Kubernetes 集群监控 kube-prometheus 自动发现
【Kubernetes】使用 kube-prometheus-stack 快速在 k8s 内搭建 Prometheus 全家桶
前言
最近因为需要做一些 redis-cluster-operator 的故障演练,新搭建了一个 k8s 集群,新的 k8s 集群需要搭建一套监控告警系统,对于 Prometheus,之前自己在虚拟机上练过手,比较麻烦,需要先后安装 Prometheus、Grafana、AlertManager,还需要修改各种配置,今天一想,现在都 2202 年了,肯定有更简单的方法,于是在社区找到了 kube-prometheus-stack
部署
GitHub 地址:https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
学习 k8s 监控涉及到
网上的教程大都不全或者有些旧,所以整理分享给小伙伴。
博文内容为 k8s 集群通过 helm 方式创建 kube-prometheus-stack 监控平台教程
折腾了一晚上,搞定了,一开始一直用 prometheus-operator 这个 chart 来装,报错各种找问题,后来才发现我的集群版本太高了,1.22 的版本,而且 prometheus-operator 之后的版本改变了名字 kube-prometheus-stack,旧的版本可能不兼容。
环境版本
我的 K8s 集群版本
helm 版本
1
2
3
4
5
|
~/workspace/tools/prometheus
zsh 🚀 helm version
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/xfhuang/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/xfhuang/.kube/config
version.BuildInfo{Version:"v3.10.0", GitCommit:"ce66412a723e4d89555dc67217607c6579ffcb21", GitTreeState:"clean", GoVersion:"go1.19.1"}
|
prometheus-operator(旧名字)安装出现的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
~/workspace/tools/prometheus
zsh 🚀 helm search repo prometheus-operator
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/xfhuang/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/xfhuang/.kube/config
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/prometheus-operator 9.3.2 0.38.1 DEPRECATED - This chart will be renamed. See ht...
~/workspace/tools/prometheus
zsh 🚀 helm install liruilong ali/prometheus-operator
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/xfhuang/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/xfhuang/.kube/config
Error: INSTALLATION FAILED: repo ali not found
~/workspace/tools/prometheus
zsh ❌ helm pull ali/prometheus-operator
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/xfhuang/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/xfhuang/.kube/config
Error: repo ali not found
~/workspace/tools/prometheus
zsh ❌
|
解决办法:新版本安装
直接下载 kube-prometheus-stack(新)的 chart 包,通过命令安装:
https://github.com/prometheus-community/helm-charts/releases/download/kube-prometheus-stack-30.0.1/kube-prometheus-stack-40.1.2.tgz
1
2
3
|
~/workspace/tools/prometheus
zsh ❌ ls
k8s-eggjs kube-prometheus-stack kube-prometheus-stack-40.1.2.tgz
|
解压 chart 包 kube-prometheus-stack-40.1.2.tgz
1
|
tar -zxf kube-prometheus-stack-40.1.2.tgz
|
创建新的命名空间
1
2
3
4
5
6
|
cd kube-prometheus-stack/
ls
kubectl create ns monitoring
kubectl config set-context $(kubectl config current-context) --namespace=monitoring
helm install hxf .
kubectl get pod -A
|

获取 grafa 的用户名和密码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
[root@k-116-m1 ~]# kubectl config set-context $(kubectl config current-context) --namespace=monitoring
Context "kubernetes-admin@cluster.local" modified.
