下面我们介绍下如何使用 Elasticsearch+Filebeat+Kibana 来搭建 UK8S 日志解决方案。
Elasticsearch(ES)是一个基于 Lucene 构建的开源、分布式、RESTful 接口的全文搜索引擎。Elasticsearch 还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES 能够横向扩展至数以百计的服务器存储以及处理 PB 级的数据。可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机
Elasticsearch 运行时要求 vm.max_map_count 内核参数必须大于 262144,因此开始之前需要确保这个参数正常调整过。
1
|
sysctl -w vm.max_map_count=262144
|
也可以在 ES 的的编排文件中增加一个 initContainer 来修改内核参数,但这要求 kublet 启动的时候必须添加了–allow-privileged 参数,uk8s 默认开启了该参数,在后面的示例中采用 initContainer 的方式。
ES 的节点 Node 可以分为几种角色:
Master-eligible node,是指有资格被选为 Master 节点的 Node,可以统称为 Master 节点。设置 node.master: true
Data node,存储数据的节点,设置方式为 node.data: true。
Ingest node,进行数据处理的节点,设置方式为 node.ingest: true。
Trible node,为了做集群整合用的。
对于单节点的 Node,默认是 master-eligible 和 data,对于多节点的集群,需要根据需求仔细规划每个节点的角色。
为了方便演示,我们把本文所有的对象资源都放置在一个名为 elk 的 namespace 下面,所以我们需要添加创建一个 namespace:
1
|
kubectl create namespace elk
|
不区分节点角色
这种模式下,集群中的节点不做角色的区分,配置文件请参考elk-cluster.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
bash-4.4# kubectl apply -f elk-cluster.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
service/es-cluster-nodeport created
service/es-cluster created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 2m18s
es-cluster-1 1/1 Running 0 2m15s
es-cluster-2 1/1 Running 0 2m12s
kb-single-69ddfc96f5-lr97q 1/1 Running 0 2m18s
bash-4.4# kubectl get svc -n elk
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 2m20s
es-cluster-nodeport NodePort 172.17.177.40 <none> 9200:31200/TCP,9300:31300/TCP 2m20s
kb-single-svc LoadBalancer 172.17.129.82 117.50.40.48 5601:38620/TCP 2m20s
bash-4.4#
|
通过 kb-single-svc 的 EXTERNAL-IP,便可以访问 Kibana。
区分节点角色
如果需要区分节点的角色,就需要建立两个 StatefulSet 部署,一个是 Master 集群,一个是 Data 集群。Data 集群的存储示例中简单使用了 emptyDir,可以根据需要使用 localStorage 或者 hostPath,关于存储的介绍,可以参考Kubernetes 官网。这样就可以避免 Data 节点在本机重启时发生数据丢失而重建索引,但是如果发生迁移的话,如果想保留数据,只能采用共享存储的方案了。具体的编排文件在这里elk-role-cluster.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
bash-4.4# kubectl apply -f elk-role-cluster.yaml
deployment.apps/kb-single created
service/kb-single-svc created
statefulset.apps/es-cluster created
statefulset.apps/es-cluster-data created
service/es-cluster-nodeport created
service/es-cluster created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 53s
es-cluster-1 1/1 Running 0 50s
es-cluster-2 1/1 Running 0 47s
es-cluster-data-0 1/1 Running 0 53s
es-cluster-data-1 1/1 Running 0 50s
es-cluster-data-2 1/1 Running 0 47s
kb-single-69ddfc96f5-lxsn8 1/1 Running 0 53s
bash-4.4# kubectl get statefulset -n elk
NAME READY AGE
es-cluster 3/3 2m
es-cluster-data 3/3 2m
bash-4.4# kubectl get svc -n elk
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 44s
