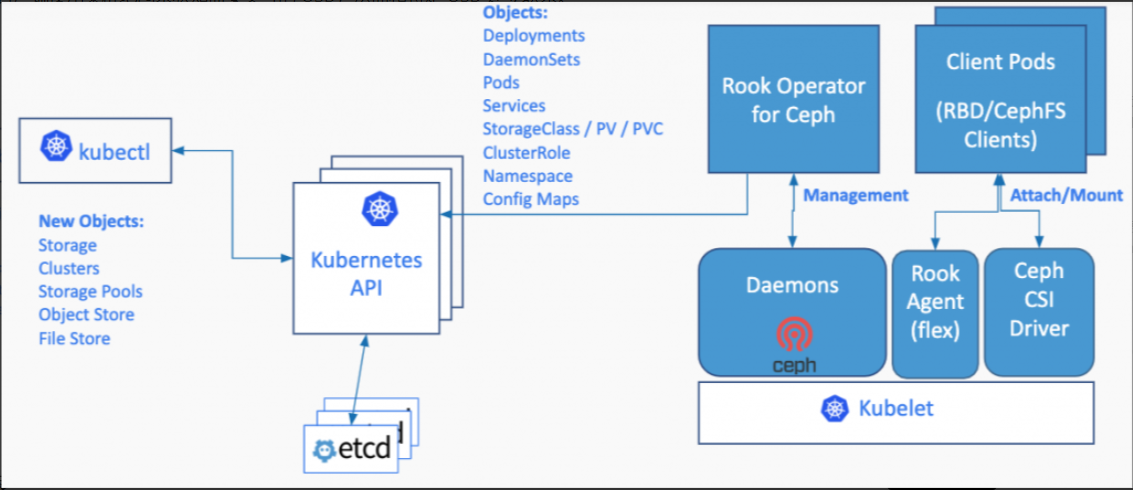
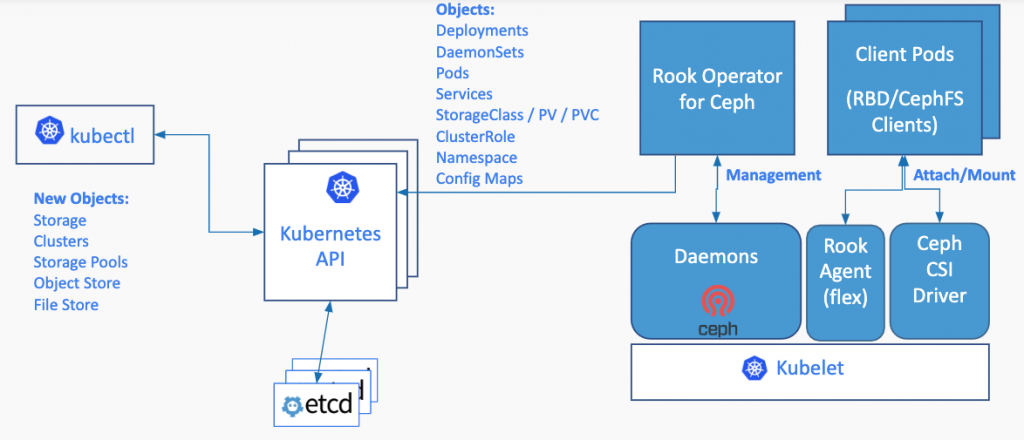
Rook 是一个自我管理的分布式存储编排系统,它本身并不是存储系统,在存储和 k8s 之前搭建了一个桥梁,使存储系统的搭建或者维护变得特别简单,Rook 将分布式存储系统转变为自我管理、自我扩展、自我修复的存储服务。它让一些存储的操作,比如部署、配置、扩容、升级、迁移、灾难恢复、监视和资源管理变得自动化,无需人工处理。并且 Rook 支持 CSI,可以利用 CSI 做一些 PVC 的快照、扩容、克隆等操作。
参考文档:https://rook.io/
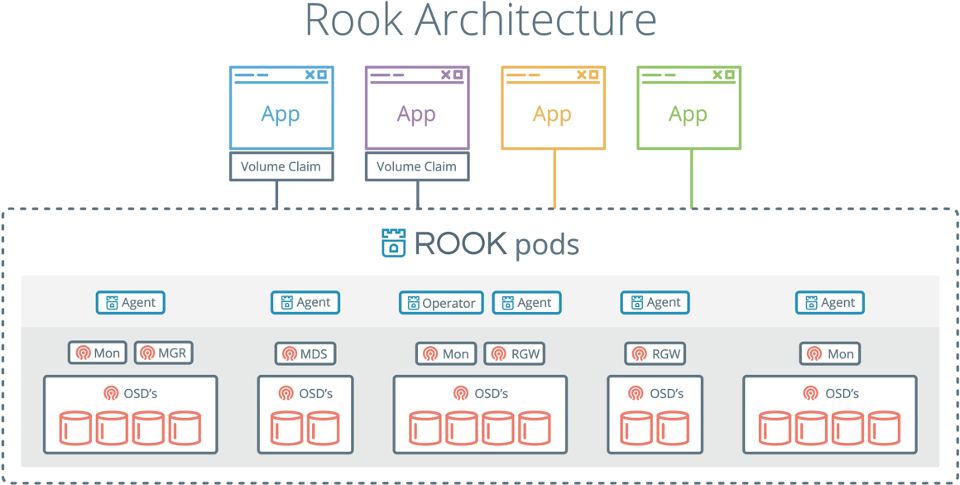
Rook 架构
生产环境有单独的 ceph 集群,Rook 建议使用外部连接方式连接 k8s 和 cepth 集群,但是测试开发环境是没有单独的 ceph 集群可以使用,中小型公司如果没有很强的运维能力,不建议在外部集群搭建 ceph 平台,而建议使用 Rook 跑一个 k8s 集群内部的 cepth 集群,本文档不去单独讲解 CSI 和 Ceph,仅仅演示 StorageClass 和 CSI 连接 ceph 集群的实现方式,所以使用 Rook 实现本地 ceph,Rook 同时还能解决非生产环境中(部分大企业已经用在生产环境)mysql、redis、kafka 较为方便有效的的存储实现方式,rook 基于本地存储的需求,如果想深入学习外部存储集群方式,可以单独去看 ceph、CSI 的课程,如果 rook 用在生产环境,建议在本地环境搭建时,将 OSD 节点(cepth)和 k8s 业务节点分开
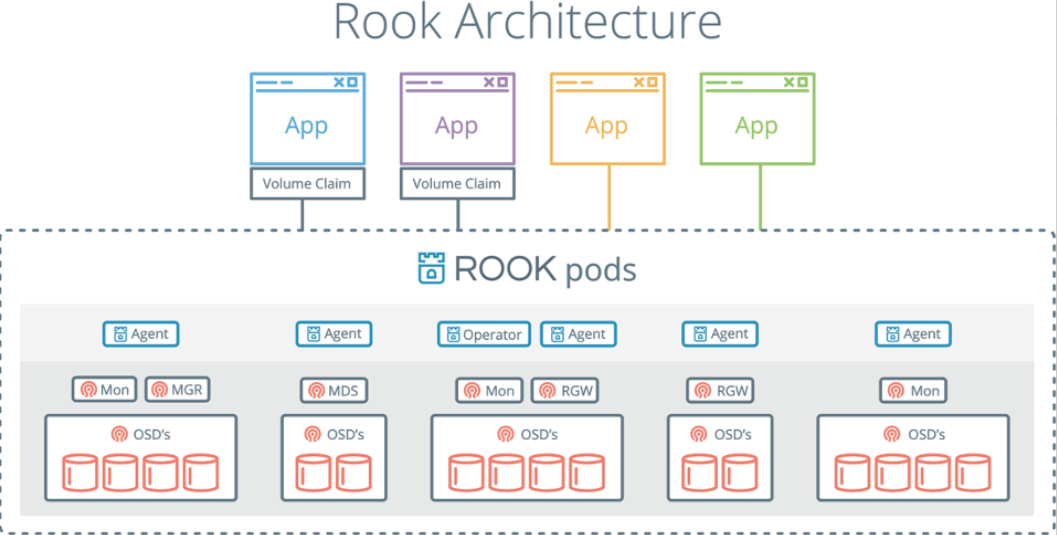
Rook 包含多个组件:
- Rook Operator:Rook 的核心组件,Rook Operator 是一个简单的容器,自动启动存储集群(Rook Operator 让用户可以通过 CRD 的是用来创建和管理存储集群。每种资源都定义了自己的 CRD.),并监控存储守护进程,来确保存储集群的健康。Rook 还会用 Kubernetes Pod 的形式,部署 Ceph 的 MON、OSD 以及 MGR 守护进程。
- Rook Agent:在每个存储节点上运行,并配置一个 FlexVolume 插件,和 Kubernetes 的存储卷控制框架进行集成。Agent 处理所有的存储操作,例如挂接网络存储设备、在主机上加载存储卷以及格式化文件系统等。
- Rook Discovers:检测挂接到存储节点上的存储设备。
- Rook Cluster:提供了对存储机群的配置能力,用来提供块存储、对象存储以及共享文件系统。每个集群都有多个 Pool。Pool:为块存储提供支持。Pool 也是给文件和对象存储提供内部支持。Object Store:用 S3 兼容接口开放存储服务。File System:为多个 Kubernetes Pod 提供共享存储。
Ceph 包括多个组件:
- Ceph Monitors(MON):负责生成集群票选机制。所有的集群节点都会向 Mon 进行汇报,并在每次状态变更时进行共享信息。
- Ceph Object Store Devices(OSD):负责在本地文件系统保存对象,并通过网络提供访问。通常 OSD 守护进程会绑定在集群的一个物理盘上,Ceph 客户端直接和 OSD 打交道。
- Ceph Manager(MGR):提供额外的监控和界面给外部的监管系统使用。
- Reliable Autonomic Distributed Object Stores:Ceph 存储集群的核心。这一层用于为存储数据提供一致性保障,执行数据复制、故障检测以及恢复等任务。
- MDS:负责跟踪文件存储层次结构
- RGW:提供对象存储接口(AWS S3、阿里云 OSS 等)