[root@k-116-m1 ~]#
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o yaml -n monitoring
apiVersion: v1
data:
admin-password: cHJvbS1vcGVyYXRvcg==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
annotations:
meta.helm.sh/release-name: hxf
meta.helm.sh/release-namespace: monitoring
creationTimestamp: "2022-09-27T04:53:20Z"
labels:
app.kubernetes.io/instance: hxf
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 9.1.6
helm.sh/chart: grafana-6.38.7
name: hxf-grafana
namespace: monitoring
resourceVersion: "824220"
uid: a0154770-780d-400d-9974-0c98592216ce
type: Opaque
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o jsonpath='{.data.admin-user}}'| base64 -d
adminbase64: invalid input
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o jsonpath='{.data.admin-user}}'
YWRtaW4=}
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o jsonpath='{.data.admin-user}'
YWRtaW4=
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o jsonpath='{.data.admin-user}'| base64 -d
admin
[root@k-116-m1 ~]#
[root@k-116-m1 ~]# kubectl get secrets hxf-grafana -o jsonpath='{.data.admin-password}'| base64 -d
prom-operator
[root@k-116-m1 ~]#
|
得到用户名 admin 得到密码 prom-operator
修改配置
有一个需求,对于 k8s 内新创建的 pod,如果需要采集指标,希望可以自动添加到 prometheus 配置的 target 中,或者在需要手动添加采集目标时,不需要去 prometheus 的 pod 中修改的配置文件,单不说麻不麻烦,找到配置文件都比较繁琐。
基于这个需求,可以借助 additionalScrapeConfigs 来实现,这应该是 prometheus-operator 提供的能力,目的是通过维护一个外部的配置文件,来导入到 prometheus 内部的配置中。
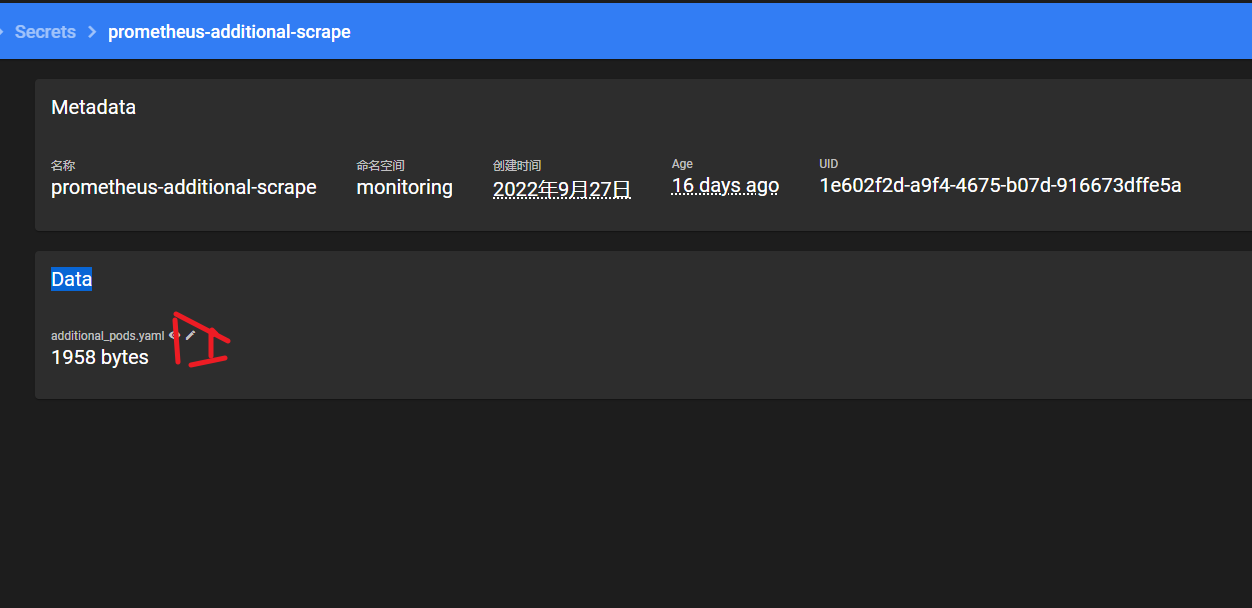
先以 Secret 的方式创建好一个配置文件:
1
2
3
4
5
6
7
8
|
kind: Secret
apiVersion: v1
metadata:
name: prometheus-additional-scrape
namespace: monitoring
data:
additional_pods.yaml: ''
type: Opaque
|
配置文件的内容先随便填,创建好之后,点击修改按钮:
 添加如下内容
添加如下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: "kubernetes-pod"
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels:
[__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
|
我们找到 prometheus 的定义文件,添加 additionalScrapeConfigs 相关配置:
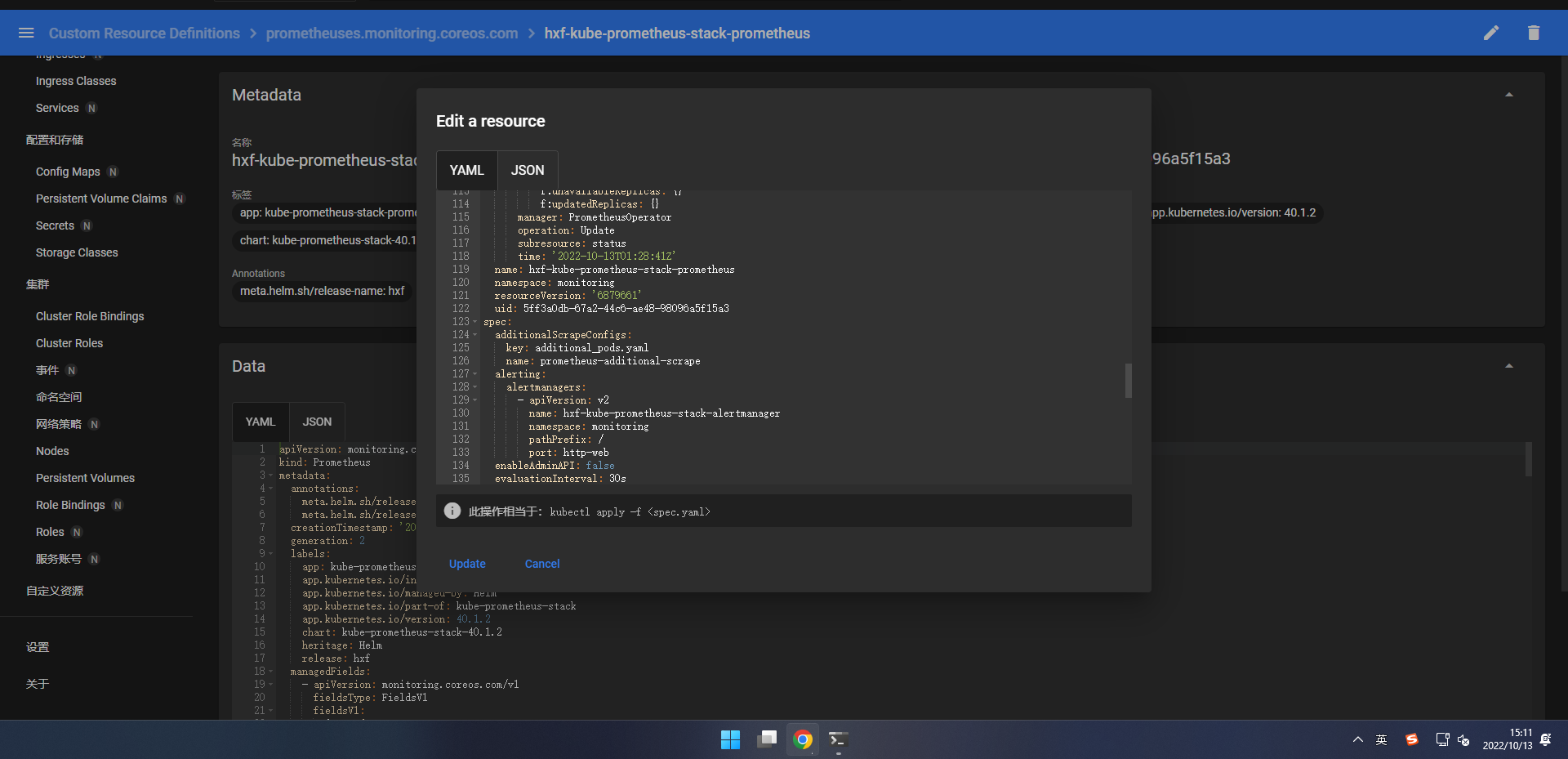 添加内容如下:
添加内容如下:
1
2
3
|
additionalScrapeConfigs:
key: additional_pods.yaml
name: prometheus-additional-scrape
|
需要和之前创建的 Secret 对应上。
此时通过页面查看 prometheus 的配置,发现这段配置已经加上去了
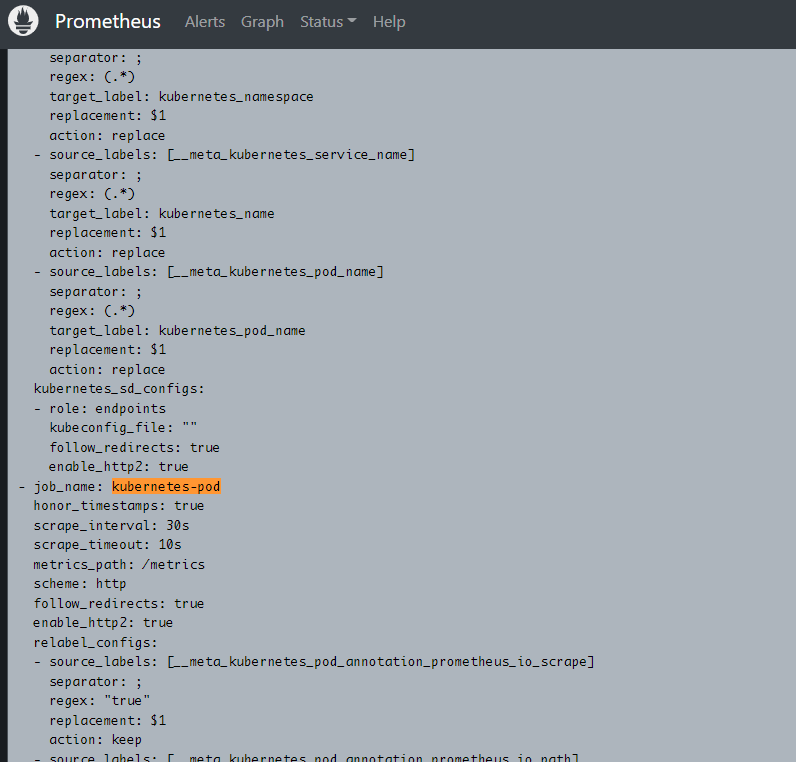
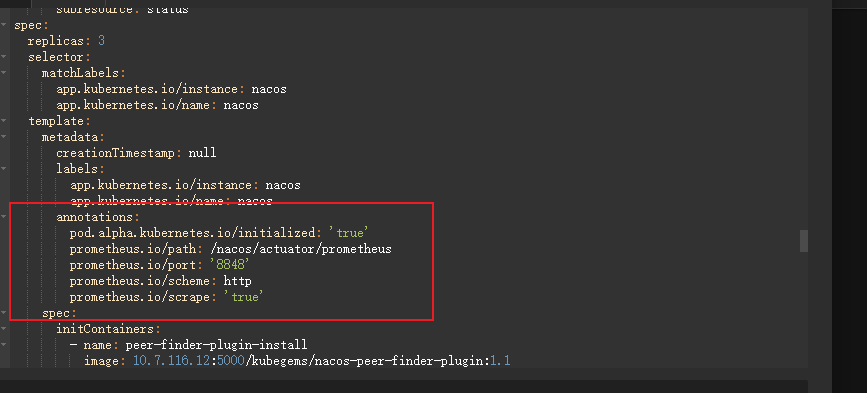
在需要被 prometheus 自动发现的 pod 上,只需要添加以下注解即可:
1
2
3
4
|
annotations:
prometheus.io/path: /metrics
prometheus.io/port: '9100'
prometheus.io/scrape: 'true'
|
 二、什么是服务发现?