es-cluster-nodeport NodePort 172.17.63.138 <none> 9200:31200/TCP,9300:31300/TCP 44s
kb-single-svc LoadBalancer 172.17.183.59 117.50.92.74 5601:32782/TCP
|
在进行日志收集的过程中,我们首先想到的是使用 Logstash,因为它是 ELK stack 中的重要成员,但是在测试过程中发现,Logstash 是基于 JDK 的,在没有产生日志的情况单纯启动 Logstash 就大概要消耗 500M 内存,在每个 Pod 中都启动一个日志收集组件的情况下,使用 logstash 有点浪费系统资源,因此我们更推荐一个轻量级的日志采集工具 Filebeat,经测试单独启动 Filebeat 容器大约只会消耗 12M 内存。 具体的编排文件可以参考filebeat.yaml,本例采用 DaemonSet 的方式编排。
1
2
3
4
5
6
|
bash-4.4# kubectl apply -f filebeat.yaml
configmap/filebeat-config created
daemonset.extensions/filebeat created
clusterrolebinding.rbac.authorization.k8s.io/filebeat created
clusterrole.rbac.authorization.k8s.io/filebeat created
serviceaccount/filebeat created
|
编排文件中将 filebeat 使用到的配置 ConfigMap 挂载到/home/uk8s-filebeat/filebeat.yaml,实际启动 filebeat 时使用该自定义配置。有关 filebeat 的配置可以参见 Configuring Filebeat中相应的说明。
Filebeat 命令行参数可以参考 Filebeat Command Reference,本例中使用到的参数说明如下:
指定 Filebeat 使用的配置文件,如果不指定则使用默认的配置文件/usr/share/filebeat/filebeat.yaml
为指定的 selectors 打开调试模式, selectors 是以逗号分隔的列表,-d “*” 表示对所有组件进行调试。在实际生产环境中请关闭该选项,初次配置时打开可以有效排错。
指定日志输出到标准错误输出,关闭默认的 syslog/file 输出
由于 Filebeat 对 message 的过滤功能有限,在实际生产环境中通常会结合 logstash。这种架构中 Filebeat 作为日志收集器,将数据发送到 Logstash,经过 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈献给用户。
创建 Logstash 的配置文件,可以参考elk-log.conf,更详细的配置信息见Configuring Logstash。大部分 Logstash 配置文件都可以分为 3 部分:input, filter 和 output,示例配置文件中指定 Logstash 从 Filebeat 获取数据,并输出到 Elasticsearch。
1
2
3
4
5
6
|
bash-4.4# kubectl create configmap elk-pipeline-config --from-file=elk-log.conf --namespace=elk
configmap/elk-pipeline created
bash-4.4# kubectl get configmap -n elk
NAME DATA AGE
elk-pipeline-config 1 9s
filebeat-config 1 21m
|
编写 logstash.yaml ,在 yaml 文件中挂载之前创建的 ConfigMap。需要注意的是,此处使用了 logstash-oss 镜像,关于 oss 和 non-oss 版本的区别请参考链接。
1
2
3
4
5
6
|
bash-4.4# kubectl apply -f logstash.yaml
deployment.extensions/elk-log-pipeline created
service/elk-log-pipeline created
bash-4.4# kubectl get po -n elk
NAME READY STATUS RESTARTS AGE
elk-log-pipeline-55d64bbcf4-9v49w 1/1 Running 0 50m
|
1
2
3
4
5
6
|
bash-4.4# kubectl logs -f elk-log-pipeline-55d64bbcf4-9v49w -n elk
[2019-03-19T08:56:03,631][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
...
[2019-03-19T08:56:09,845][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2019-03-19T08:56:09,934][INFO ][logstash.pipeline ] Pipeline started succesfully {:pipeline_id=>"main", :thread=>"#<Thread:0x77d5c9b5 run>"}
[2019-03-19T08:56:10,034][INFO ][org.logstash.beats.Server] Starting server on port: 5044
|
1
2
3
4
5
6
7
8
9
10
11
|
items:
- apiVersion: v1
kind: ConfigMap
metadata:
...
data:
filebeat.yml: |
...
output.logstash:
hosts: ["elk-log-pipeline:5044"]
...
|
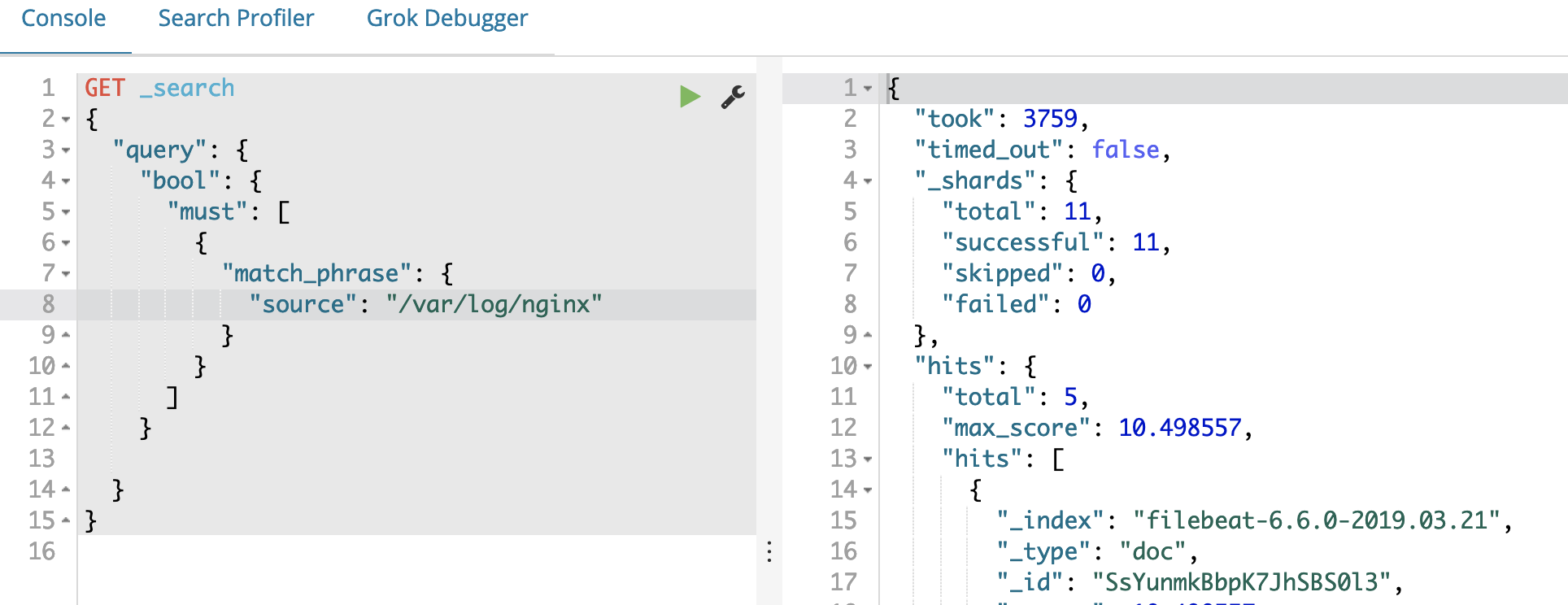
前面我们已经部署好了 Filebeat 用于采集应用日志,并将采集到的日志输出到 Elasticsearch,下面我们以一个 nginx 应用为例,来测试日志能否正常采集、索引、展示。
创建一个 Nginx 的部署和 LoadBalancer 服务,这样可以通过 eip 访问 Nginx。配置文件请参考nginx.yaml,我们将 Nginx 访问日志的输出路径以 hostPath 的形式挂载到宿主的/var/log/nginx/路径下。
1
2
3
4
5
6
7
8
9
10
|
bash-4.4# kubectl apply -f nginx.yaml
deployment.apps/nginx-deployment unchanged
service/nginx-cluster configured
bash-4.4# kubectl get svc -n elk nginx-cluster
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
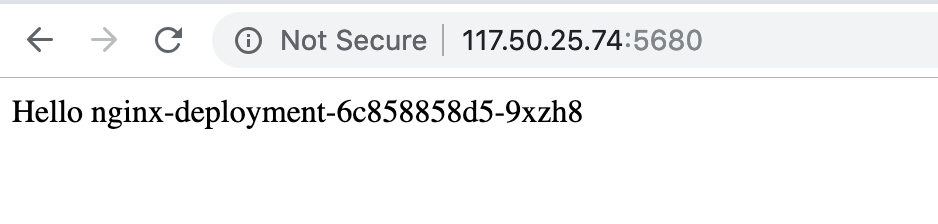
nginx-cluster LoadBalancer 172.17.153.144 117.50.25.74 5680:48227/TCP 19m
bash-4.4# kubectl get po -n elk -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-6c858858d5-7tcbx 1/1 Running 0 36m
nginx-deployment-6c858858d5-9xzh8 1/1 Running 0 36m
|
在之前部署 Filebeat 时,由于我们已经将/var/log/nginx/加入到 inputs.paths 中,Filebeat 已经可以对 nginx 的日志实现监控采集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
filebeat.modules:
- module: system
filebeat.inputs:
- type: log
paths:
- /var/log/containers/*.log
- /var/log/messages
- /var/log/nginx/*.log
- /var/log/*
symlinks: true
include_lines: ['hyperkube']
output.logstash:
hosts: ["elk-log-pipeline:5044"]
logging.level: info
index: filebeat-
|
转自https://docs.ucloud.cn/uk8s/log/elastic_filebeat_kibana_solution