为了在 Ceph 上进行读写,客户端首先要联系 MON,获取最新的集群地图,其中包含了集群拓扑以及数据存储位置的信息。Ceph 客户端使用集群地图来获知需要交互的 OSD,从而和特定 OSD 建立联系。
Rook 安装
注意事项:
- K8s 集群至少五个节点,每个节点的内存不低于 5G,CPU 不低于 2 核
- 至少有三个存储节点,并且每个节点至少有一个裸盘
- K8s 集群所有的节点时间必须一致,被设置的节点不能打污点,除非配置污点容忍
参考文档:https://rook.io/docs/rook/v1.6/ceph-storage.html
K8s 云原生存储&存储进阶
LJH • 2023 年 6 月 15 日 下午 7:45 • Kubernetes 存储高级 • 阅读 67
Volume 回顾
最开始直接将 volume 类型定义在一个 yaml 文件中存储不利于解藕,更适合于 k8s 管理员自己使用
|
|
后来引入了 PV 和 PVC 实现了解藕,之前只提到了静态存储,但是当集群规模变大,手动创建 PV 也是非常复杂的工作,而且不利于 PV 的回收,一旦创建的 PV 非常多,管理和扩容也很麻烦
更简单的持久化存储方式
下面讲解动态存储,通过 SirageClass 使用
StorageClass:存储类,由 K8s 管理员创建,用于动态 PV 的管理,可以链接至不同的后端存储,比如 Ceph、GlusterFS 等。之后对存储的请求可以指向 StorageClass,然后 StorageClass 会自动的创建、删除 PV。
实现方式:
- in-tree: 内置于K8s 核心代码,对于存储的管理,都需要编写相应的代码。开发人员需要学习合适配各种配置,给开发人员造成较大的压力
- out-of-tree:让存储厂商适配 k8s 逻辑或接口,由存储厂商提供一个驱动(CSI或 Flex Volume),安装到 K8s 集群,然后StorageClass 只需要配置该驱动即可,驱动器会代替 StorageClass 管理存储,SCI 符合未来发展趋势。(类似于容器厂商兼容 k8s 的过程,k8s 独自开发 CRI(Container runtime interface)接口,各容器厂商开发兼容 K8S 兼容 k8s 接口,让 k8s 可以有更多的容器厂商选择)
StorageClass官方文档:https://kubernetes.io/docs/concepts/storage/storage-classes/
k8s 官方已经内置到代码中的 StorageClass(in-tree 模式,未来趋势向 CSI 方向迁移)
下面是 k8s 适配是 AWS 厂商支持的一段参数(parameters 之后适配):
|
|
下面是 k8s 适配 NFS 参数配置:
|
|
下面是适配 Ceph RBD 的参数配置:
|
|
云原生存储 Rook(存储和 k8s 的桥梁)
介绍
Rook 是一个自我管理的分布式存储编排系统,它本身并不是存储系统,在存储和 k8s 之前搭建了一个桥梁,使存储系统的搭建或者维护变得特别简单,Rook 将分布式存储系统转变为自我管理、自我扩展、自我修复的存储服务。它让一些存储的操作,比如部署、配置、扩容、升级、迁移、灾难恢复、监视和资源管理变得自动化,无需人工处理。并且 Rook 支持 CSI,可以利用 CSI 做一些 PVC 的快照、扩容、克隆等操作。
参考文档:https://rook.io/
Rook 架构
生产环境有单独的 ceph 集群,Rook 建议使用外部连接方式连接 k8s 和 cepth 集群,但是测试开发环境是没有单独的 ceph 集群可以使用,中小型公司如果没有很强的运维能力,不建议在外部集群搭建 ceph 平台,而建议使用 Rook 跑一个 k8s 集群内部的 cepth 集群,本文档不去单独讲解 CSI 和 Ceph,仅仅演示 StorageClass 和 CSI 连接 ceph 集群的实现方式,所以使用 Rook 实现本地 ceph,Rook 同时还能解决非生产环境中(部分大企业已经用在生产环境)mysql、redis、kafka 较为方便有效的的存储实现方式,rook 基于本地存储的需求,如果想深入学习外部存储集群方式,可以单独去看 ceph、CSI 的课程,如果 rook 用在生产环境,建议在本地环境搭建时,将 OSD 节点(cepth)和 k8s 业务节点分开
Rook 包含多个组件:
- Rook Operator:Rook 的核心组件,Rook Operator 是一个简单的容器,自动启动存储集群(Rook Operator 让用户可以通过 CRD 的是用来创建和管理存储集群。每种资源都定义了自己的 CRD.),并监控存储守护进程,来确保存储集群的健康。Rook 还会用 Kubernetes Pod 的形式,部署 Ceph 的 MON、OSD 以及 MGR 守护进程。
- Rook Agent:在每个存储节点上运行,并配置一个 FlexVolume 插件,和 Kubernetes 的存储卷控制框架进行集成。Agent 处理所有的存储操作,例如挂接网络存储设备、在主机上加载存储卷以及格式化文件系统等。
- Rook Discovers:检测挂接到存储节点上的存储设备。
- Rook Cluster:提供了对存储机群的配置能力,用来提供块存储、对象存储以及共享文件系统。每个集群都有多个 Pool。Pool:为块存储提供支持。Pool 也是给文件和对象存储提供内部支持。Object Store:用 S3 兼容接口开放存储服务。File System:为多个 Kubernetes Pod 提供共享存储。
Ceph 包括多个组件:
- Ceph Monitors(MON):负责生成集群票选机制。所有的集群节点都会向 Mon 进行汇报,并在每次状态变更时进行共享信息。
- Ceph Object Store Devices(OSD):负责在本地文件系统保存对象,并通过网络提供访问。通常 OSD 守护进程会绑定在集群的一个物理盘上,Ceph 客户端直接和 OSD 打交道。
- Ceph Manager(MGR):提供额外的监控和界面给外部的监管系统使用。
- Reliable Autonomic Distributed Object Stores:Ceph 存储集群的核心。这一层用于为存储数据提供一致性保障,执行数据复制、故障检测以及恢复等任务。
- MDS:负责跟踪文件存储层次结构
- RGW:提供对象存储接口(AWS S3、阿里云 OSS 等)
为了在 Ceph 上进行读写,客户端首先要联系 MON,获取最新的集群地图,其中包含了集群拓扑以及数据存储位置的信息。Ceph 客户端使用集群地图来获知需要交互的 OSD,从而和特定 OSD 建立联系。
Rook 安装
注意事项:
- K8s 集群至少五个节点,每个节点的内存不低于 5G,CPU 不低于 2 核
- 至少有三个存储节点,并且每个节点至少有一个裸盘
- K8s 集群所有的节点时间必须一致,被设置的节点不能打污点,除非配置污点容忍
参考文档:https://rook.io/docs/rook/v1.6/ceph-storage.html
Rook 安装
注意 1:rook 的版本大于 1.3,不要使用目录创建集群,要使用单独的裸盘进行创建,也就是创建一个新的磁盘,挂载到宿主机,不进行格式化,直接使用即可。对于的磁盘节点配置如下:
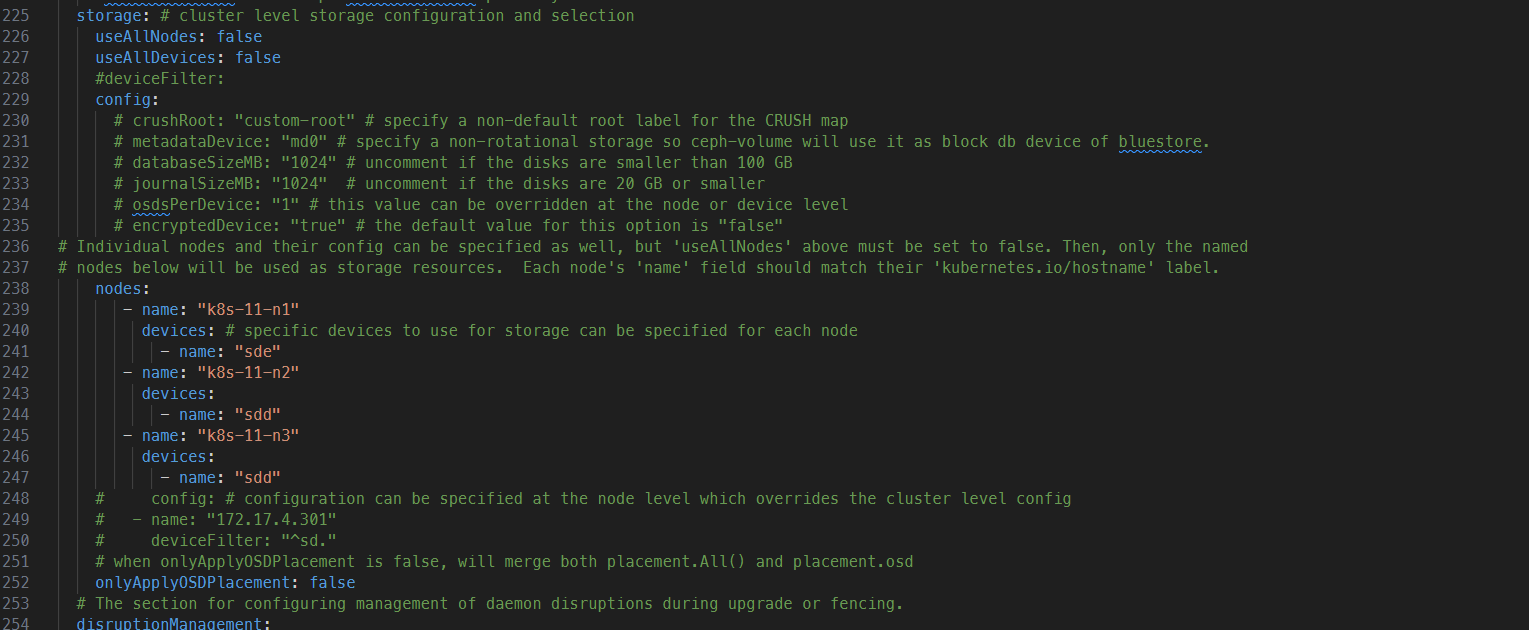
其中 nodes 下可以分配对应的节点名称和磁盘名称,磁盘名称用 lsblk 来看。
下载 Rook 安装文件
下载指定版本 Rook,也可以参考视频中的步骤下载最新版
git clone –single-branch –branch v1.6.3 https://github.com/rook/rook.git
配置更改
cd rook/deploy/examples/
修改 Rook CSI 镜像地址,原本的地址可能是 gcr 的镜像,但是 gcr 的镜像无法被国内访问,所以需要同步 gcr 的镜像到阿里云镜像仓库,文档版本已经为大家完成同步,可以直接修改如下:
vim operator.yaml

改为:
ROOK_CSI_REGISTRAR_IMAGE: “registry.cn-beijing.aliyuncs.com/dotbalo/csi-node-driver-registrar:v2.0.1”
ROOK_CSI_RESIZER_IMAGE: “registry.cn-beijing.aliyuncs.com/dotbalo/csi-resizer:v1.0.1”
ROOK_CSI_PROVISIONER_IMAGE: “registry.cn-beijing.aliyuncs.com/dotbalo/csi-provisioner:v2.0.4”
ROOK_CSI_SNAPSHOTTER_IMAGE: “registry.cn-beijing.aliyuncs.com/dotbalo/csi-snapshotter:v4.0.0”
ROOK_CSI_ATTACHER_IMAGE: “registry.cn-beijing.aliyuncs.com/dotbalo/csi-attacher:v3.0.2”
如果是其他版本,需要自行同步,同步方法可以在网上找到相关文章。可以参考https://blog.csdn.net/sinat_35543900/article/details/103290782
还是 operator 文件,新版本 rook 默认关闭了自动发现容器的部署,可以找到 ROOK_ENABLE_DISCOVERY_DAEMON 改成 true 即可:

部署 rook
1.5.3 版本的部署步骤如下:
cd cluster/examples/kubernetes/ceph
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
等待 operator 容器和 discover 容器启动
[root@k8s-master01 ceph]#kubectl -n rook-ceph get pod|egrep ‘rook-ceph-operator|rook-discover’

全部变成 1/1 Running 才可以创建 Ceph 集群
创建 ceph 集群
配置更改
主要更改的是 osd 节点所在的位置(cluster.yaml):
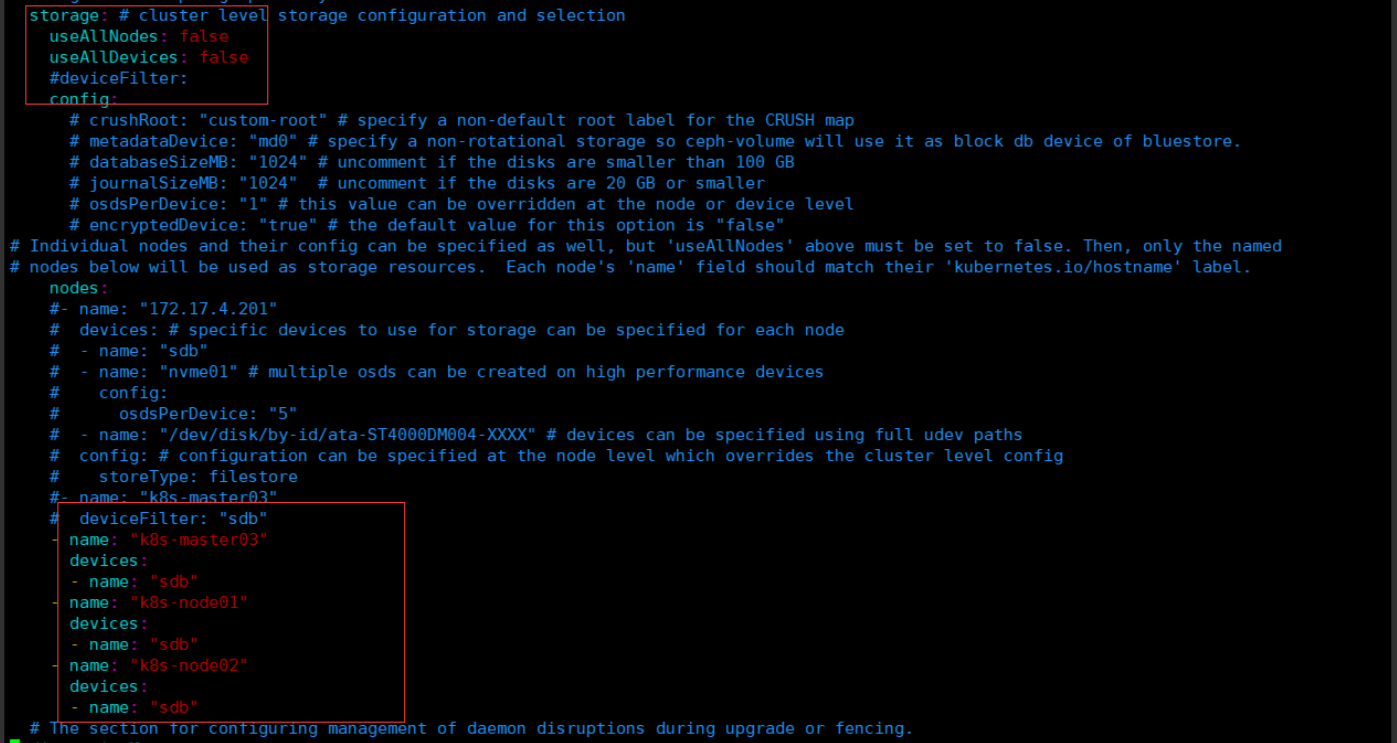
注意:新版必须采用裸盘,即未格式化的磁盘。其中 k8s-master03 k8s-node01 node02 有新加的一个磁盘,可以通过 lsblk -f 查看新添加的磁盘名称。建议最少三个节点,否则后面的试验可能会出现问题
创建 Ceph 集群
kubectl create -f cluster.yaml
创建完成后,可以查看 pod 的状态:
[root@k8s-master01 ceph]# kubectl -n rook-ceph get pod
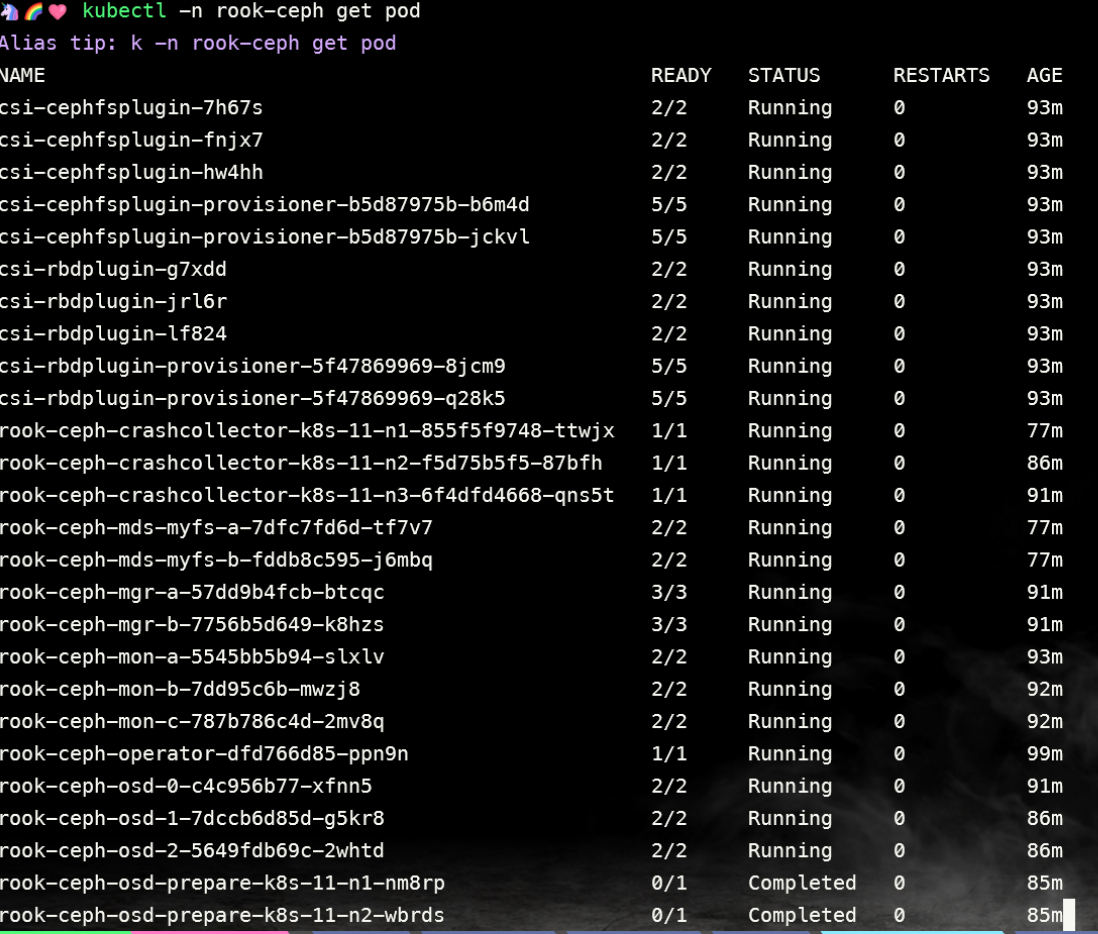
需要注意的是,osd-x 的容器必须是存在的,且是正常的。如果上述 Pod 均正常,则认为集群安装成功。磁盘几个 osd 就是几个。
更多配置:https://rook.io/docs/rook/v1.6/ceph-cluster-crd.html
安装 ceph snapshot 控制器
k8s 1.19 版本以上需要单独安装 snapshot 控制器,才能完成 pvc 的快照功能,所以在此提前安装下,如果是 1.19 以下版本,不需要单独安装,直接参考视频即可。
snapshot 控制器的部署在集群安装时的 k8s-ha-install 项目中,需要切换到 1.20.x 分支:
cd /root/k8s-ha-install/
git checkout manual-installation-v1.20.x
创建 snapshot controller:
kubectl create -f snapshotter/ -n kube-system
[root@k8s-master01 k8s-ha-install]# kubectl get po -n kube-system -l app=snapshot-controller
具体文档:https://rook.io/docs/rook/v1.6/ceph-csi-snapshot.html
安装 ceph 客户端工具
[root@k8s-master01 ceph]# pwd
cd /root/rook/cluster/examples/kubernetes/ceph
[root@k8s-master01 ceph]# kubectl create -f toolbox.yaml -n rook-ceph
deployment.apps/rook-ceph-tools created
待容器 Running 后,即可执行相关命令
[root@k8s-master01 ceph]# kubectl get po -n rook-ceph -l app=rook-ceph-tools
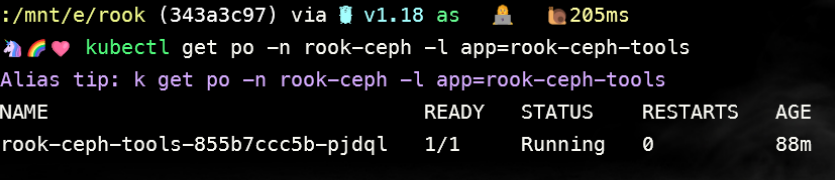
[root@k8s-master01 ceph]# kubectl -n rook-ceph exec -it deploy/rook-ceph-tools – bash
[root@rook-ceph-tools-fc5f9586c-9hs8q /]# ceph config set mon auth_allow_insecure_global_id_reclaim false
[root@rook-ceph-tools-6f7467bb4d-qzsvg /]# ceph status
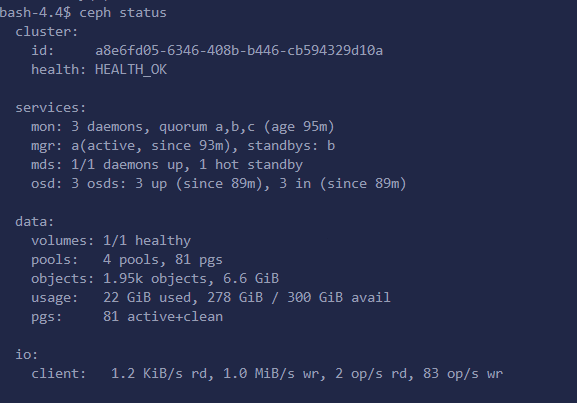
[root@rook-ceph-tools-6f7467bb4d-qzsvg /]# ceph osd status
注:按照文档应该只有 k8s-11-n1~n3,这里我都加入了

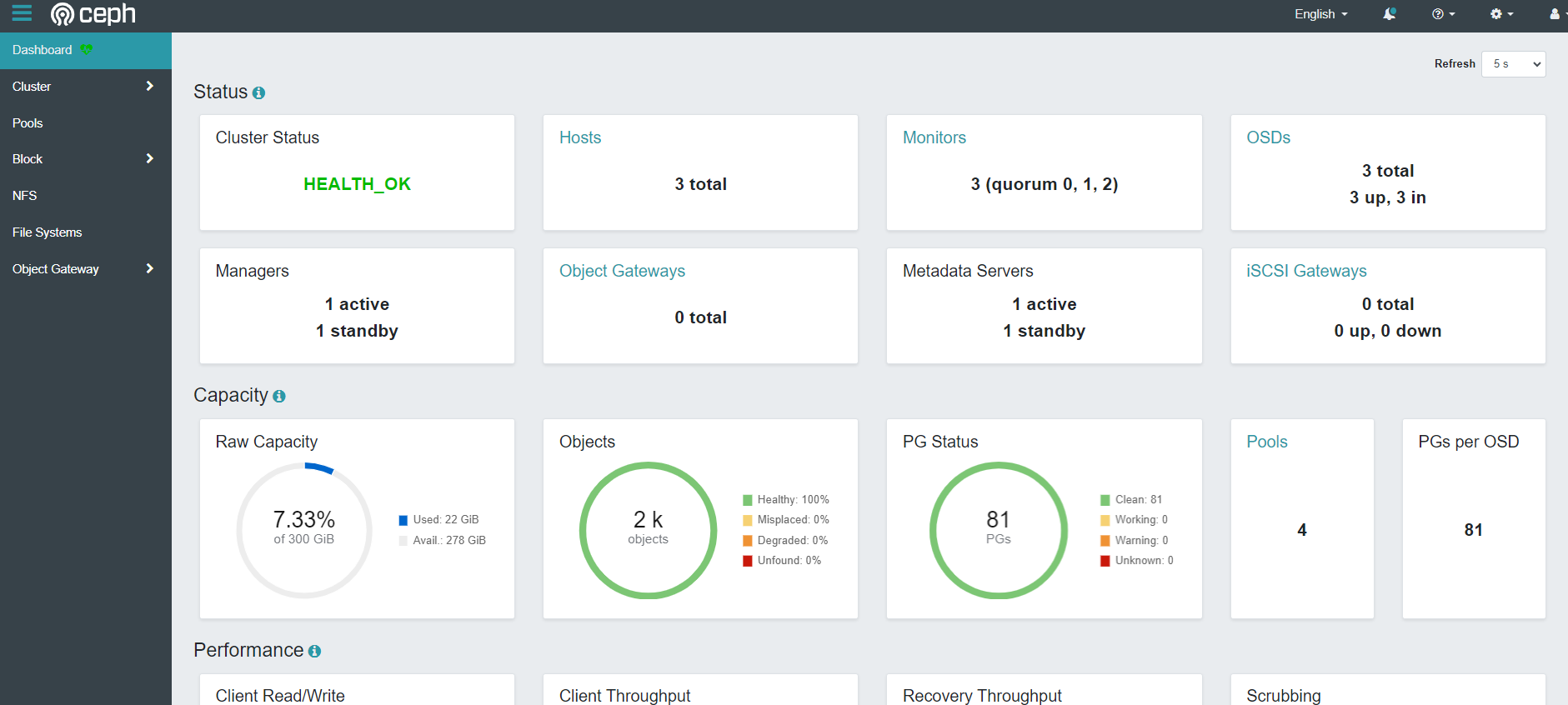
Ceph dashboard
暴露服务
默认情况下,ceph dashboard 是打开的,可以创建一个 nodePort 类型的 Service 暴露服务:
vim dashboard-np.yaml
|
|
保存退出后,会创建一个端口,然后通过任意 k8s 节点的 IP+该端口即可访问该 dashboard:
[root@k8s-master01 ceph]# kubectl get svc -n rook-ceph rook-ceph-mgr-dashboard-np

访问一下

账号为 admin,查看密码:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{[‘data’][‘password’]}" | base64 –decode && echo
问题警告解决:https://docs.ceph.com/en/octopus/rados/operations/health-checks/
ceph 块存储的使用
块存储一般用于一个 Pod 挂载一块存储使用,相当于一个服务器新挂了一个盘,只给一个应用使用。
参考文档:https://rook.io/docs/rook/v1.6/ceph-block.html
创建 StorageClass 和 ceph 的存储池
[root@k8s-master01 ceph]# pwd
/root/rook/cluster/examples/kubernetes/ceph
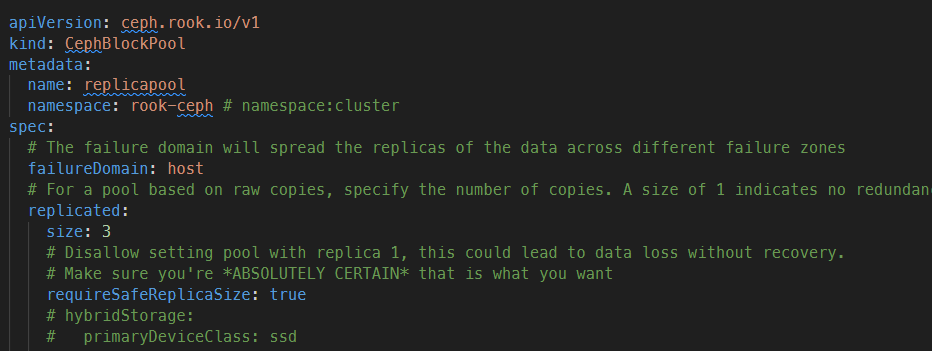
[root@k8s-master01 ceph]# vim csi/rbd/storageclass.yaml
failureDomain: host 是根据 host 来存放多个 OSD 副本,且模式为多个节点上(replicated:size 决定副本数量),若单台 node 故障可以通过其他节点上的数据恢复。因为我是试验环境,所以将副本数设置成了 2(不能设置为 1),生产环境最少为 3,且要小于等于 osd 的数量,其他配置可以参考视频:
创建 StorageClass 和存储池:
[root@k8s-master01 ceph]# kubectl create -f csi/rbd/storageclass.yaml -n rook-ceph
查看创建的 cephblockpool 和 storageClass(StorageClass 没有 namespace 隔离性):
[root@k8s-master01 ceph]# kubectl get cephblockpool -n rook-ceph
[root@k8s-master01 ceph]# kubectl get sc
此时可以在 ceph dashboard 查看到改 Pool,如果没有显示说明没有创建成功
挂载测试
创建一个 MySQL 服务
参考:https://rook.io/docs/rook/v1.6/ceph-block.html
[root@k8s-master01 kubernetes]# pwd
/root/rook/cluster/examples/kubernetes
使用 RDB 创建 mysql.yaml,mysql 要求有主从,有自己的独立空间使用块存储
|
|
[root@k8s-master01 kubernetes]# kubectl create -f mysql.yaml
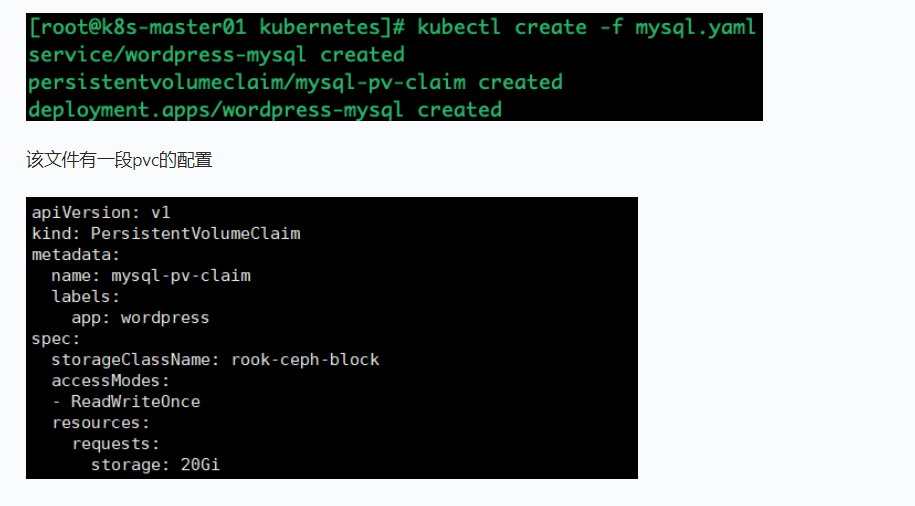
pvc 会连接刚才创建的 storageClass,然后动态创建 pv,然后连接到 ceph 创建对应的存储
之后创建 pvc 只需要指定 storageClassName 为刚才创建的 StorageClass 名称即可连接到 rook 的 ceph。如果是 statefulset,只需要将 volumeTemplateClaim 里面的 Claim 名称改为 StorageClass 名称即可动态创建 Pod。
其中 MySQL deployment 的 volumes 配置挂载了该 pvc:
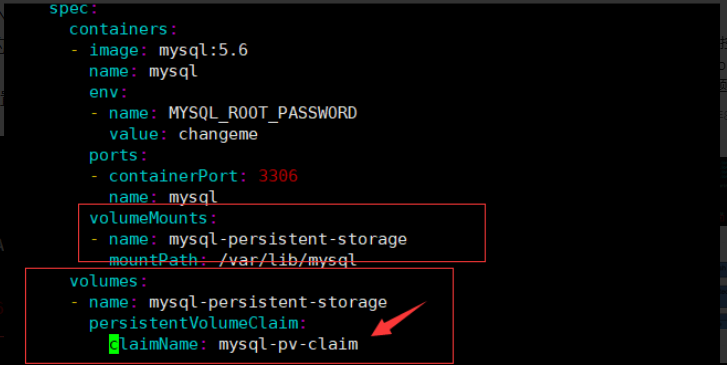
claimName 为 pvc 的名称
因为 MySQL 的数据不能多个 MySQL 实例连接同一个存储,所以一般只能用块存储。相当于新加了一块盘给 MySQL 使用。
创建完成后可以查看创建的 pvc 和 pv
此时在 ceph dashboard 上面也可以查看到对应的 image 的 csi-vol
共享文件系统的使用
共享文件系统一般用于多个 Pod 共享一个存储
官方文档:https://rook.io/docs/rook/v1.6/ceph-filesystem.html
创建共享类型的文件系统
[root@k8s-master01 ceph]# pwd
/root/rook/cluster/examples/kubernetes/ceph
[root@k8s-master01 ceph]# kubectl create -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs created
[root@k8s-master01 ceph]# vim filesystem.yaml
创建完成后会启动 mds 容器,需要等待启动后才可进行创建 pv
[root@k8s-master01 ceph]# kubectl -n rook-ceph get pod -l app=rook-ceph-mds
也可以在 ceph dashboard 上面查看状态

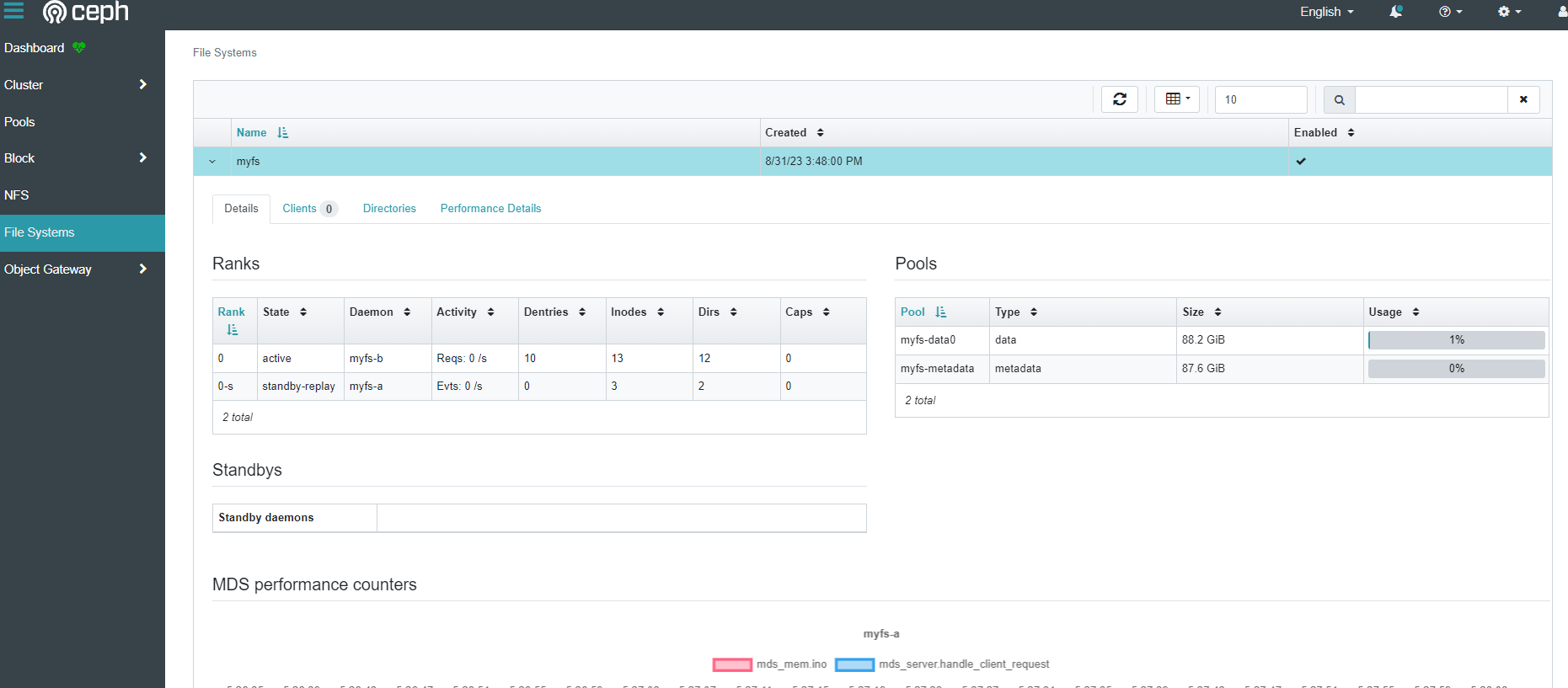
创建共享类型文件系统的 StorageClass
[root@k8s-master01 cephfs]# pwd
/root/rook/cluster/examples/kubernetes/ceph/csi/cephfs
[root@k8s-master01 cephfs]# kubectl create -f storageclass.yaml
storageclass.storage.k8s.io/rook-cephfs created
之后将 pvc 的 storageClassName 设置成 rook-cephfs 即可创建共享文件类型的存储,类似于 NFS,可以给多个 Pod 共享数据。
挂载测试
[root@k8s-master01 cephfs]# pwd
/root/rook/cluster/examples/kubernetes/ceph/csi/cephfs
[root@k8s-master01 cephfs]# ls

kube-registry.yaml
|
|
[root@k8s-master01 cephfs]# kubectl create -f kube-registry.yaml
查看创建的 pvc 和 pod
[root@k8s-master01 cephfs]# kubectl get po -n kube-system -l k8s-app=kube-registry
[root@k8s-master01 cephfs]# kubectl get pvc -n kube-system
该文件的 pvc 配置,用于连接 ceph 创建存储,如下:
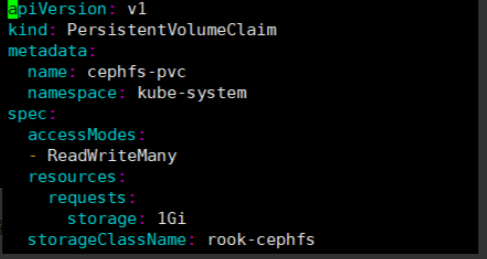
然后在 deployment 的 volumes 配置添加了该 pvc,并将其挂载到了/var/lib/registry
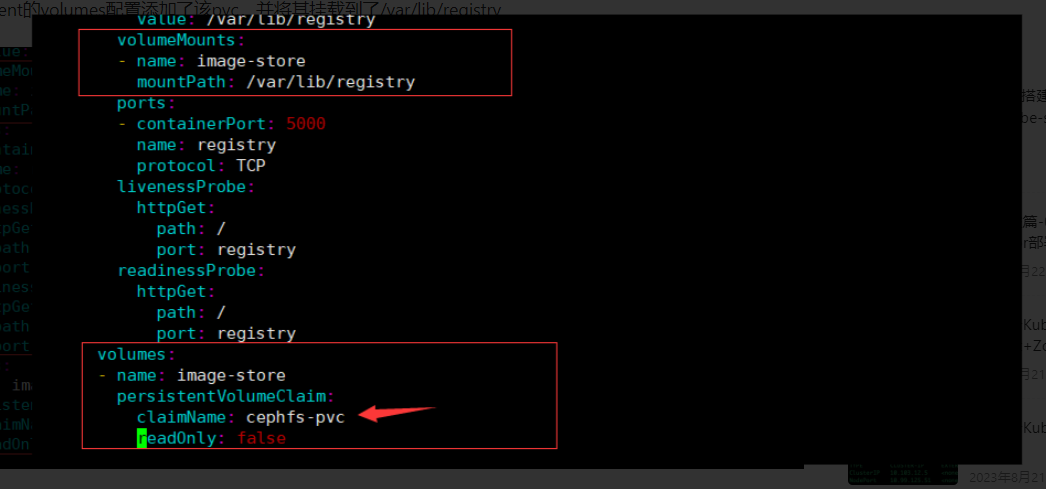
注意 claimName 为 pvc 的名称。
此时一共创建了三个 Pod,这三个 Pod 共用了一个存储,挂载到了/var/lib/registry,该目录三个容器共享数据。
验证共享数据:

Nginx 挂载测试
vim nginx.yaml
|
|
kubectl create -f nginx.yaml
测试数据清理
如果 Rook 要继续使用,可以只清理创建的 deploy、pod、pvc 即可。之后可以直接投入使用
数据清理步骤(必须听课):
- 首先清理挂载了 PVC 和 Pod,可能需要清理单独创建的 Pod 和 Deployment 或者是其他的高级资源 kubectl delete deployments.apps wordpress-mysql –all kubectl delete pod –all
- 之后清理 PVC,清理掉所有通过 ceph StorageClass 创建的 PVC 后,最好检查下 PV 是否被清理 kubectl delete pvc –all
- 之后清理快照:kubectl delete volumesnapshot XXXXXXXX
- 之后清理创建的 Pool,包括块存储和文件存储
- kubectl delete -n rook-ceph cephblockpool replicapool
- kubectl delete -n rook-ceph cephfilesystem myfs
- 清理 StorageClass:kubectl delete sc rook-ceph-block rook-cephfs
- 清理 Ceph 集群:kubectl -n rook-ceph delete cephcluster rook-ceph
- 删除 Rook 资源:
- kubectl delete -f operator.yaml
- kubectl delete -f common.yaml
- kubectl delete -f crds.yaml
- 如果卡住需要参考 Rook 的 troubleshooting
for CRD in $(kubectl get crd -n rook-ceph | awk ‘/ceph.rook.io/ {print $1}’); do kubectl get -n rook-ceph “$CRD” -o name | xargs -I {} kubectl patch {} –type merge -p ‘{“metadata”:{“finalizers”: [null]}}’ -n rook-ceph; done
- 清理数据目录和磁盘
参考链接:https://rook.io/docs/rook/v1.6/ceph-teardown.html#delete-the-data-on-hosts
参考链接:https://rook.io/docs/rook/v1.6/ceph-teardown.html
清除已经安装 rook-ceph
|
|
清理磁盘的脚本再次记录一下:
|
|
清理/var/lib/rook 目录。
如果遇到 invalid capacity 0 on image filesystem
|
|
failed to get sandbox image “k8s.gcr.io/pause:3.6”
由于 k8s.gcr.io 需要连外网才可以拉取到,导致 k8s 的基础容器 pause 经常无法获取。k8s docker 可使用代理服拉取,再利用 docker tag 解决问题
|
|
但是我们 k8s 集群中使用的 CRI 是 containerd。所以只能通过 docker tag 镜像,再使用 ctr 导入镜像.
|
|
安装 Pod 网络附加组件(calico 或 flannel)
允许控制平面节点上调度 Pod
|
|
加入节点
遇到问题
|
|
不关闭 swap 启动 k8s
|
|
|
|
dashboard
其他 pc 访问 dashboard,端口转发 安装 dashboard
|
|
获取 Token
|
|
安装 helm
安装 ingress
选择下面任何一个即可
haproxy
traefik
nginx-ingress
外部负载均衡器 metalLB
ingress 配置 Https
准备好证书文件,各种证书之间的转换方式参考转换证书格式
创建 secret 保存证书
|
|
ingress 使用证书
|
|
常用工具安装
|
|
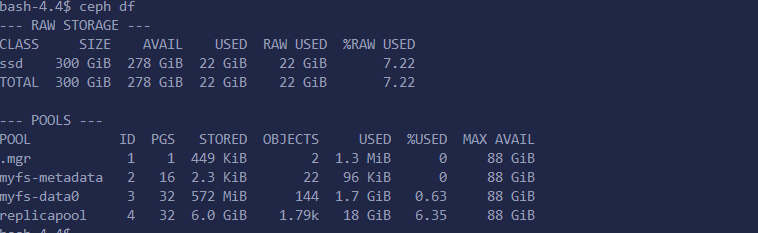
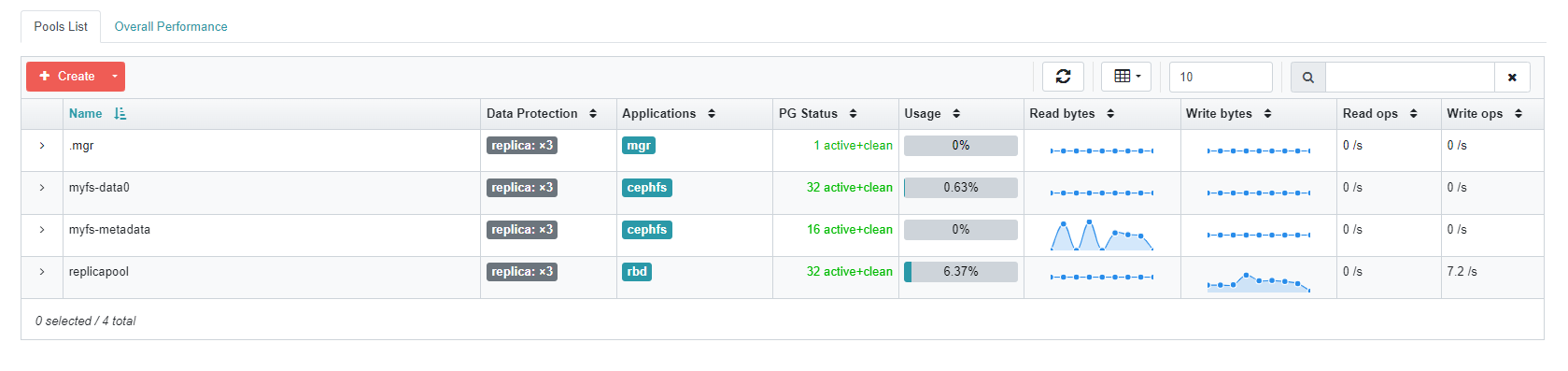
ceph 常用操作
显示 ceph pools
|
|
|
|
MySQL 单实例配置
容器资源:
- CPU:8C
- 内存:24G
- 磁盘:100G(基于 Ceph RBD,在存储千万级文件的场景下元数据大约占用 30G 磁盘空间)
- 容器镜像:mysql:5.7
MySQL 的 my.cnf 配置:
|
|
|
|
ceph 排查错误的使用,使用
|
|
ceph 报错 low disk space
出现这个问题是因为磁盘的根目录低于 30%可用,就会报这个错。
参考磁盘空间 , 故障原因: / 磁盘空间少于 70%
|
|
缩减 HOME 磁盘空间
|
|
查询 lvm 空间
|
|
扩容 root 空间
|
|
检查 LVM
|
|
查询文件系统
|
|
扩容文件系统
|
|
home 目录已经破坏, 需要进行重新格式化. 并进行数据恢复
参考 ceph 信息
|
|