我们在每个节点上面都运行了 node-exporter,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据,当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置,那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的「服务发现」功能。
二、什么是服务发现?
我们在每个节点上面都运行了 node-exporter,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据,当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置,那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的「服务发现」功能。
Prometheus 支持多种服务发现机制:文件、DNS、Consul、Kubernetes、OpenStack、EC2 等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus 查询到需要监控的 Target 列表,然后轮训这些 Target 获取监控数据,下面主要介绍 Kubernetes 服务发现机制。
目前,在 Kubernetes 下,Prometheus 通过与 Kubernetes API 集成主要支持 5 种服务发现模式:Node、Service、Pod、Endpoints、Ingress。不同的服务发现模式适用于不同的场景,例如:node 适用于与主机相关的监控资源,如节点中运行的 Kubernetes 组件状态、节点上运行的容器状态等;service 和 ingress 适用于通过黑盒监控的场景,如对服务的可用性以及服务质量的监控;endpoints 和 pod 均可用于获取 Pod 实例的监控数据,如监控用户或者管理员部署的支持 Prometheus 的应用。
关联 Promethues 与 ServiceMonitor
Prometheus 与 ServiceMonitor 之间的关联关系使用 serviceMonitorSelector 定义,在 Prometheus 中通过标签选择当前需要监控的 ServiceMonitor 对象。
修改 prometheus-inst.yaml 中 Prometheus 的定义如下所示: 为了能够让 Prometheus 关联到 ServiceMonitor,需要在 Pormtheus 定义中使用 serviceMonitorSelector,我们可以通过标签选择当前 Prometheus 需要监控的 ServiceMonitor 对象。修改 prometheus-inst.yaml 中 Prometheus 的定义如下所示: